

导读:搞RAG开发,一个被普遍忽视却又至关重要的痛点是:如何避免Token分块带来的语义割裂问题。SAT模型通过神经网络驱动的智能分段技术,巧妙解决了这一难题。它不是RAG的替代,而是RAG的强力前置增强层,通过确保每个文本块的语义完整性,显著降低下游生成的幻觉风险。正如ContextGem文章中所提及的,高质量的输入是避免"垃圾进,垃圾出"的关键第一步。本文将深入剖析SAT如何重构文本分段技术,为您的Agent产品构建更可靠的文档理解基础。

在修猫上一篇介绍的《精准提取数据太折磨人,试下pip install -U contextgem》文章中,我们探讨了ContextGem这一强大的结构化数据提取框架,其核心技术支柱之一便是今天要深入剖析的SAT模型。作为ContextGem的"第一道防线",SAT不仅解决了"垃圾进,垃圾出"的根本问题,更为整个提取流程提供了坚实的语义基础。
正如昨天所提到的,SAT以其强大的神经网络能力,彻底改变了文档分析的基础工作。今天,我们将揭开SAT模型的技术面纱,来看看它是如何实现的,以及它可能对RAG和Agent开发带来的改进。
如果您还没有阅读昨天的文章,强烈建议先了解ContextGem的整体架构,再深入探索SAT这一核心引擎的工作原理。这是一个把SAT用于实践的经典框架,作者富有深刻的科学哲学洞察力,和“道与术”流派空谈不同,升华了这项研究,定义了这个框架,同时又超越了它。
文本分段:被忽视的性能瓶颈
当您忙于优化大语言模型和精细调整提示工程时,文本分段这个看似简单的预处理步骤很可能成为限制Agent产品性能的隐形天花板。
-
• 传统文本分段技术依赖简单规则和固定模式,无法有效应对真实世界文档的复杂性和多样性 -
• 这导致下游任务性能大幅下降,即使您使用最先进的大语言模型也无法弥补这一根本缺陷 -
• 文本分段并不仅仅是将文档切割成小块的机械过程,而是需要理解文档的语义结构、上下文关联和逻辑组织 -
• 这直接决定了后续提取、推理和生成任务的质量上限
特别是在构建依赖精确文档理解的Agent产品时,传统基于规则或简单统计的分段方法往往成为制约产品竞争力的关键瓶颈,而这一瓶颈恰恰被许多开发者所忽视。
? SAT与RAG:本质区别与协同价值
在深入了解SAT模型之前,我们需要厘清一个常见的误解:SAT与RAG(检索增强生成)之间的关系和区别。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SAT可以作为RAG的赋能工具
可以这么理解:SAT并非RAG的替代品,而是RAG系统的强大赋能工具和前置增强层。
在现代RAG架构中,SAT可以作为分块前处理器,为检索引擎提供更高质量的文本单元,从根本上提升检索质量。SAT的贡献在于它解决了"垃圾进垃圾出"的问题——无论您的嵌入模型、向量数据库和检索算法多么先进,如果输入的文本块本身就是语义破碎的,不可逆的误差累计导致最终检索和生成的质量必然受限。这个问题也是很多RAG生成幻觉的重要且隐蔽的原因之一。
通过SAT智能分段,RAG系统获得了更优质的语义单元,能够:
-
• 更准确地匹配用户查询意图 -
• 减少不相关结果 -
• 为大语言模型提供更连贯的上下文信息 -
• 显著提升最终生成内容的质量和准确性
? SAT模型:超越传统分段
SAT(Segment Any Text)模型突破性地将文本分段从简单的规则匹配提升到语义理解的高度,成为一种全新解决方案。
核心特点
-
• 基于Transformer架构:采用神经网络方法解决分段问题 -
• 多语言理解能力:在85种语言上进行训练 -
• 强大的适应性:不再依赖硬编码规则或特定语言假设 -
• 深层语义理解:通过学习文本的深层语义结构和上下文关系实现准确的段落识别和划分
实用优势
-
• 自动识别句子边界:将文本分割成语义完整的单位 -
• 不受格式限制:不依赖标点符号、换行符或特定格式 -
• 处理混乱文本:能处理各种格式混乱、标点不规范甚至缺失标点的文本 -
• 领域适应性:适应不同领域和风格的文档
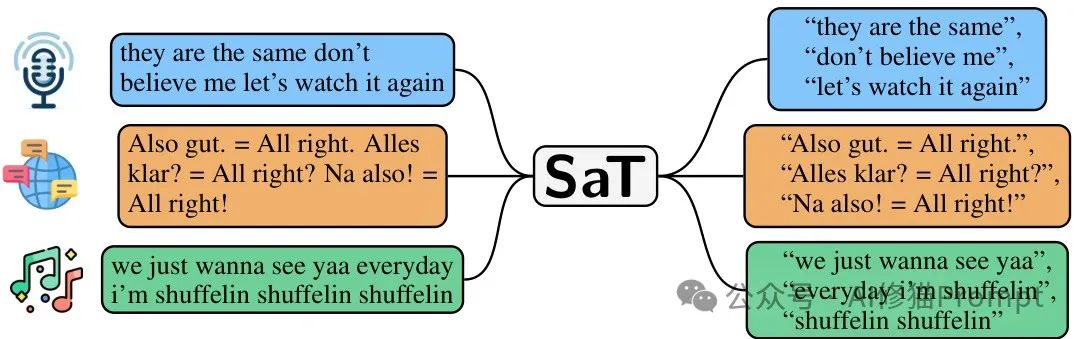
SAT模型在不同类型文本上的分段示例:(i)无标点ASR输出,(ii)多语言文本,(iii)歌词分段。SAT能够适应各种文本类型,不依赖标点符号或语言代码。
⚙️ SAT的核心:深度解析
SAT模型的技术核心在于其创新的神经网络架构和训练方法,远超传统NLP工具的能力边界。
先进架构设计
-
• 修改版XLM-R基础架构:通过双向上下文分析实现对句子边界的精确识别 -
• 有限前瞻机制(limited lookahead):使模型能够实时处理流式文本,同时保持高准确率和低延迟
创新训练方法
-
• 多样化语料库:包含各种文本类型和格式 -
• 数据增强技术:随机移除标点、改变大小写和模拟ASR输出等 -
• 辅助目标学习:识别标点符号与段落边界的关系,提升缺失标点情况下的分段性能
这种深度学习方法使SAT在语义理解层面超越了规则方法的局限,能够捕捉复杂的上下文依赖关系和跨语言通用特征。
? 多语言优化策略
SAT的多语言能力是其最显著的技术优势之一,为全球化Agent产品提供了坚实基础。
平衡训练策略
-
• 均匀采样方法:避免高资源语言主导训练过程 -
• 特殊处理机制:专门设计了处理不同书写系统(如泰语和日语)的特殊机制
语言特性适应
-
• 使用分隔符的语言:学习识别空格与句子边界的关系 -
• 不使用分隔符的语言:学习语义和语法特征 -
• 标点符号系统:识别各种语言特有的句子终止标志,如阿拉伯语的问号(؟)和中文的句号(。)
这种多语言适应性使SAT能在任何语言环境下为Agent提供一致的文档理解能力,无需为每种语言定制分段规则。

SAT在多语言文本分段上的性能对比。SAT+SM(监督混合)在14种代表性语言和81种语言平均性能上均优于传统方法和大型语言模型。
⚡ SAT模型的三大自适应机制
SAT模型设计了三种强大的适应机制,使其能够处理各种特殊文本类型和领域文档。
1️⃣ SAT+SM(监督混合)
-
• 模拟噪声数据:如ASR输出和社交媒体文本 -
• 增强鲁棒性:对非标准文本的处理能力 -
• 适用场景:缺失标点、不规范大小写和格式混乱的文本,特别适合处理语音转录和用户生成内容
2️⃣ SAT+LoRA
-
• 参数高效微调技术:通过少量领域数据快速适应特定文档类型 -
• 高效适应:只需几百个句子即可显著提升特定领域性能 -
• 保留能力:完全保留多语言能力 -
• 应用领域:法律文件、学术论文或技术报告
3️⃣ 代码混合处理
-
• 自动识别语言转换边界:无需明确指定语言代码 -
• 多语言混合文档:处理不同语言混合的文本表现出色
这三种适应机制使SAT成为真正通用的文本分段解决方案,能够满足不同Agent产品的多样化需求。
⚔️ 性能:SAT vs 传统分段方法
与传统分段方法相比,SAT模型在各种测试数据集上展现出压倒性优势。
准确性优势
-
• 标准文本:SAT平均F1分数比最先进的Moses、SpaCy和PySBD等规则方法高出10-15% -
• 挑战性文本:在无标点ASR输出、社交媒体文本和代码混合文本上,提升幅度达到20-30% -
• 法律文档:SAT+LoRA版本在不同语言和文档类型上均超越专门为法律文本优化的MultiLegalSBD系统 -
• 韵文分段:成功挑战复杂的歌词分段,准确识别歌曲的结构单元,超越基于LLM的方法
效率优势
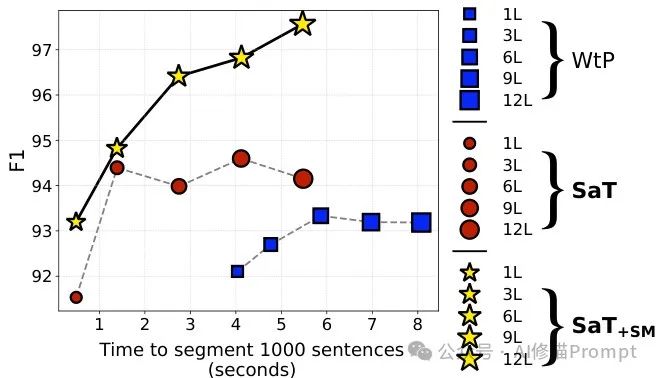
SAT模型与WTP(先前最先进模型)的F1得分和推理时间对比。实验结果显示,不同层数的SAT模型均优于WTP,特别是在效率方面,3层SAT模型处理1000个句子仅需约0.5秒,比WTP快约3倍。
-
• 推理速度:比传统方法快2-5倍,比大型语言模型快10-20倍 -
• 资源消耗:更低的内存占用和计算资源需求 -
• 实时处理:标准的3层版本在消费级硬件上处理1000个句子仅需约0.5秒 -
• 部署优势:可以在CPU环境中运行,无需专门的GPU加速,极大降低了生产部署的成本和门槛
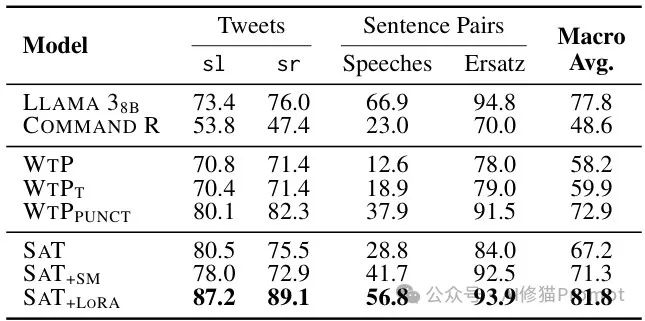
SAT在短文本和代码混合文本上的性能,展示了SAT在处理特殊文本类型时的优势,特别是在多语言混合场景中。
? SAT在Agent工作流中的位置
在实际Agent产品开发中,SAT可以作为文档理解层的核心组件,与大语言模型和知识库无缝集成。
应用场景
-
• RAG系统前置处理器:生成语义连贯的文档片段,显著提升检索质量和相关性 -
• Agent感知模块:帮助Agent正确理解文档结构,实现更精准的导航和定位 -
• 提取系统基础设施:确保结构化数据提取的准确性和完整性
技术集成
SAT可以与其他文档处理技术协同工作:
-
• OCR技术 -
• 表格检测 -
• 布局分析
这种集成方式使Agent产品能够处理更复杂的文档理解任务,扩展应用场景范围。
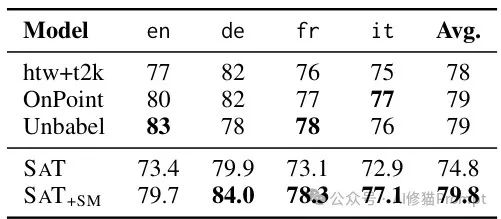
图5SAT在特定领域(ASR转录文本)的性能表现,与专门针对该任务优化的系统相比,SAT+SM仍然表现优秀。
? 实战指南:在Agent产品中整合SAT
将SAT模型整合到您的Agent产品中非常直接,可以通过开源框架如ContextGem或直接使用Hugging Face模型。
模型获取途径
-
• Hugging Face官方模型仓库:https://huggingface.co/segment-any-text -
• 提供多种不同规模的SAT模型版本(从1层到12层) -
• 包含基础模型和监督混合(SM)模型,适用于不同场景 -
• 所有模型支持多语言处理,便于全球化应用开发 -
• ContextGem框架:整合了SAT的全部功能,适合快速开发,默认是sat-3l,追求精度您可以用sat-6l,我在文章的优化准确性部分有提到。
快速集成步骤
-
1. 通过ContextGem安装SAT: pip install -U contextgem
-
2. 自动下载并加载SAT模型(约1GB大小),无需额外配置 -
3. 将SAT作为文档输入的第一道处理环节,为后续任务提供结构化文本
高级应用
-
• 领域适应:使用SAT的LoRA适应方法,通过几百个领域特定的句子样本快速调整模型 -
• 生产部署:支持批处理和并行推理,能够高效处理大量文档 -
• 低资源环境:可以在CPU环境中运行,降低了部署门槛
整合SAT通常能立即提升Agent的文档理解能力,无需改变现有提示或推理逻辑。
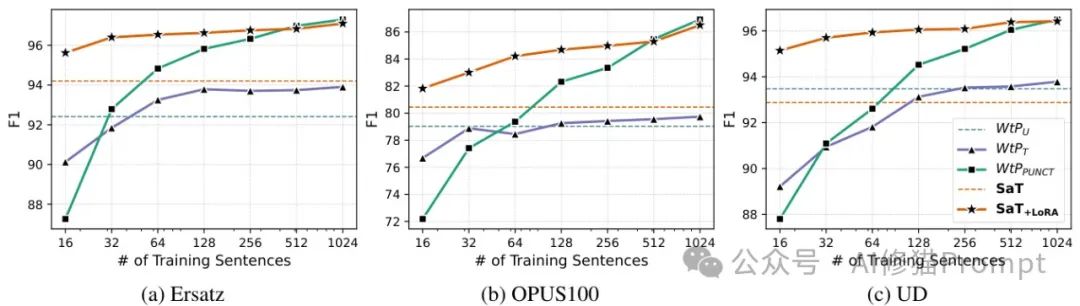
SAT的少样本适应能力展示。你敢想象吗?只需16个样本,SAT+LoRA就能有效适应新领域,比传统方法效率高得多。具体请您仔细阅读论文。
Agent时代的文档理解基石
SAT模型代表了文本处理技术从简单规则向语义理解的质的飞跃。
在Agent产品开发中,文档理解能力直接决定了产品的竞争力和应用边界,而SAT作为文档理解的基石,为构建真正智能的Agent提供了坚实基础。
