RAG 过时了吗?其实,这个说法只是针对简单向量检索在编程场景中的局限性。#RAG 的核心是为 LLM 提供合适的上下文,关键在于选择适合你应用的检索策略。
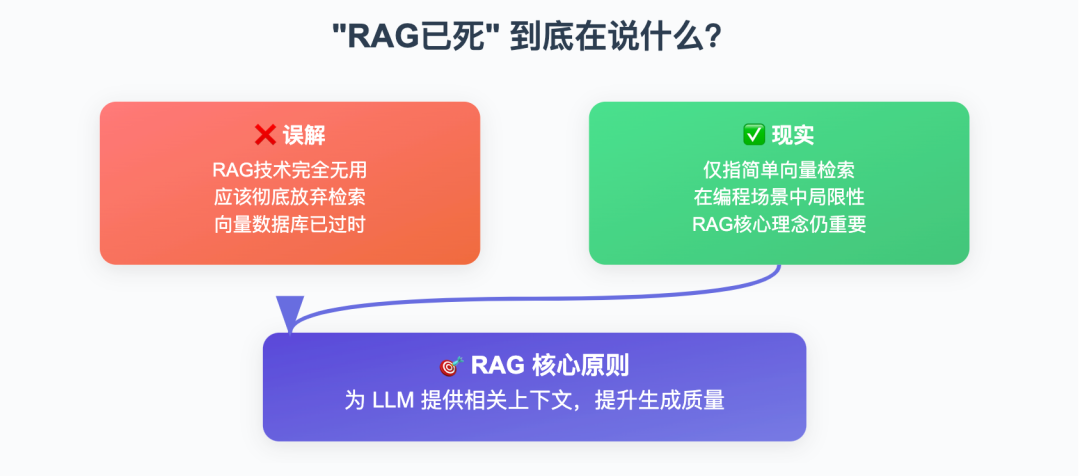
“RAG 已死”针对的是特定场景,不是全面否定 RAG
这里所谓的“RAG 已死”,主要是指在自主编程#智能体(coding Agents)中,单纯依赖向量数据库的检索方式效果有限,并不是说 RAG 整体无用。
RAG(#检索增强生成,Retrieval-Augmented Generation)的本质,是通过检索为 #LLM 提供相关上下文,帮助其生成更准确的回答,这一核心原则依然非常重要。
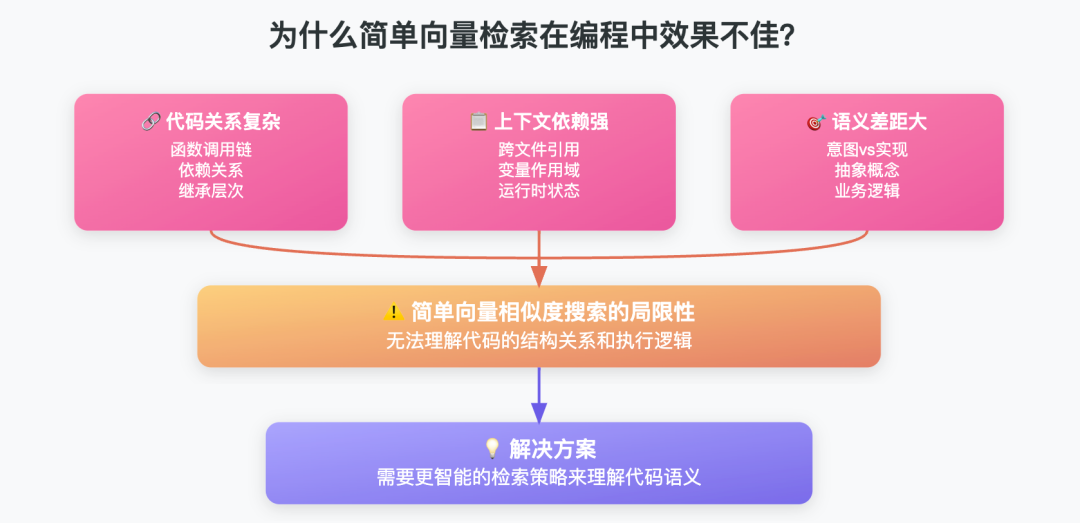
编程任务中,代码之间的关系复杂且高度依赖#上下文。单靠#向量相似性搜索,往往无法捕捉函数调用、依赖关系等深层次联系。
例如,理解代码时,可能需要跨文件追踪函数、变量的流转,简单的#向量检索 难以满足这种需求。
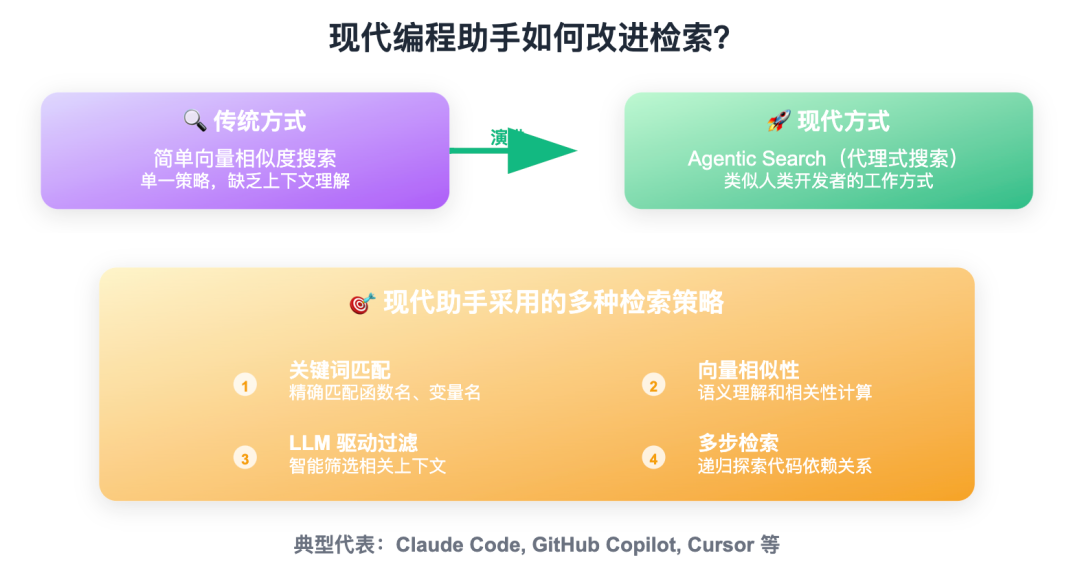
以 #Claude Code 等现代编码助手为例,它们依然采用检索,但方式更智能,采用类似人类开发者的 agentic search(#代理式搜索)。
这些工具通常结合多种检索策略,如#关键词匹配、#嵌入相似性、#LLM 驱动的上下文过滤等,提升检索的相关性和实用性。
“RAG”已经被炒作成一个模糊的流行词,有人认为它泛指所有#检索系统,有人则只指#向量数据库。
不要被术语本身迷惑,关键是为 LLM 选择合适的检索方式,确保其获得完成任务所需的正确#上下文。
不同的 AI 应用场景需要不同的检索策略,常见方式包括:
– 多步#检索(multi-hop retrieval)
具体选择应结合你的应用场景、数据特点和性能需求。建议:不要盲目追随“避免 RAG”或“拥抱 RAG”。针对你的应用,尝试多种检索方式,分析用户需求和失败模式,找到最适合的解决方案。