

公司年报智能问答比赛任务简介
比赛的任务是基于公司年度报告构建一个问答系统。简单来说,比赛当天的流程如下:
-
我们会收到来自随机挑选公司的 100 份年度报告,并需要在 2.5 小时内解析这些报告并构建一个数据库。这些报告是 PDF 格式,每份最长可达 1000 页。 -
然后,系统会生成 100 个随机问题(基于预设模板),我们的系统必须尽可能快速地回答这些问题。
所有问题都必须有确定的答案,例如:
-
是/否; -
公司名称(某些情况下是多个公司名称); -
领导职位头衔、推出的产品名称; -
数值指标:营收、商店数量等。
每个答案都必须注明引用的页码作为证据,确保系统是真正从原文中得出答案,而不是输出虚假信息(hallucinate)。
获胜方案
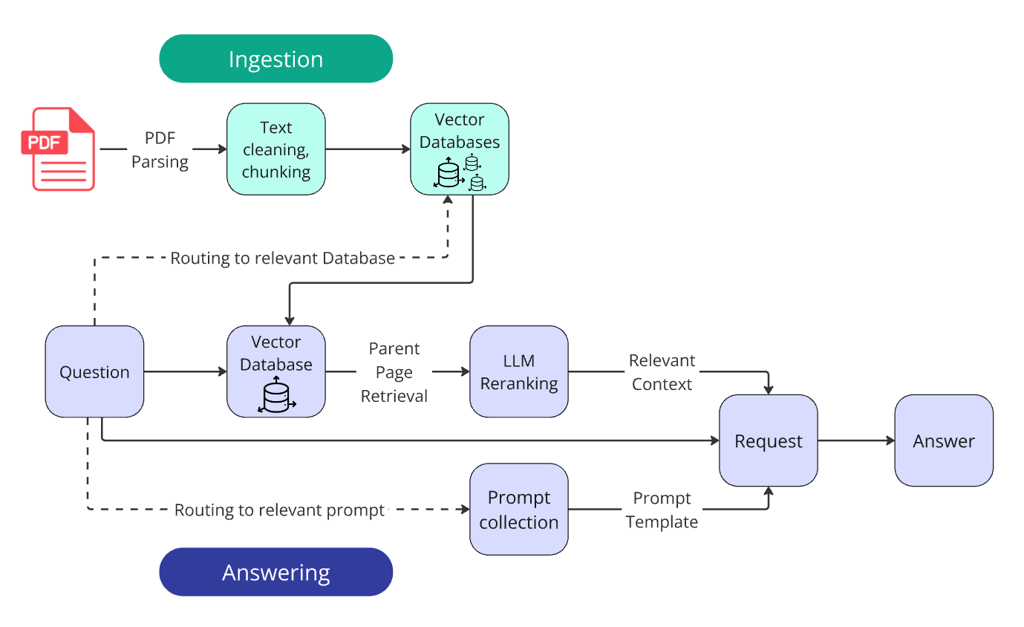 获胜方案在基础步骤之外,还加入了两个路由器(router)和 LLM 重排序模块(LLM reranking)。
获胜方案在基础步骤之外,还加入了两个路由器(router)和 LLM 重排序模块(LLM reranking)。
我们可以在这里查看我们的最佳系统生成的问答对:(https://github.com/IlyaRice/RAG-Challenge-2/blob/main/data/erc2_set/answers_1st_place_o3-mini.json)
接下来,我们将深入探讨构建该系统的每一个步骤,我们在过程中遇到的波折与困难,以及在此过程中摸索出的最佳实践。
RAG 快速指南
RAG(Retrieval-Augmented Generation,检索增强生成)是一种通过与任意大小的知识库结合,从而扩展大语言模型(LLM)能力的 方法。
基础 RAG系统的开发流程主要包含以下阶段:
-
解析 (Parsing):为知识库准备数据,包括收集文档、将其转换 为文本格式,并清理无关的噪点信息。 -
数据摄取 (Ingestion):创建并载入知识库。 -
检索 (Retrieval):构建一个工具,根据用户查询查找并返回相关 数据,通常在向量数据库中进行语义搜索。 -
回答 (Answering):使用检索到的数据丰富用户的提示词(prompt), 将其发送给 LLM,并返回最终答案。
1. 解析 (Parsing)
要开始填充任何数据库,首先必须将 PDF 文档转换为纯文本。PDF 解析是一项远非易事的工作,其中充满了无数细微的难题:
-
保留表格结构; -
保留关键的格式元素(例如标题和项目符号列表); -
识别多栏文本; -
处理图表、图片、公式、页眉/页脚等等。
遇到但没时间解决的有趣的 PDF 解析问题:
-
大型表格有时会旋转 90 度,导致解析器产生乱码或无法阅读的文本。
 * 图表 部分由图片、部分由文本层组成。
* 图表 部分由图片、部分由文本层组成。
-
有些文档存在字体编码问题:视觉上看文本是没问题的,但尝试复制或解析时会得到一堆乱七八糟的字符。 
有意思的是:我们单独调查了这个 问题,发现文本是可以解码的——它是一个凯撒密码(Caesar cipher),每个单词的 ASCII 位移量都不同。这让我们产生了许多疑問。如果有人故意加密了一份公开可查的公司报告以阻止复制——为什么?如果是在转换过程中字体出了问题——为什么偏偏是这种方式?
选择解析器
我们尝试了大约二十几种 PDF 解析器:
-
小众解析器; -
知名的解析器; -
基于前沿机器学习算法训练的解析器; -
支持 API 访问的商业解析器。
我们可以肯定地说,目前没有任何解析器可以处理所有细微之处,并在不丢失部分重要信息的情况下,将 PDF 内容完全还原为文本。
在 RAG 挑战赛中表现最好的解析器是相对知名的Docling。有趣的是,它的开发方是比赛的协办方之一——IBM。
文件解析优化
尽管 Docling 的结果非常优秀,但它缺乏一些基本能力。这些功能部分存在,但分散在不同的配置中,无法组合在一起。
因此,我们卷起袖子,彻底研究了库的源代码,并重写了几个方法以满足我们的需求,从而在解析后得到了一个包含所有必要元数据的 JSON 文件。利用这个 JSON, 我们构建了一个 Markdown 文档,其格式经过修正,并且表格结构从 PDF 转换为 Markdown 甚至 HTML(这在后来证明非常有用!)的还原度接近完美。
这个库相当快,但仍然不够快到能在 2.5 小时内在个人笔记本电脑上解析 1.5 万页文档。为了解决这个问题,我们利用了 GPU 加速解析,并在比赛期间租用了一台配备 4090 GPU 的虚拟机,每小时花费 70 美分。
解析所有 100份文档耗时约 40 分钟,根据其他参赛者的报告和评论,这 是极高的解析速度。
至此,我们的报告已被解析为 JSON 格式。
现在我们可以填充数据库了吗?
还没。首先,我们必须清除文本中的噪点信息,并对表格进行预处理。
文本清理和表格预处理
有时部分文本从 PDF 中解析出来时会出错,包含特定的语法,降低了可读性和意义。我们使用了一批十几个正则表达式来处理这个问题。
 解析不佳的文本示例
解析不佳的文本示例
之前提到的凯撒密码文档也通过正则表达式模式检测到了。我们试图解码它们,但即使修复后,它们仍然包含许多伪影(artifact)。因此,我们干脆直接对这些文档进行了完整的 OCR 识别。
表格序列化
在大型表格中,度量名称(横向表头)通常离纵向表头太远,削弱了语义连贯性。
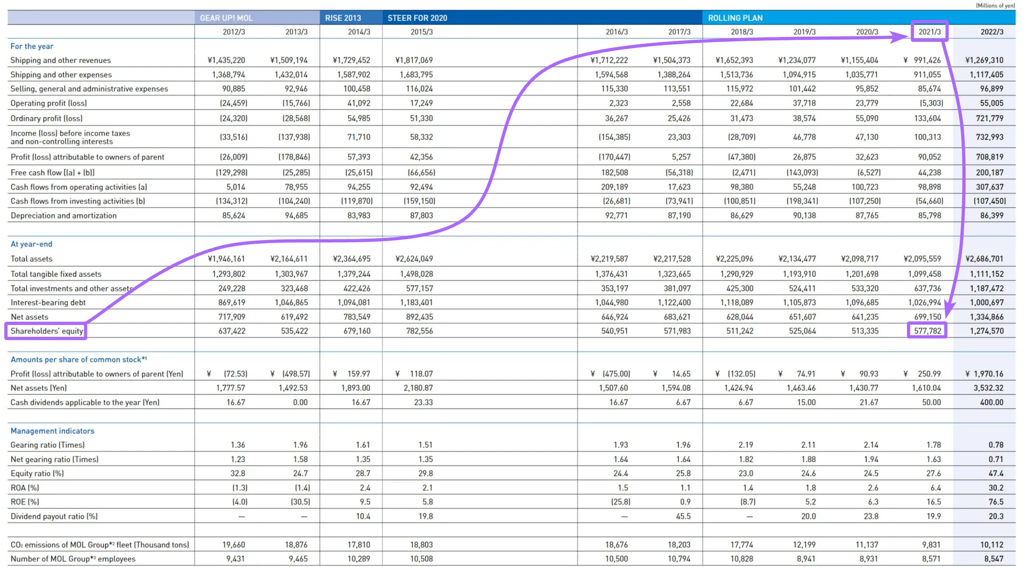 有 1500 个不相关的 token将纵向和横向表头隔开
有 1500 个不相关的 token将纵向和横向表头隔开
这显著降低了在向量搜索中 chunk 的相关性(更不用说表格完全装不进一个 chunk 的情况了)。此外,LLM 在处理大型表格时也很难将度量名称与表头对应起来,可能会返回错误的值。
表格序列化(Serialization of tables)成为了解决方案。关于这个主题的研究很少,所以我们不得不独立探索。我们可以搜索 Row-wise Serialization(行式序列化)、Attribute-Value Pairing(属性-值对匹配),或者阅读https://arxiv.org/pdf/2402.17944。
序列化的核心是将一个大表格转化为一系列小的、上下文独立的字符串。
在经过大量的提示词(prompts)和结构化输出 schema 实验后,我们发现了一种解决方案,即使是 GPT-4o-mini 也能几乎无损地序列化大型表格。最初,我们以Markdown 格式向 LLM 输入表格,但后来改用 HTML 格式(这就是它派上用场的地方!)。语言模型对 HTML 的理解程度要高得多,而且 HTML 可以描述包含合并单元格、子标题和其他复杂结构的表格。
要回答诸如“这家公司 2021 年的股东权益是多少?”之类的问题,只需向 LLM 输入一个句子,而非一个包含许多“噪点”的大型结构,这就足够了。
在序列化过程中,整个表格被转换成这样一组独立的块:
-
subject_core_entity:_Shareholders' equity(股东权益)_ -
information_block:_截至 2012/3 至 2022/3 年的股东权益如下:637,422 百万日元(2012/3),535,422 百万日元(2013/3),679,160 百万日元(2014/3),782,556 百万日元(2015/3),540,951 百万日元(2016/3),571,983 百万日元(2017/3),511,242 百万日元(2018/3),525,064 百万日元(2019/3),513,335 百万日元(2020/3),577,782 百万日元(2021/3),以及 1,274,570 百万日元(2022/3)。_
获得表格的序列化版本后,我们将其放在原表格下方,作为每一个元素的文本标注。
我们可以在项目的仓库中查看序列化的提示词和逻辑:tables_serialization.py
*尽管序列化潜力巨大,但获胜的解决方案最终并未采用它。我们将在文章末尾解释原因。
2. 内容提取 (Ingestion)
报告已从 PDF 转换为干净的 Markdown 文本。现在让我们用它们来创建数据库。
统一术语
在搜索系统領域(如 Google Search、全文搜索、Elastic Search、向量搜索等),一个文档 (document)是系统返回的单一索引元素作为查询结果。一个文档可以是一个句子、段落、页面、网站、图片——不重要。但就个人而言,这个定义总是让我们困惑,因为它有一个更常用、更日常的含义:文档 (document)作为一份报告、合同或证书。
因此,从现在起,我们将使用文档在其日常含义上。
存储在数据库中的元素,我们称之为**块 (chunk)**,因为我们存储的只是被切分过的文本片段。
分块 (Chunking)
根据比赛规则,我们必须指明包含相关信息的页码。企业系统也采用同样的方法:引用允许验证模型的答案是否是虚假信息(hallucinated)。
这不仅使系统对用户更透明,也简化了开发过程中的调试。
最简单的选择是将文档的整页作为一个块,因为页面很少超过几千个 token(尽管表格序列化可能会将 એક頁的 token 数擴展 до 五千)。
但让我们再次思考查询和文档文本块之间的语义连贯性。通常情况下,足以回答问题的信息片段不超过十个句子。
因此,从逻辑上讲,一个包含目标语句的小段落将比同样语句稀释在一整页相关性较弱的文本中获得更高的相似度得分。
我们将每页的文本分割成 300 个 token(约 15 个句子)的块。
为了切分文本,我们使用了带有自定义 Markdown 词典的递归拆分器。为了避免信息在两个块之间被切断而丢失,我们添加了一个小的文本重叠(50 个 token)。如果我们担心重叠不能完全消除切分不当带来的风险,可以搜索一下“语义拆分器 (Semantic splitter)”。如果我们计划只将找到的块插入到上下文中,这一点尤其重要。
然而,切分的精确度对我们的检索系统几乎没有影响。
每个块都存储其 ID 及其在元数据(metadata)中的父页面编号。
向量化 (Vectorization)
我们的块集合已准备就绪;现在让我们创建向量数据库——或者更确切地说,是多个数据库。100 个数据库,其中 1 个数据库 = 1 个文档。
因为为什么要 将所有公司的信息混合在一起,之后再试图将一个公司的收入与另一个公司分开呢?答案的目标信息总是严格限制在单个文档内。
我们只需根据给定的问题确定要查询哪个数据库(稍后会详细介绍)。
为了创建、存储和搜索向量数据库,我们使用了FAISS。
关于向量数据库格式的一些说明
数据库使用IndexFlatIP方法创建。
Flat 索引的优点是所有向量都“原样”存储,没有压缩或量化。搜索使用暴力搜索,精度更高。缺点是这种搜索计算和内存消耗显著更高。
如果我们的数据库至少有十万个元素,可以考虑 IVFFlat 或 HNSW。这些格式速度快得多(尽管创建数据库时需要稍多一些资源)。但速度的提升是以牺牲精度为代价的,因为它使用的是近似最近邻搜索(ANN)。
将所有文档的块分离到不同的索引中,我们得以使用 Flat 数据库。
IP(内积)用于通过余弦相似度计算相关性得分。除了 IP,还有 L2——它通过欧氏距离计算相关性得分。IP 通常能提供更好的相关性评分。
为了将块和查询嵌入到向量表示中,我们使用了text-embedding-3-large。
3. 检索 (Retrieval)
创建好数据库后,是时候进入 RAG 系统的“R”(检索)部分了。
检索器(Retriever)是一个通用的搜索系统,它接收查询作为输入,并返回包含回答所需信息的 相关文本。
在基础实现中,它只是对向量数据库发起查询,提取 Top N 个结果。
这是 RAG 系统中尤其关键的部分:如果 LLM 在查询上下文中没有接收到必要信息,它就无法提供正确答案——无论我们如何精心微调解析或回答提示词。
"垃圾进 → 垃圾出(Junk in → Junk out)。"
提高检索器质量的方法有很多。以下是我们在比赛期间探索过的方法:
混合搜索
vDB + BM25混合搜索(Hybrid search)结合了基于向量的语义搜索和传统的基于关键词的文本搜索( BM25 算法)。理论上,它通过不仅考虑文本含义,还考虑精确关键词匹配来提高检索准确性。通常,两种方法的搜索结果会合并并根据综合得分进行重排序。
我们并不是特别喜欢这种方法:在它的基础实现中,它通常会降低检索质量而不是提高。
总的来说,混合搜索是一個不錯的技術,通過修改輸入查詢可以進一步優化。最簡單地說,LLM 可以重述問題以去除噪點並增加關鍵詞密度。
如果我们在混合搜索方面有积极的经验,特别是关于潜在问题和解决方案,请在评论区分享。
无论如何,我们心中有更具前景的替代方案,于是決定不再进一步探索这个方向。
交叉编码器重排序 (Cross-encoder reranking)
使用交叉编码器模型(Cross-encoder models)对向量搜索结果进行重排序看起来很有前景。简单来说,交叉编码器能给出更精确的相似度分數,但速度较慢。
交叉编码器介于嵌入模型(例如双编码器 bi-encoder)和 LLM 之间。与通过文本的向量表示(这 inherently 会丢失一些信息)进行比较不同,交叉编码器直接评估两个文本之间的语义相似度,从而给出更准确的分数。
然而,对查询与数据库中每个元素的成对比较耗时太长。
因此,交叉编码器重排序仅适用于 벡터 검색 đã 过滤出一小部分块。
在比赛的最后一刻,我们放弃了这种方法,原因是通过API 提供的交叉编码器重排序模型稀缺。无论是 OpenAI 还是其他大型提供商都没有提供,而我们不想为了管理另一个 API 余额而麻烦。
但如果我们有兴趣尝试交叉编码器重排序,我们推荐Jina Reranker。它在基准测试中表现出色,而且注册后 Jina 会提供慷慨的免费请求额度。
最终,我们选择了更具吸引力的替代方案:LLM 重排序!
LLM 重排序 (LLM reranking)
这很简单:将文本和问题传递给 LLM,并问:“这段文本有助于回答问题吗?有多大帮助?它的相关性评分从 0 到 1 是多少?”
直到最近,由于强大的 LLM 模型成本高昂,这种方法还不可行。但现在我们有了快速、廉价且足够智能的 LLM 模型。
和交叉编码器重排序一样,我们也在通过向量搜索初步过滤后应用此方法。
我们开发了一个详细的提示词,描述了通用指导和精确到 0.1 的显式相关性标准:
-
0 =完全不相关:文本块与查询没有任何联系或关联。 -
0.1 = 基本不相关:仅与查询有非常轻微或模糊的关联。 -
0.2 = 非常微弱相关:包含极其微小或切线式的关联。 -
…
LLM 查询被格式化为结构化输出(Structured output),包含两个字段:reasoning(让模型解释其判断)和relevance_score,可以直接从 JSON 中提取,无需额外解析。
我们进一步优化了流程,在一个请求中同时发送三页内容,提示 LLM 同时返回三个页面的分数。这提高了速度,降低了成本, 并因相邻文本块能为模型的评估提供更多上下文而略微提高了评分的一致性。
修正后的相关性得分使用加权平均计算:
vector_weight = 0.3,llm_weight = 0.7理论上,我们可以直接跳过向量搜索,将每一页都直接传递给 LLM。有些参赛者就这样做了,而且取得了成功。然而,我们相信使用嵌入(embedding)进行更便宜、更快速的过滤仍然是必要的。对于一份 1000 页的文档(有些文档就是这么大),仅仅回答一个问题就可能花费约 25 美分——太昂贵了。
而且,归根结底,我们是在参加一场 RAG 挑战赛,不是吗?
通过 GPT-4o-mini 进行重排序的成本对我们来说每个问题不到一美分!这种方法在质量、速度和成本之间取得了出色的平衡——这正是我们选择它的原因。
我们可以在这里查看重排序提示词:prompts.py
父页面检索 (Parent Page Retrieval)
还记得我们之前提到将文本分割成更小的块吗?好吧,这里有一个小但重要的注意事项。
是的,回答问题的核心信息通常集中在一个小的块中——这正是将文本分解成小块能提高检索质量的原因。
但该页上剩余的文本可能仍然包含次要的——但仍然重要——的细节。
因此,在找到 Top N 个相关块后,我们只将它们用作指向整个页面的指针;然后将完整的页面添加到上下文(context)中。这正是我们在每个块的元数据中记录页面编号的原因。
整合后的检索器 (Assembled Retriever)
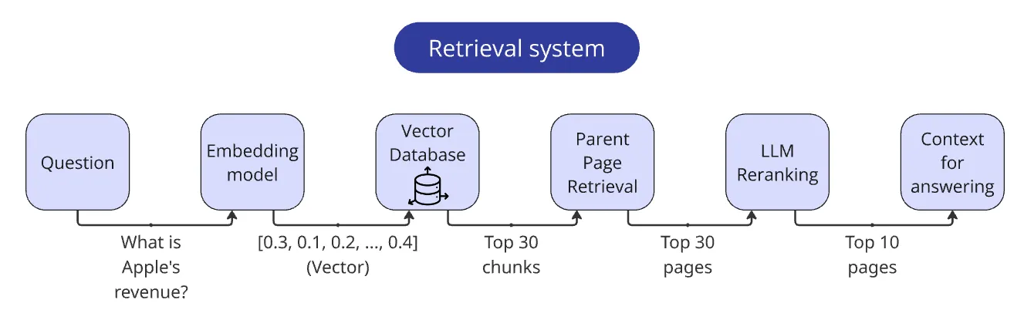
让我们回顾一下最终检索器的步骤:
-
对查询进行向量化。 -
根据查询向量找到 Top 30 个相关块。 3.通过块的元数据提取对应的页面(记得去重!)。 -
通过 LLM 重排序器处理这些页面。 -
调整页面的相关性得分。 -
返回得分最高的 Top 10 页,在每一页前面加上页码,并将它们合并成一个字符串。
我们的检索器现在准备就绪了!
4. 增强 (Augmentation)
我们的向量数据库已建立,检索器已准备好。RAG 系统中的“R”(检索)部分至此已完成,我们现在进入“A”(增强)部分,这部分相当直接,主要包括 f-string 和字符串拼接操作。
一个有趣的地方是我们组织提示词存储的方式。在多个项目中尝试了不同的方法后,我们最终确定了以下方法:
我们将提示词存储在一个专门的prompts.py文件中,通常将提示词分割成逻辑块:
-
核心系统指令; -
定义 LLM 返回响应格式的 Pydantic schema; -
用于创建单次示例(one-shot)/少次示例(few-shot)提示词的问答对示例; -
用于插入上下文和查询的模板。
一个小型函数会根据需要将这些块组合成最终的提示词配置。这种方法允许灵活测试不同的提示词配置(例如,比较不同示例对单次示例提示词的有效性)。
某些指令可能会在多个提示词中重复出现。以前,修改这类指令意味着需要在所有使用它们的提示词中同步更新,这很容易导致错误。模块化方法解决了这个问题。现在,我们将重复出现的指令放入一个共享块中,并在多个提示词中重用。此外,当提示词变得过长时,模块化块也简化了处理。
所有提示词都可以在项目仓库中查看:prompts.py
5. 生成 (Generation)
RAG 中的第三个部分“G”(生成)是最耗费精力的。要在这一阶段实现高质量,需要巧妙地应用几种基本技术。
将查询路由到数据库
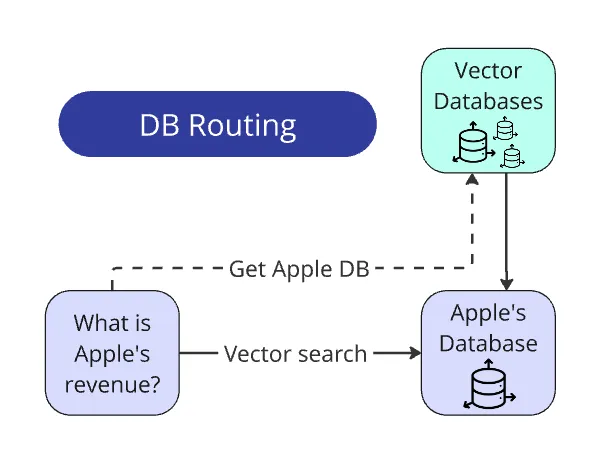 这是 RAG 系统中最简单却最有用的部分之一。
这是 RAG 系统中最简单却最有用的部分之一。
回想一下,每份报告都有其独立的向量数据库。问题生成器设计成公司名称始终明确出现在问题中。
我们也有所有公司名称的列表(比赛开始时与 PDF 报告一同提供)。因此,从查询中提取公司名称甚至不需要 LLM:我们只需遍历列表,通过re.search()从问题中提取名称,并将其与相应的数据库匹配。
在实际应用场景中,将查询路由到数据库比在我们受控、理想的环境中更复杂。我们很可能还会需要额外的预处理任务:为数据库打标签,或者使用 LLM 从问题中提取实体,然后将其与数据库匹配。但在概念上,方法保持不变。
总结一下:
找到公司名称 → 匹配到相应的向量数据库 → 只在该数据库中搜索。搜索空间缩小了 100 倍。
将查询路由到提示词
比赛的一个要求是回答的格式。每个答案必须简洁,并严格符合数据类型,就像直接将其存入公司数据库一样。
每个问题旁边都明確給出了预期的数据类型——int/float、bool、str或list[str]。
每种类型都涉及 3到 6 个需要在回答时考虑的细微之处。
例如,如果问题询问某个指标的数值,答案必须是纯数字,不包含评论、货币符号等。对于金钱指标,报告中的货币必须与问题中提到的货币一致,并且数字必须规范化——例如报告中常写“$1352 (in thousands)”,系统必须回覆“1352000”。
如何确保 LLM 同时考虑所有这些细微之处而不出错?简单地说:我们做不到。给 LLM 的规则越多,它忽视它们的可能性就越高。即使只有八条规则,对当前的 LLM 来说也多得危险。模型的认知能力是有限的,额外的规则会分散其回答核心问题的注意力。
这逻辑上得出了一个结论:我们应该尽量减少每个查询的规则数量。一个方法是将一个查询分解为一系列更简单的查詢。
然而,在我们的案例中,由于明确提供了预期的响应类型,我们可以实现一个更简单的解决方案——根据不同的答案类型,我们們只向提示詞提供相应的指令集。
我们编写了四种提示词变体,並使用简单的if else语句选择正确的那个。
复合查询路由
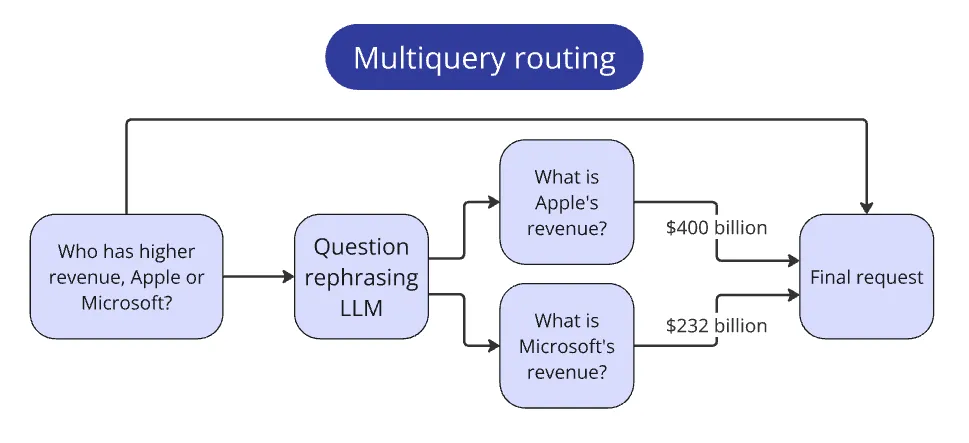
比赛还包括比较多家公司指标的问题。这类问题与那些更简单的查询不符,因为它们需要额外的步骤来回答。
问题示例:
苹果和微软谁的营收更高?
我们想想:人会如何處理这个任务?
首先,他们會分别查找每家公司的营收,然后进行比较。
我们将同样的思维嵌入到我们的系统中。
我们将最初的比较问题传递给 LLM,并要求它创建更简单的子问题,以分别提取每家公司的指标。
在我们的例子中,更简单的子问题将是:
苹果的营收是多少?和微软的营收是多少?
现在我们可以通过标准流程分别处理每家公司的这些更简单的查询。收集到每家公司的答案后,我们将它们作为上下文传递给 LLM,以回答最初的问题。
这种模式适用于任何复杂的查询。关键在于识别它们并确定所需的子步骤。
思维链 (Chain of Thoughts, CoT)
思维链(CoT)通过让模型在给出最终答案之前“出声思考”,显著提高了答案质量。LLM 不会立即给出答案,而是生成一系列导致解决方案的中间推理步骤。
就像人类一样,LLM 在将复杂問題分解為更小、更簡單的問題時,處理得更好。CoT 幫助模型避免遗漏关键细节,有条不紊地處理信息,并得出正确结论。在上下文包含可能误导模型的“陷阱”时,它尤其有用。
我们无疑听说过那句标志性的话:一步步思考 (Think step by step)。这是最早试图通过提示词(prompting)来提高答案质量的尝试之一。它实际上催生了奇特的“提示词工程(prompt engineering)”。然而,对于严肃的任务,这种通用指令是不够的。
LLM 有时会“虚假推理(fake reasoning)”——例如,先给出即时答案,然后倒过来找理由解释,或者编造不存在的事实。这个问题在像 GPT-4o-mini 或 Llama 8b 这样较弱的模型中尤为常见。
为了确保CoT 有益,我们必须清晰地引导模型如何进行推理。解釋推理步驟、目標,并提供示例。
根据提示词指令明确地构建推理步骤,可以显著增强规则的遵循。
在 RAG 中,当报告中缺乏完全符合要求的指标时,上下文可能包含相似但不完全相同的信息。模型可能會試圖扭曲提供的数据以符合请求的指标。由于模型被训练得乐于助人,它们偏向于提供某个答案而不是承认不知道。
仅仅要求模型保持怀疑态度来对抗这种偏见确实有效——但并非始终如一,也并非在所有情况下都有效。相反,明确提示模型从不同角度或视角分析信息会更有帮助。
我们特別指示模型重点评估问题和上下文之间指标的兼容性。这显著减少了虚假信息的生成。
带有模糊上下文的推理示例:
问题:
Ritter Pharmaceuticals Inc. 的研发设备(按成本计)是多少?
模型的推理步骤:
-
问题询问 Ritter Pharmaceuticals Inc. 的“研发设备,按成本计”。这表明需要从资产负债表中提取一个特定数值,代表专门用于研发的设备的原始购置成本,不包含任何累计折旧。 -
上下文(第 35 页)显示“不动产和设备,净额”为 12,500 美元。这是一个净值(已扣除折旧),而且是一个更广泛的类别,包含所有不动产和设备,而不仅仅是研发设备。 -
上下文(第 37 页)还提到“机械和设备”的“累计折旧”为 110,000 美元。这代表了总的折旧,而不是原始成本,更重要的是,它没有说明这些设备专门用于研发。 -
这两个指标都不完全符合请求的指标。“不动产和设备,净额”范围太广,且是折旧后的价值。“累计折旧”仅显示折旧,而非成本,并且缺乏研发的针对性。5. 由于上下文没有提供仅用于研发设备的原始成本,且我们無法進行假設、計算或組合信息,因此答案是“N/A”。
结构化输出 (Structured outputs)
结构化输出(Structured Output,SO)是一种强制模型以严格定义的格式响应的方式。它通常作为一个单独的参数传递给 API,例如一个 Pydantic 或 JSON schema(模式)。
这保证了模型总是返回符合所提供 schema 的有效JSON 数据。
字段描述也可以包含在响应 schema 中。这些不影响结构,但会被 LLM 视为提示词的一部分来处理。
例如,以下是用于 LLM 重排序的 Pydantic schema:
class RetrievalRankingSingleBlock(BaseModel):
"""Rank retrieved text block relevance to a query."""
reasoning: str = Field(
description=(
"Analysis of the block, identifying key information and how it ""relates to the query"
)
)
relevance_score: float = Field(
description=(
"Relevance score from 0 to 1, where 0 is Completely Irrelevant "
"and 1 is Perfectly Relevant"
)
)有了这个 schema,LLM 总是会返回一个包含两个字段的 JSON——第一个是字符串,第二个是数字。
CoT SO (思维链结合结构化输出)
上述方法可以理想地结合使用。
在生成阶段,模型有一个专门用于推理的字段,还有一个单独的字段用于最终答案。这使得我们可以直接提取答案,而无需从冗长的推理步骤中进行解析。
可以在结构化输出中以多种方式实现思维链。例如,您可以使用多个 JSON 字段,每个字段引导模型得出中间结论,这些结论的组合最终引导它得出正确的最终答案。
然而,由于回答比赛问题所需的逻辑无法通过预定义的一组 分步指令来描述,我们采用了更通用的方法,为模型提供一个单一的推理字段,并直接在提示词中定义推理序列。
在我们用于回答比赛问题的主要schema 中,只有四个字段:
-
step_by_step_analysis——初步推理(思维链本身)。 -
reasoning_summary——前一个字段的精简摘要(用于更轻松地跟踪模型的逻辑)。 -
relevant_pages——答案引用的报告页码。 -
final_answer——根据比赛要求格式化后的简洁答案。
前三个字段在为不同答案类型量身定制的四种提示词中被重用。第四个字段每次都有所不同,指定答案类型并描述模型必須 Consideration 的具體細微之處。
例如,确保final_answer字段始终是数字或“N/A”是这样实现的:
final_answer: Union[float, int, Literal['N/A']]
SO 重解析器 (SO Reparser)
并非所有 LLM 都支持结构化输出,因为只有它才能保证完全遵守 schema。
如果一个模型没有专门的结构化输出功能,我们仍然可以直接在提示词中呈现输出 schema。在大多数情况下,模型通常足够智能,可以返回有效的 JSON。然而,部分答案不可避免地会偏离 schema,导致代码出错。小型模型尤其如此,大约一半的时间都无法符合要求。
为了解决这个问题,我们编写了一个回退方法,它使用schema.model_validate(answer)来验证模型的响应是否符合 schema。如果验证失败,该方法会将响应重新发送给 LLM,提示它遵守 schema。
这种方法将 schema 合规率提高到 100%,即使对于 8b 模型也是如此。
这是提示词本身。
单次示例提示词 (One-shot Prompts)
这是另一种常见且相当显而易见的方法:在提示词中添加一个问答示例对,可以提高响应质量和一致性。
我们在每个提示词中都添加了一对“问题 → 答案”,答案以结构化输出定义的 JSON 格式编写。
这个示例同时服务于多种目的:
-
展示一个示例性的分步推理过程。 -
进一步阐明在困难情况下的正确行为(帮助重新校准模型的偏见)。 -
演示模型回答应该遵循的 JSON 结构(尤其对缺乏原生 SO 支持的模型有用)。
我们非常重视精心编写这些示例答案。提示词中示例的质量可以提升或降低响应质量,因此每个示例必须与指令完全一致,并且总体上几乎无懈可击。如果示例答案与指令矛盾,模型就会变得困惑,这会对其表现产生负面影响。
我们仔细地修改了示例中的分步推理字段,手动调整了推理结构和每个短语的措辞。
指令细化 (Instruction Refinement)
这一部分的工作量与整个数据准备阶段不相上下,因为需要进行无止境的迭代调试、校对答案以及手动分析模型的推理过程。
分析问题
在编写提示词之前,我们徹底研究了响应要求和问题生成器。
构建一个以 LLM 为核心的优秀系统的关键在于理解客户需求。通常,这需要深入的专业领域知識和对问题的细致检查。我们坚信,除非我们清晰地理解问题本身以及如何找到答案,否则不可能为企业构建真正高质量的问答系统(如果有人能说服我们,我们会很高兴)。
这种理解也是澄清用户问题中所有隐含意义所必需的。
让我们考虑问题示例:**ACME inc 的 CEO 是谁?**
在一个理想的世界里,报告总是会明确地提供答案,不留误解 的余地:
现由 John Doe 负责 CEO 职责
RAG 系统会在报告中找到这句话,将其添加到查询上下文,用户会收到一个明确的答案:John Doe
然而,我们生活在现实世界中,成千上万的公司以各种方式表达信息,伴随着无数额外的细微之处。
这就引出了一个问题:到底什么可以归入“CEO”这个称谓之下?
-
系统应该多么字面地理解客户的问题? -
客户是想知道担任类似管理角色的人的名字,还是严格来说就是那个特定的职位头衔? -
稍微偏离字面解释是否可以接受?偏离多远算太远?
潜在地,以下职位可能被包括在内:
-
首席执行官 (Chief Executive Officer)——显然就是 CEO 的全称。 -
董事总经理 (Managing Director, MD), 总裁 (President), 执行董事 (Executive Director)——稍不那么明显。不同国家对这个角色使用不同的头衔(英国和欧洲是 MD,美国和日本是 President,英国、亚洲国家以及非营利组织是 Executive Director)。 -
首席运营官 (Chief Operating Officer), 首席执行官 (Principal Executive Officer), 总经理 (General Manager), 行政长官 (Administrative Officer), 代表董事 (Representative Director)——甚至更不明显。根据国家和公司结构的不同,可能没有直接等同于 CEO 的职位;尽管这些角色最接近 CEO,但它们在职责和权限上的重叠程度各不相同——从 90% 到 50% 不等。
我们不确定是否存在对此已有的术语,但我们个人将其称为“解释自由度阈值”问题。
当响应是自由格式时,解释自由度阈值相对容易解决。在模棱两可的情况下,LLM 会尝试涵盖用户查询中所有隐含的含义,并添加一些澄清。
这是一个真实示例的 ChatGPT 回复:
根据提供的上下文,Ethan Caldwell是董事总经理,这是该公司中最接近 CEO 的职位。但是,由于正在进行的监管调查,他已被正式暂停了积极的行政职责。虽然他保留了头衔,但目前不参与公司运营,领导权已暂时移交给董事会监督下的高级管理团队。
然而,如果系统架构要求简洁的答案,就像 RAG 挑战赛这样,模型在这些情况下表现就不稳定了,依赖其内部的“直觉”。
因此,解释自由度阈值必须提前定义和校准。但由于无法明确定义和量化这个阈值,必须识别所有主要的边缘情况,制定通用的查询解释规则,并与客户澄清模糊之处。
除了理解问题外,还可能出现一些普遍的困境。
例如:ACME inc 是否宣布了股息政策的任何变更?
系统是否应该将报告中缺乏信息解读为没有宣布任何变更?
Rinat(比赛组织者)可以证实——在比赛准备期间,我们用几十个类似的问题和困境轰炸了他 🙂
提示词创建 (Prompt Creation)
比赛开始前一周,问题生成器的代码公开了。 मैं तुरंत 生成了 一百个问题,并从中创建了一个验证集。
手动回答问题相当繁琐,但这在两个关键领域帮助了我们:
-
当我们进行改进时,验证集可以客观地衡量系统的质量。通过在该集合上运行系统,我们可以监控它正确回答了多少问题以及最常在哪里出错。这种反馈循环有助于迭代改进提示词和其他流水线组件。 -
手动分析问题突出了问题和报告中不明显的细节和歧义。这让我们能与 Rinat 核实回答要求,并将这些规则明确地反映在提示词中。
我们将所有这些澄清纳入提示词中作为指令集。
指令示例:
答案类型 = 数字
如果提供的指标与问题中提到的货币不同,则返回“N/A”。如果上下文没有直接说明指标(即使可以从上下文中的其他指标計算得出),则返回“N/A”。特别注意上下文是否提到指标是以单位、千或百万为单位报告的,以便在最終答案中相应地调整数字,不作任何更改、添加三个零或六个零。注意值是否用括号括起来;这意味着该值为负数。
答案类型 = 名称
如果问题询问职位(例如职位的变动),则仅返回职位头衔,不包括姓名或任何其他信息。任命新的领导职位也應算作职位的变动。如果提到与同一头衔的职位相关的几次变动,只返回该职位头衔一次。职位头衔始终应使用单数形式。
如果问题询问新推出的产品,则仅返回上下文中的产品名称,完全按照原文。新产品候选者或测试阶段的产品不应计为新推出的产品。
模型很容易遵循某些指令,由于固有的偏见而抗拒其他指令,并且在某些指令上遇到了困难,导致错误。例如,模型在跟踪计量单位(千、百万)时反复出错,忘记在最终答案中添加必要的零。于是,我们在指令中补充了一个简短的示例:
千为单位的数字示例:
上下文中的值:
4970,5 (in thousands $)最终答案:
4970500
最终,我们为每种问题格式编写了提示词,并编写了几个辅助提示词:
-
数字类型问题最终提示词 -
名称类型问题最终提示词 -
名称列表类型问题最终提示词 -
布尔类型问题最终提示词 -
比较类型问题最终提示词(用于通过多查询路由比较多个公司的答案) -
比较类型问题的复述提示词(用于初步在报告中查找指标) -
LLM 重排序提示词 -
SO 重解析器提示词对指令的细致优化结合单次示例和结构化输出思维链,带来了显著的好处。最终的提示词彻底改变了系统中不必要的偏见,并极大地提高了对细微之处的关注度,即使对于较弱的模型也是如此。
系统速度
最初,RAG 挑战赛的规则更严格,要求系统在 10 分钟内回答所有 100 个问题,才有资格获得奖金。我们认真对待这项要求,并力求充分利用 OpenAI 的每分钟 token 限制。
即使在 Tier 2,限额也很慷慨——GPT-4o-mini 每分钟 2 百万 token,GPT-4o 每分钟 45万 token。我们估算了每个问题的 token 消耗量,并分批处理 25 个问题。系统仅用了 2 分钟就完成了所有 100 个问题。
最后,提交解决方案的时间被大大延长了——其他参赛者根本无法及时完成 🙂
系统质量
拥有一个验证集不仅帮助改进了提示词,也使整个系统受益。
我们将所有关键功能配置化,以便衡量它们的实际效果并微调超参数。以下是一些示例配置字段:
class RunConfig:
use_serialized_tables: bool = False
parent_document_retrieval: bool = False
use_vector_dbs: bool = True
use_bm25_db: bool = False
llm_reranking: bool = False
llm_reranking_sample_size: int = 30top_n_retrieval: int = 10
api_provider: str = "openai"
answering_model: str = "gpt-4o-mini-2024-07-18"
在测试不同配置时,我们惊讶地发现我们对它寄予厚望的表格序列化功能不仅没有改进系统,反而略微降低了其有效性。显然,Docling 从PDF 解析表格的能力足够好,检索器也能有效地找到它们,而 LLM 在没有额外帮助的情况下也能充分理解它们的结构。而向页面添加更多文本只会降低信噪比。
我们还为比赛准备了多种配置,以便在所有类别中快速运行各种系统。
最终系统在使用开源模型和商业模型时都表现出色:Llama 3.3 70b 的得分仅比 OpenAI 的 o3-mini 低几个点。 even 微小的 Llama 8b 在总榜上都超过了 80% 的参赛者。
6. 结论
最终,赢得 RAG 挑战赛并非因为找到了某个神奇的解决方案,而是因为采取了系统化的方法,深思熟虑地结合和微调了各种技术,并深入钻研了任务细节。关键的成功因素包括高质量的解析、高效的检索、智能的路由,以及——最值得一提的——LLM 重排序和精心设计的提示词,这些使得即使使用紧凑的模型也能取得出色的结果。
这场比赛的主要启示很简单:RAG 的魔力在于细节。我们越了解任务,就能越精确地微调每个流水线组件,从最简单的技术中也能获得更大的收益。
作者已将所有系统代码开源。其中包括如何自行部署系统和运行流水线任意阶段的说明。
