

以下是 RAG 的典型工作流程:

由于附加文档可能很大,步骤 1 还涉及分块处理,即将大文档分割成更小/易于管理的小块。
此步骤至关重要,因为它确保文本符合 embedding 模型的输入大小。
以下是 RAG 的五种分块策略:
今天让我们来了解它们!
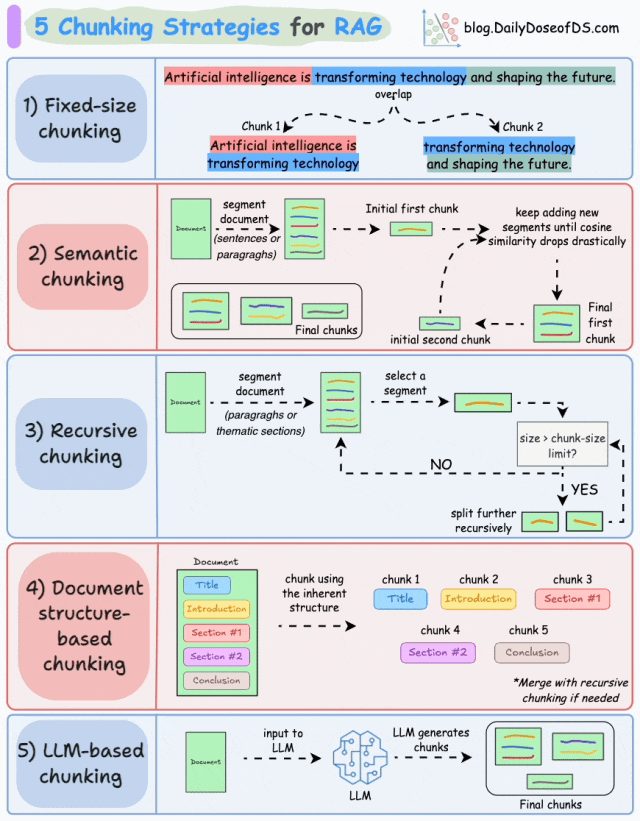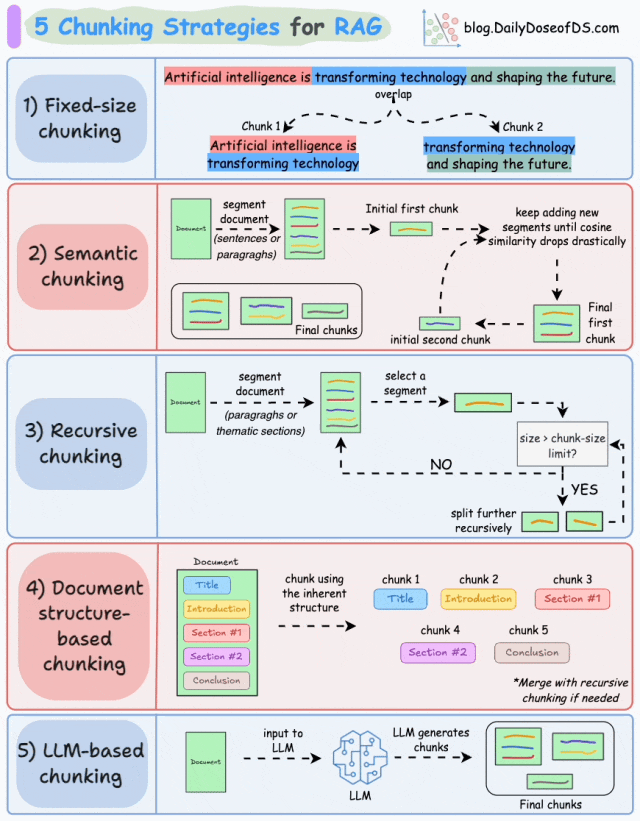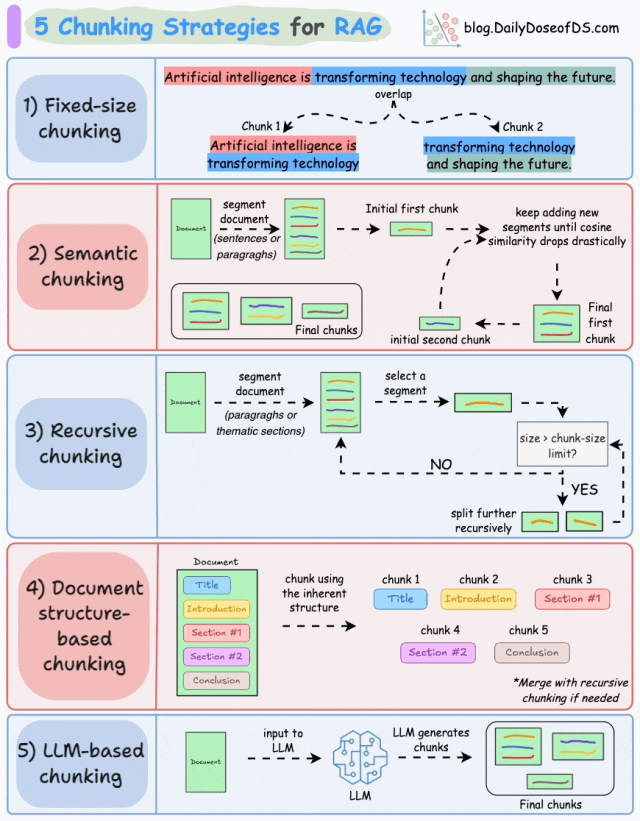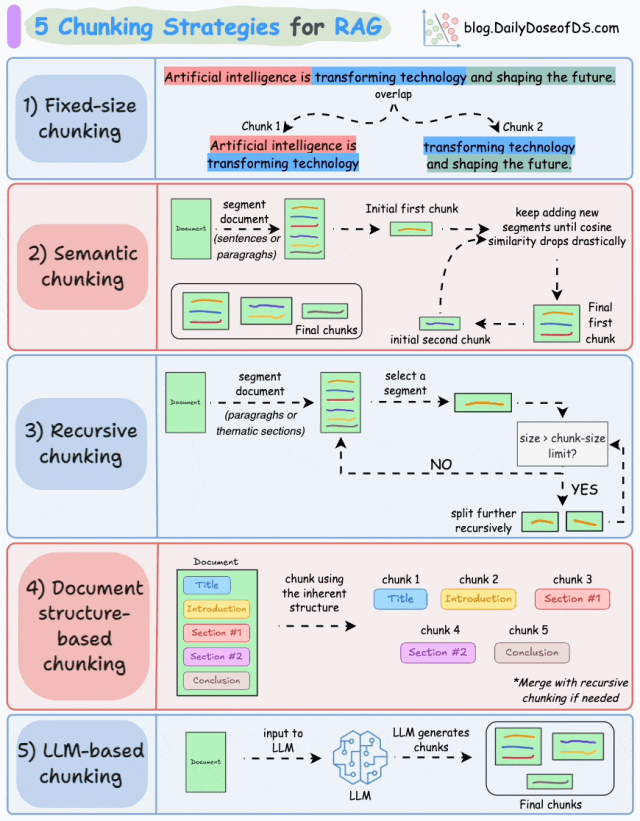
1.固定大小分块 (Fixed-size chunking)
基于预定义数量的字符、单词或 token 将文本分割成统一的片段。
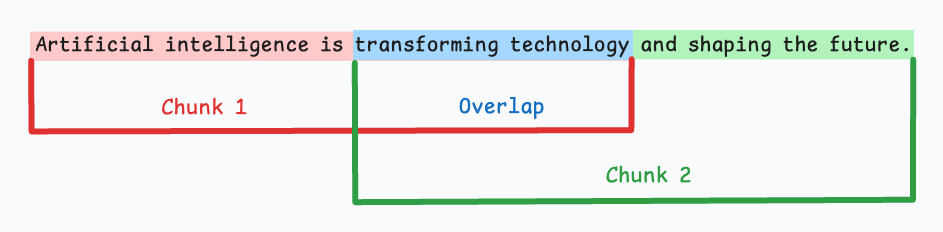
由于直接分割可能会破坏语义流,因此建议在两个连续的块之间保持一些重叠(上图中的蓝色部分)。
这种方法实现简单。此外,由于所有块大小相等,它简化了批处理。
但这种方法通常会中断句子(或观点)。因此,重要信息很可能会分散在不同的块中。
2.语义分块 (Semantic chunking)
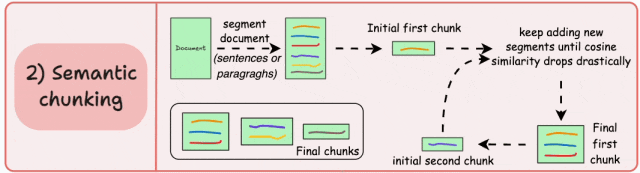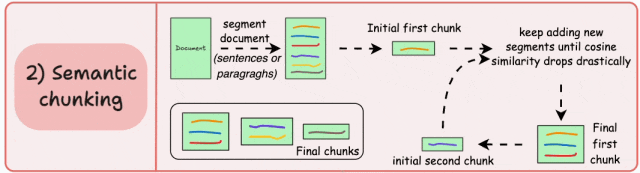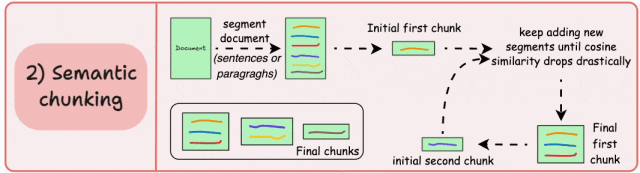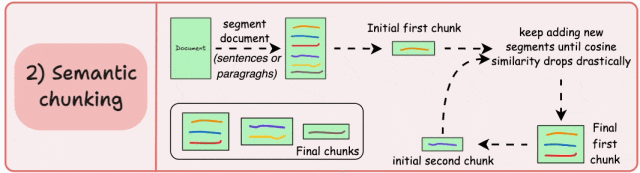
- 根据有意义的单元(如句子、段落或主题部分)对文档进行分段。
- 接下来,为每个片段创建 embedding。
- 假设我们从第一个片段及其 embedding 开始。
- 如果第一个片段的 embedding 与第二个片段的 embedding 具有高的余弦相似度,则这两个片段形成一个块。
- 这个过程一直持续到余弦相似度显著下降为止。
- 一旦相似度下降,我们就开始一个新的块并重复上述过程。
输出结果可能如下所示:

与固定大小分块不同,这种方法保持了语言的自然流畅性并保留了完整的思想。
由于每个块的内容更丰富,它提高了检索准确性,从而使 LLM 能够生成更连贯和相关的响应。
一个小问题是,它依赖于一个阈值来确定余弦相似度是否显著下降,这个阈值可能因文档而异。
3.递归分块 (Recursive chunking)
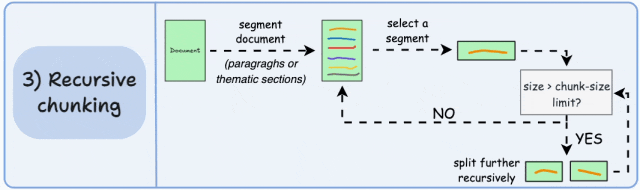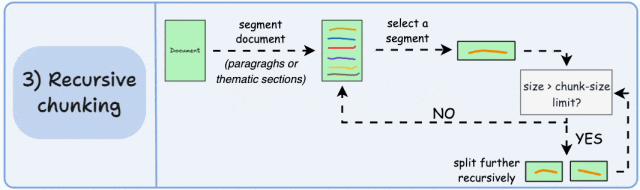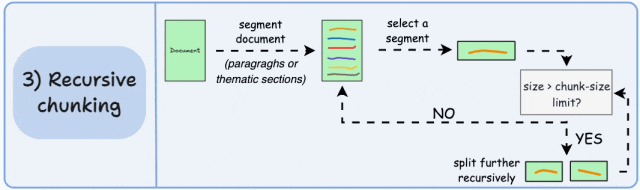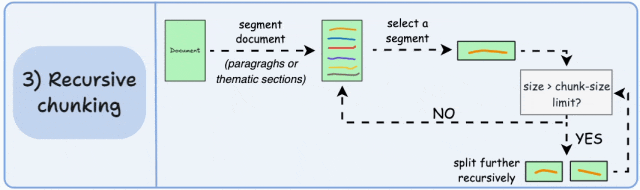
首先,根据段落或章节等固有分隔符进行分块。
接下来,如果块的大小超过预定义的分块大小限制,则将每个块分割成更小的块。但是,如果块符合分块大小限制,则不进行进一步分割。
输出结果如图所示:

如上所示:
- 首先,我们定义了两个块(紫色的两个段落)。
- 接下来,段落 1 被进一步分割成更小的块。
与固定大小分块不同,这种方法也保持了语言的自然流畅性并保留了完整的语义。
然而,在实现和计算复杂性方面存在一些额外的开销。
4. 基于文档结构的分块 (Document structure-based chunking)
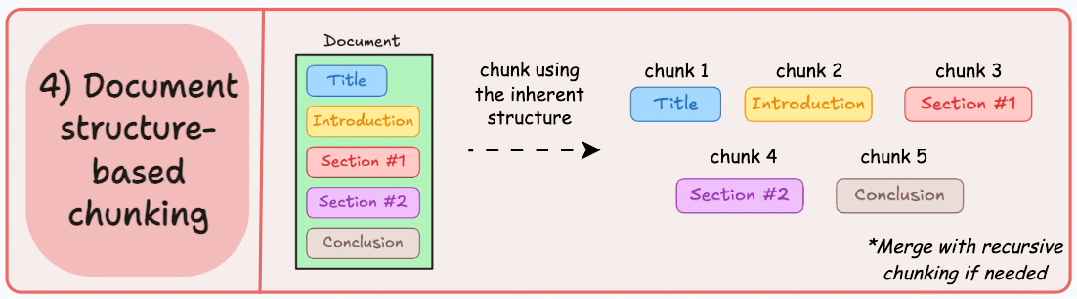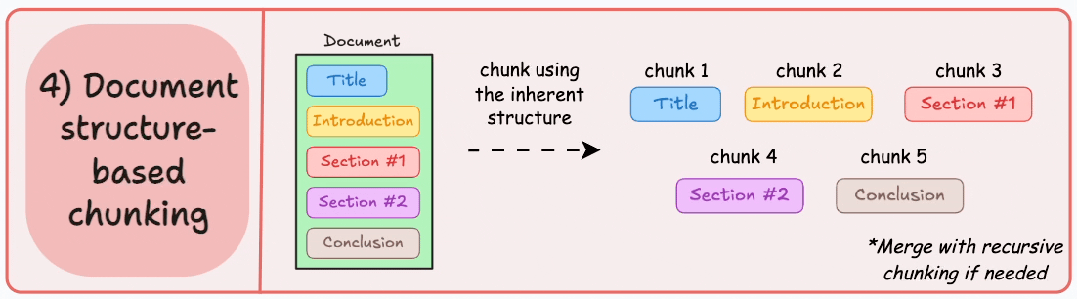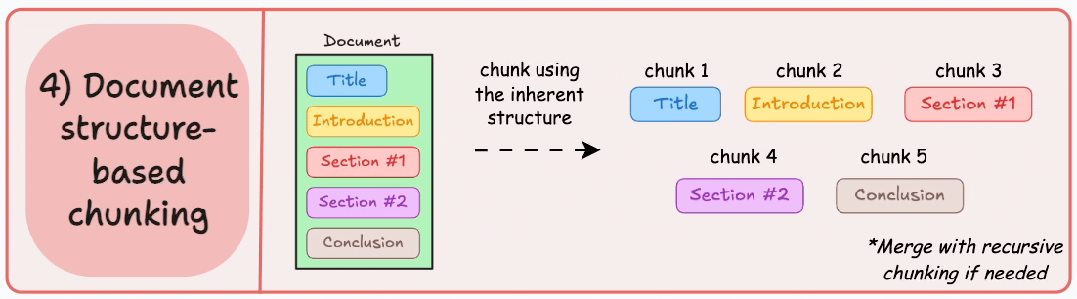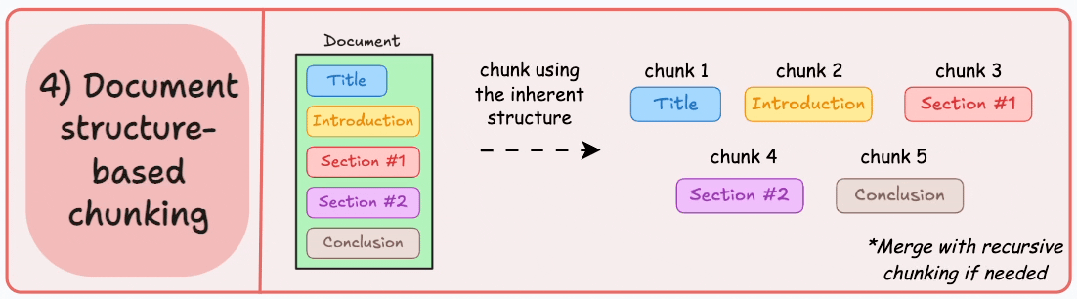
它利用文档的固有结构,如标题、章节或段落,来定义分块边界。通过这种方式,它与文档的逻辑部分对齐,从而保持结构完整性。
输出结果如图所示:

也就是说,这种方法假设文档具有清晰的结构,但这可能并非总是如此。
此外,块的长度可能会有所不同,可能会超出模型的 token 限制。可以尝试将其与递归分割相结合。
5.基于 LLM 的分块 (LLM-based chunking)

提示 LLM 生成语义上独立且有意义的块。
这种方法确保了高语义准确性,因为 LLM 能够理解上下文和含义,而不仅仅是依赖简单的启发式方法(如上述四种方法所采用的)。
但这也是这里讨论的所有五种技术中对计算需求最高的分块技术。
此外,由于 LLM 通常具有有限的上下文窗口,因此也需要注意这一点。
每种技术都有其自身的优点和权衡。
我们观察到语义分块在许多情况下效果很好,但同样,需要进行具体的测试。
选择将取决于内容性质、embedding 模型的能力、计算资源等。
? 轮到你了:你还知道其他哪些分块策略?
感谢阅读!
原文链接:https://blog.dailydoseofds.com/p/5-chunking-strategies-for-rag-f8b
