

-
安装DSPy:需要python3.9及以上版本,这里我们从git工程地址下载所需的版本:
conda create —name py39 python=3.9conda activate py39pip install git+https://github.com/stanfordnlp/dspy.git@2.5.29
-
本地部署LM模型:这里选择llama3.2,安装Ollama并运行LM服务:
curl -fsSL <https://ollama.ai/install.sh> | shollama run llama3.2
-
测试一下环境是否OK:import dspy llama32 = dspy.LM('ollama_chat/llama3.2', api_base='http://localhost:11434', api_key='') dspy.configure(lm=llama32)
在DSPy中可以直接通过 lm(prompt="prompt") 或 lm(messages=[...]) 来提示语言模型。然而,DSPy 提供了模块作为定义语言模型函数的更好方式。
最简单的模块是 dspy.Predict。它需要一个 DSPy 签名,即结构化的输入/输出模式,并为你指定的行为返回一个可调用函数。DSPy使用“内联”符号为签名声明一个模块,该模块将问题(类型为 str)作为输入,并生成响应作为输出。
qa = dspy.Predict('question: str -> response: str')response = qa(question="what are high memory and low memory on linux?")print(response.response)
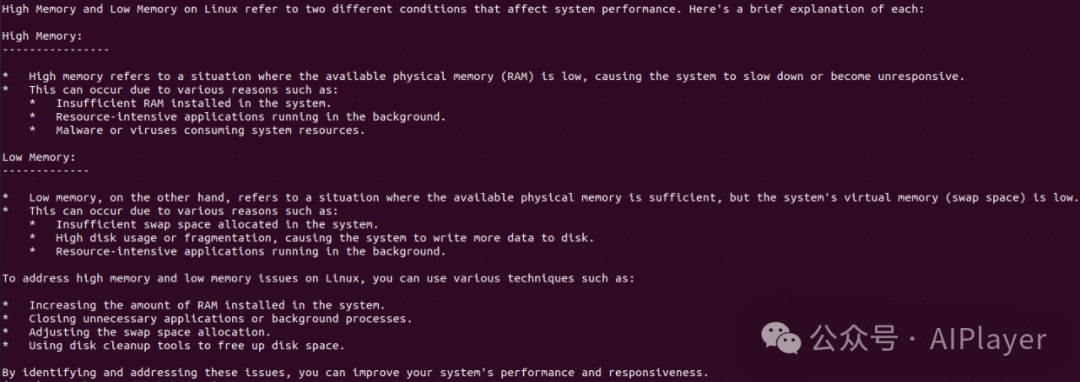
print(dspy.inspect_history(n=1))
[2025-01-10T11:06:24.275829]System message:Your input fields are:1. `question` (str)Your output fields are:1. `response` (str)All interactions will be structured in the following way, with the appropriate values filled in.[[ ## question ## ]]{question}[[ ## response ## ]]{response}[[ ## completed ## ]]In adhering to this structure, your objective is:Given the fields `question`, produce the fields `response`.User message:[[ ## question ## ]]what are high memory and low memory on linux?Respond with the corresponding output fields, starting with the field `[[ ## response ## ]]`, and then ending with the marker for `[[ ## completed ## ]]`.Response:[[ ## response ## ]]High Memory and Low Memory on Linux refer to two different conditions that affect system performance. Here's a brief explanation of each:省略[[ ## completed ## ]]
使用DSPy 的基本功能其实已经可以快速地实现很多功能,而如果想构建一个高质量的系统并随着时间的推移不断改进,则需要通过评估系统的质量并利用 DSPy 的强大工具(如优化器)快速迭代。要衡量 DSPy 系统的质量,通常需要:
-
输入样本:例如问答对的问题样本,需要加载一个包含问题及其标准答案的数据集。 -
输出质量评分指标:指标种类繁多,有些指标需要理想输出的真实标签,例如用于分类或问答,其他指标是自监督的,例如检查忠实度或缺乏幻觉。对于问答任务,评估回答质量的优劣往往可以通过衡量:系统响应在多大程度上涵盖了标准答案中的所有关键事实,或者反过来:系统响应在多大程度上没有说出标准答案中没有的内容。这个指标本质上是“语义 F1”,因此可以从 DSPy 中加载一个 SemanticF1 指标,然后使用 dspy.Evaluate计算平均得分。
下面的示例是在Colab上使用DSPy构建一个回答技术问题的 RAG 系统。输入样本从 RAG-QA Arena 数据集中获取了一些基于 StackExchange 的问题及其正确答案,并使用SemanticF1作为评估指标:
!apt-get install -y pciutils lshw!curl -fsSL https://ollama.ai/install.sh | sh!pip install dspy!pip install faiss-cpu
import osimport threadingimport subprocessimport requestsimport jsonimport timedef ollama(): os.environ['OLLAMA_HOST'] = '0.0.0.0:11434' os.environ['OLLAMA_ORIGINS'] = '*' subprocess.Popen(["ollama", "serve"]) time.sleep(10)ollama_thread = threading.Thread(target=ollama)ollama_thread.start()def llama_run(): subprocess.Popen(["ollama", "pull", "llama3.2"])llama_run_thread = threading.Thread(target=llama_run)llama_run_thread.start()检查是否已经启动成功
!curl http://localhost:11434/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "llama3.2","messages": [{"role": "user", "content": "Hello"}]}'
{"id":"chatcmpl-676","object":"chat.completion","created":1745216425,"model":"llama3.2","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"Hello! How can I assist you today?"},"finish_reason":"stop"}],"usage":{"prompt_tokens":26,"completion_tokens":10,"total_tokens":36}}
import dspyimport ujsonfrom dspy.utils import downloadimport randomfrom dspy.evaluate import SemanticF1from sentence_transformers import SentenceTransformer# 使用本地部署的Llama3.2模型(通过Ollama服务),支持自定义API端点lm = dspy.LM('ollama_chat/llama3.2', api_base='http://localhost:11434', api_key='')dspy.configure(lm=lm)# 从Hugging Face下载RAG-QA Arena技术问答数据集,转换为DSPy的Example格式,# 支持输入字段question的自动解析download("https://huggingface.co/dspy/cache/resolve/main/ragqa_arena_tech_examples.jsonl")with open("ragqa_arena_tech_examples.jsonl") as f: data = [ujson.loads(line) for line in f]data = [dspy.Example(**d).with_inputs('question') for d in data]# 数据集划分,通过随机打乱后划分训练集(20条)、开发集(20条)和测试集(500条),用于后续优化与评估。random.Random(0).shuffle(data)trainset, devset, testset = data[:20], data[200:220], data[500:1000]print(f'{len(trainset)}, {len(devset)}, {len(testset)}')# 初始化评估器(SemanticF1指标)metric = SemanticF1(decompositional=True)evaluate = dspy.Evaluate(devset=devset, metric=metric, num_threads=12, display_progress=True, display_table=2)# 从Hugging Face下载RAG-QA Arena技术问答精简数据集download("https://huggingface.co/dspy/cache/resolve/main/ragqa_arena_tech_corpus.jsonl")# 加载技术文档语料库,截断超过6000字符的文档并添加省略号max_characters = 6000 # 用于截断 >99th 百分位的文档with open("ragqa_arena_tech_corpus.jsonl") as f: corpus = [ujson.loads(line)['text'][:max_characters].split('n')[0] + '...' for line in f] print(f"Loaded {len(corpus)} documents. Will encode them below.")# 使用all-MiniLM-L6-v2句子嵌入模型生成文本向量embedding_model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')def embedder(texts): return embedding_model.encode(texts)topk_docs_to_retrieve = 5 # 每个搜索查询要检索的文档数量search = dspy.retrievers.Embeddings(embedder=embedder, corpus=corpus, k=topk_docs_to_retrieve)# 继承dspy.Module,包含检索器(search)和生成器(ChainOfThought)class RAG(dspy.Module): def __init__(self): # 思维链(ChainOfThought):通过签名context, question -> response声明输入输出关系 self.respond = dspy.ChainOfThought('context, question -> response') def forward(self, question): # 前向推理流程:检索文档->拼接上下文->生成最终响应 context = search(question).passages return self.respond(context=context, question=question)rag = RAG()rag(question="what are high memory and low memory on linux?")print(evaluate(RAG()))# 使用MIPROv2优化器自动调整提示和权重tp = dspy.MIPROv2(metric=metric, auto="medium", num_threads=12)optimized_rag = tp.compile(rag, trainset=trainset, max_bootstrapped_demos=2, max_labeled_demos=2, requires_permission_to_run=False)# 对比优化前后的性能baseline = rag(question="cmd+tab does not work on hidden or minimized windows")print(baseline.response)pred = optimized_rag(question="cmd+tab does not work on hidden or minimized windows")print(pred.response)print(evaluate(optimized_rag))
输出的部分结果如下所示:
-
未经过调优的RAG评估得分
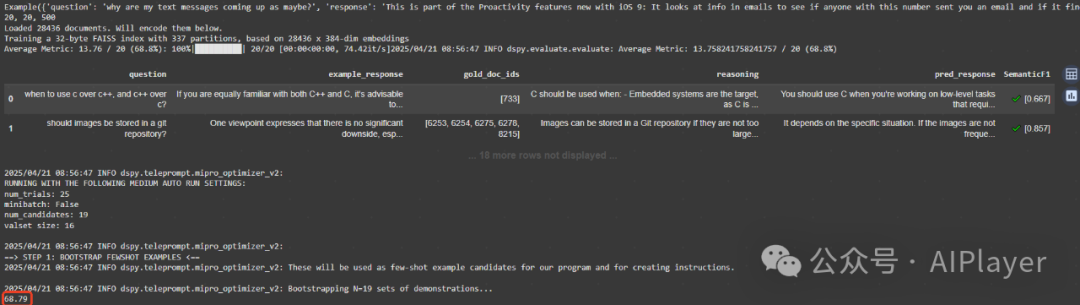
-
优化器dspy.MIPROv2的工作步骤
STEP 1: 通过少量示例来引导模型进行任务
==> STEP 1: BOOTSTRAP FEWSHOT EXAMPLES <==2025/04/21 08:56:47 INFO dspy.teleprompt.mipro_optimizer_v2: These will be used as few-shot example candidates for our program and for creating instructions.2025/04/21 08:56:47 INFO dspy.teleprompt.mipro_optimizer_v2: Bootstrapping N=19 sets of demonstrations...Bootstrapping set 1/19Bootstrapping set 2/19Bootstrapping set 3/1975%|███████▌ | 3/4 [00:00<00:00, 9.09it/s]Bootstrapped 2 full traces after 3 examples for up to 1 rounds, amounting to 3 attempts....100%|██████████| 4/4 [00:00<00:00, 9.12it/s]2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2:
> STEP 2: PROPOSE INSTRUCTION CANDIDATES <==2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: We will use the few-shot examples from the previous step, a generated dataset summary, a summary of the program code, and a randomly selected prompting tip to propose instructions.2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2:Proposing instructions...2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: Proposed Instructions for Predictor 0:2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: 0: Given the fields `context`, `question`, produce the fields `response`.2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: 1: Check the documentation for the specific operating system version or use command-line tools like dscl and fs_usage to find the location....2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: 17: Given the context provided, respond with a step-by-step guide on how to recursively delete empty directories in your home directory.
==> STEP 3: FINDING OPTIMAL PROMPT PARAMETERS <==2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: We will evaluate the program over a series of trials with different combinations of instructions and few-shot examples to find the optimal combination using Bayesian Optimization.2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: == Trial 1 / 25 - Full Evaluation of Default Program ==Bootstrapped 2 full traces after 3 examples for up to 1 rounds, amounting to 4 attempts.Average Metric: 9.65 / 16 (60.3%): 100%|██████████| 16/16 [00:00<00:00, 65.16it/s]2025/04/21 08:56:52 INFO dspy.evaluate.evaluate: Average Metric: 9.654891774891775 / 16 (60.3%)2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: Default program score: 60.34/usr/local/lib/python3.11/dist-packages/optuna/_experimental.py:31: ExperimentalWarning: Argument ``multivariate`` is an experimental feature. The interface can change in the future.warnings.warn(2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 2 / 25 =====Average Metric: 9.90 / 16 (61.8%): 100%|██████████| 16/16 [00:00<00:00, 60.96it/s]2025/04/21 08:56:52 INFO dspy.evaluate.evaluate: Average Metric: 9.895873015873017 / 16 (61.8%)2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: Best full score so far! Score: 61.852025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 61.85 with parameters ['Predictor 0: Instruction 12', 'Predictor 0: Few-Shot Set 7'].2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [60.34, 61.85]2025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 61.852025/04/21 08:56:52 INFO dspy.teleprompt.mipro_optimizer_v2: ========================....2025/04/21 08:56:59 INFO dspy.teleprompt.mipro_optimizer_v2: ===== Trial 26 / 25 =====Average Metric: 9.80 / 16 (61.2%): 100%|██████████| 16/16 [00:00<00:00, 61.79it/s]2025/04/21 08:56:59 INFO dspy.evaluate.evaluate: Average Metric: 9.799439775910363 / 16 (61.2%)2025/04/21 08:56:59 INFO dspy.teleprompt.mipro_optimizer_v2: Score: 61.25 with parameters ['Predictor 0: Instruction 16', 'Predictor 0: Few-Shot Set 16'].2025/04/21 08:56:59 INFO dspy.teleprompt.mipro_optimizer_v2: Scores so far: [60.34, 61.85, 58.79, 55.82, 50.58, 53.71, 63.6, 67.79, 62.04, 65.41, 67.79, 64.42, 67.79, 57.3, 58.93, 62.62, 63.39, 63.53, 60.06, 56.46, 58.87, 63.79, 67.79, 54.2, 67.79, 61.25]2025/04/21 08:56:59 INFO dspy.teleprompt.mipro_optimizer_v2: Best score so far: 67.792025/04/21 08:56:59 INFO dspy.teleprompt.mipro_optimizer_v2: =========================2025/04/21 08:56:59 INFO dspy.teleprompt.mipro_optimizer_v2: Returning best identified program with score 67.79!
-
调优后的RAG评估得分

