

RAG传统方法检索的文档块常含无关噪声,受限于LLM上下文窗口。上下文压缩技术旨在解决此问题,它处理检索到的文档,只保留与查询最相关内容。这能减少上下文长度,去除噪声,提高信息密度,使提供给LLM的上下文更短、更干净,提升回答质量和效率。
-
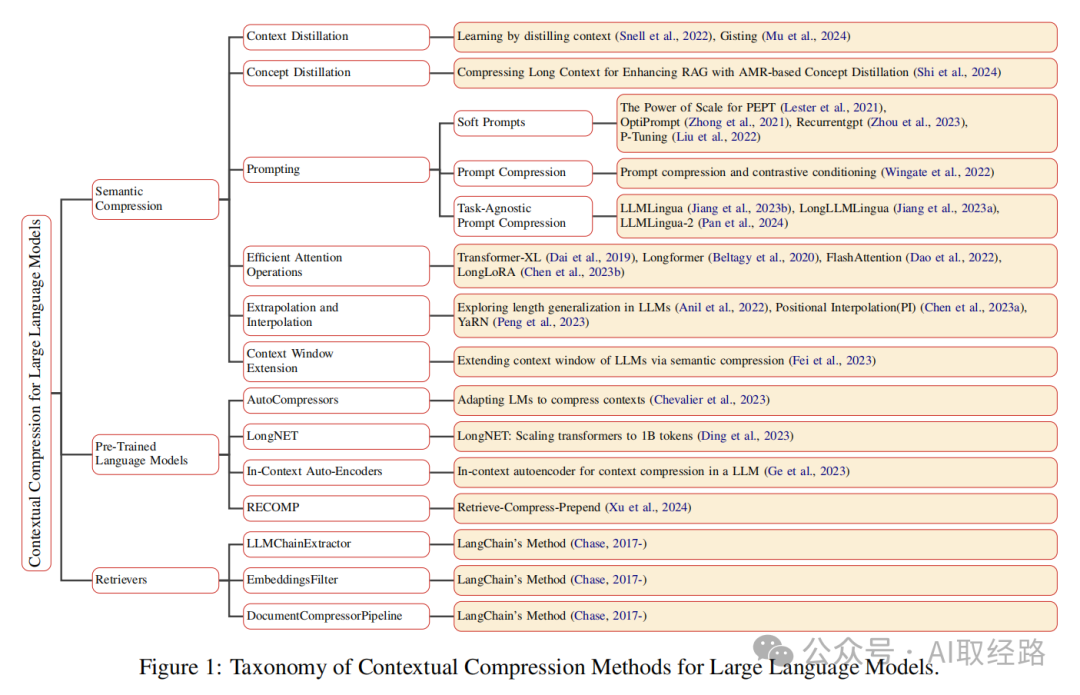
1. 上下文压缩是什么 -
2. 使用LangChain的实现 -
2.1 代码(基于ContextualCompressionRetriever) -
2.2 运行日志 -
2.3 Langchain压缩器的其他实现
— 领取学习资料大礼包,见文末
在RAG中,你要问一个问题,一个简单直接的方法是将文档分割成大小相等的块,然后把这些块的向量嵌入存储到向量数据库中。
当用户提问时,系统会对问题进行嵌入,再在向量数据库中进行相似度搜索,找到最相关的文档块(文本块),然后将它们附加到大模型的提示中。

这种方式的一个问题是,当你把数据导入到向量数据库时,通常并不知道未来会用什么具体的查询来检索这些文档块。
这意味着,当获得用户的具体问题并检索到一个块时,即便这个块中有一些相关内容,也很可能包含一些无关的内容。
这会造成一些困扰:
-
这些与用户问题相关性不高、甚至完全不相关的文档片段就像“噪声”,会干扰 LLM,导致它生成不准确或偏离主题的回答。
-
LLM通常有其能够处理的最大输入长度(称为上下文窗口)。如果我们检索到的文档片段太长,超过了 LLM 的上下文窗口,我们就无法将所有相关信息都提供给模型。
上下文压缩就是为了解决这些问题而诞生的,通过“先检索再压缩”,它会对每条初步检索到的文档块进行筛选或提取,只留下与当前查询最相关的内容,然后再送入生成环节
1. 上下文压缩是什么
上下文压缩是指在将检索到的原始文档块提供给LLM之前,对其进行处理和精简的技术。其主要目标是:
-
减少上下文长度: 确保输入到 LLM 的上下文不超过其最大长度限制。 -
去除噪声信息: 识别并移除与用户查询不相关的部分。 -
保留关键信息: 确保压缩后的上下文仍然包含回答查询所需的最重要信息。
通过上下文压缩,我们可以向 LLM 提供一个更短、更干净、信息密度更高的上下文,从而提高生成回答的质量和效率。
“压缩”在这里既指对单个文档块内容的压缩,也指整体过滤掉不相关的文档。
2. 使用LangChain的实现
LangChain引入了 DocumentCompressor 抽象,使您能够在检索到的文档块上运行 compress_documents(documents: List[Document], query: str) 。
其核心思想很简单:不是立即将检索到的文档块原样返回,我们可以通过给定问题对文档块进行压缩,只返回相关信息。
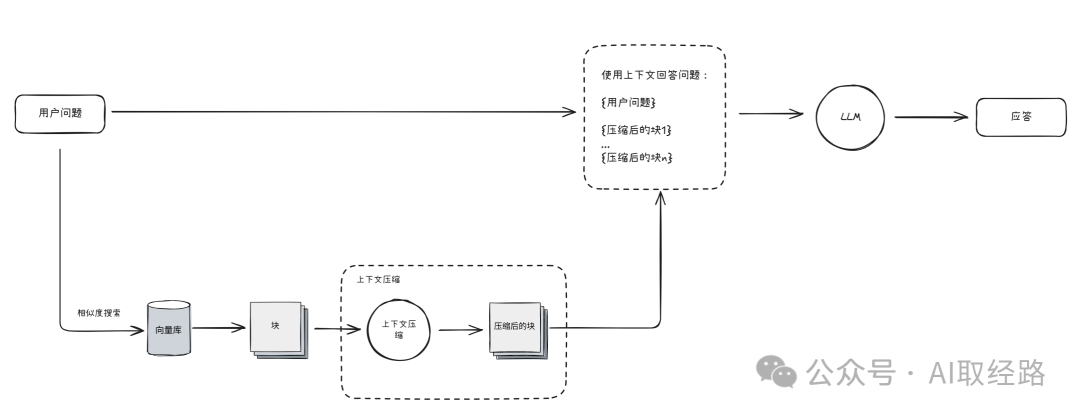
压缩的目标是让传递给 LLM 的信息变得更为相关。这样一来,你也可以传递更多信息给 LLM,因为在最初的检索环节,你可以专注于召回率(比如增加返回的文档块数量),由压缩来处理精确度。
缺点就是需要根据检索到的文档块数量进行额外的 API 调用,这会增加应用的成本和延迟。
2.1 代码(基于ContextualCompressionRetriever)
初始化环境和导入文件:
完成基础设置,使用LangChain的TextLoader加载文本,为后续的文本处理做准备。
# 导入操作系统相关功能模块
import os
# 导入Chroma向量数据库相关模块
from langchain_chroma import Chroma
# 导入OpenAI聊天模型和嵌入模型相关模块
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# 设置OpenAI API密钥
OPENAI_API_KEY = 'hk-iwtbie191e427'
# 将API密钥设置为环境变量
os.environ['OpenAI_API_KEY'] = OPENAI_API_KEY
### 1.导入文件 ##########################################################################
# 导入文本文档加载器
from langchain_community.document_loaders import TextLoader
# 导入递归字符文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 创建文本加载器实例,加载西游记文本文件
loader = TextLoader(file_path="../../data/西游记1.txt", encoding='utf-8')
# 加载文档内容到内存
data = loader.load()
# 打印加载的文档数量
print(f'一共 {len(data)} 个文档')
# 打印第一个文档的字符数
print(f'一共 {len(data[0].page_content)} 个字符')
文本分块和向量嵌入:
实现RAG系统的两个核心步骤:文本分块和向量嵌入。
首先使用RecursiveCharacterTextSplitter将长文本分割成500字符的小块,然后使用嵌入模型将这些文本块转换为向量表示,并存储到Chroma向量数据库中,为后续的相似度搜索做准备。
### 2.文件分块 ###########################################################################
# 创建文本分割器实例,设置块大小和重叠量
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
# 对文档进行分割
splits = text_splitter.split_documents(data)
# 打印分割后的文本块数量
print(f'一共 {len(splits)} 个块')
### 3.文本快嵌入 ##########################################################################
# 创建OpenAI嵌入模型实例
embeddings = OpenAIEmbeddings(model="text-embedding-3-large", base_url="https://api.openai-hk.com/v1")
# 导入文件操作工具
import shutil
# 检查chroma_db目录是否存在,存在则删除
if os.path.exists("./chroma_db"):
shutil.rmtree("./chroma_db")
# 创建Chroma向量数据库实例
vectordb = Chroma.from_documents(
documents=splits, # 使用分割后的文档
embedding=embeddings, # 使用OpenAI嵌入模型
persist_directory="./chroma_db"# 设置持久化目录
)
相关阅读:基于文本结构分块 – 文本分块(Text Splitting),RAG不可缺失的重要环节
定义基础检索器:
实现基础的向量检索功能。创建一个基于相似度搜索的检索器,设置返回前3个最相关的文档块。执行检索后,初始化一个LLM实例,为后续的文本生成做准备。
### 4.定义基础检索器 #################################################################
# 设置查询问题
query = "孙悟空和谁打过架?"
# 设置检索返回结果数量
top_k = 3
# 创建基础检索器
retriever = vectordb.as_retriever(
search_type='similarity', # 使用相似度搜索
search_kwargs={"k": top_k} # 设置返回结果数量
)
# 执行检索
docs = retriever.invoke(query)
# 打印基础检索结果
print("===基础检索=========")
for doc in docs: # 遍历搜索结果
print(doc)
print("--------------------------")
print("====================================")
# 创建OpenAI聊天模型实例
llm = ChatOpenAI(
model="gpt-4.1-nano", # 使用gpt-4o-mini模型
temperature=0, # 设置温度为0
base_url="https://api.openai-hk.com/v1"# 指定API端点
)
相关阅读:Top-K Similarity Search:精准提取RAG系统中最相关的知识
定义基础压缩器LLMChainExtractor:
这段代码实现了文档压缩功能,是上下文压缩的核心部分。导入了ContextualCompressionRetriever和LLMChainExtractor模块,使用之前初始化的语言模型创建了一个文档压缩器。压缩器对之前检索到的文档块进行处理,提取与问题相关的内容,去除无关信息。
### 5.定义基础压缩器 #################################################################
# 导入上下文压缩检索器和文档压缩器
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 创建LLM文档压缩器
compressor = LLMChainExtractor.from_llm(llm)
# 对检索结果进行压缩
docs = compressor.compress_documents(documents=docs, query=query)
# 打印压缩后的结果
print("===压缩=========")
for doc in docs: # 遍历搜索结果
print(doc)
print("--------------------------")
print("====================================")
定义上下文检索器ContextualCompressionRetriever和问答链:
将前面定义的基础压缩器和基础检索器整合成一个上下文压缩检索器,实现了"先检索再压缩"的完整流程。创建一个ContextualCompressionRetriever实例,使用该检索器执行查询。
最后,创建一个RetrievalQA问答链,将语言模型和压缩检索器结合起来,执行问答。
### 5.定义上下文检索器 #################################################################
# 创建上下文压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, # 设置基础压缩器
base_retriever=retriever # 设置基础检索器
)
# 使用压缩检索器执行检索
compressed_docs = compression_retriever.invoke(query)
# 打印压缩检索器的结果
print("===压缩检索器=========")
for doc in compressed_docs: # 遍历搜索结果
print(doc)
print("--------------------------")
print("====================================")
# 导入检索问答链
from langchain.chains import RetrievalQA
# 创建检索问答链实例
qa = RetrievalQA.from_chain_type(
llm=llm, # 设置语言模型
retriever=compression_retriever, # 设置检索器
return_source_documents=True# 设置返回源文档
)
# 执行问答
result = qa.invoke(query)
# 打印问答结果
print(result['result'])
print(result)
2.2 运行日志
-
基础检索部分展示了针对查询"孙悟空和谁打过架?"返回的3个原始文档块 -
压缩部分展示了经过LLM压缩器处理后的结果,可以明显看到:
-
第一个文档块从500多字符被压缩到只保留了孙悟空与魔王对战的核心部分 -
第二个文档块从长篇幅被压缩到只有一句关键信息 -
第三个文档块也只保留了孙悟空与巨灵神战斗的关键描述 -
最终LLM基于压缩后的上下文生成了简洁准确的回答:"孙悟空和魔王、巨灵神等人物打过架。"
这个例子清晰地展示了上下文压缩的价值:它能够有效去除噪声信息,保留与查询相关的核心内容,从而帮助LLM生成更准确的回答。
G:workspaceideapyhello-langchain.venvScriptspython.exe g:workspaceideapyhello-langchainragretrievercontextual_compression.py
一共 1 个文档
一共 73714 个字符
一共 206 个块
===基础检索=========
page_content='猴王喝道:“这泼魔这般眼大,看不见老孙!”魔王见了,笑道:“你身不满四尺,年不过三旬,手内又无兵器,怎么大胆猖狂,要寻我见甚么上下?”悟空骂道:“你这泼魔,原来没眼!你量我小,要大却也不难。你量我无兵器,我两只手勾着天边月哩!你不要怕,只吃老孙一拳!”纵一纵,跳上去,劈脸就打。那魔王伸手架住道:“你这般矬矮,我这般高长,你要使拳,我要使刀,使刀就杀了你,也吃人笑,待我放下刀,与你使路拳看。”悟空道:“说得是。好汉子!走来!”那魔王丢开架子便打,这悟空钻进去相撞相迎。他两个拳捶脚踢,一冲一撞。原来长拳空大,短簇坚牢。那魔王被悟空掏短肋,撞了裆,几下筋节,把他打重了。他闪过,拿起那板大的钢刀,望悟空劈头就砍。悟空急撤身,他砍了一个空。悟空见他凶猛,即使身外身法,拔一把毫毛,丢在口中嚼碎,望空中喷去,叫一声“变!”,即变做三二百个小猴,周围攒簇。' metadata={'source': '../../data/西游记1.txt'}
--------------------------
page_content='好猴王,跳至桥头,使一个闭水法,捻着诀,扑的钻入波中,分开水路,径入东洋海底。正行间,忽见一个巡海的夜叉,挡住问道:“那推水来的,是何神圣?说个明白,好通报迎接。”悟空道:“吾乃花果山天生圣人孙悟空,是你老龙王的紧邻,为何不识?”那夜叉听说,急转水晶宫传报道:“大王,外面有个花果山天生圣人孙悟空,口称是大王紧邻,将到宫也。”东海龙王敖广即忙起身,与龙子、龙孙、虾兵、蟹将出宫迎道:“上仙请进,请进。”直至宫里相见,上坐献茶毕,问道:“上仙几时得道,授何仙术?”悟空道:“我自生身之后,出家修行,得一个无生无灭之体。近因教演儿孙,守护山洞,奈何没件兵器,久闻贤邻享乐瑶宫贝阙,必有多馀神器,特来告求一件。”龙王见说,不好推辞,即着鳜都司取出一把大捍刀奉上。悟空道:“老孙不会使刀,乞另赐一件。”龙王又着鲅大尉,领鳝力士,抬出一捍九股叉来。悟空跳下来,接在手中,使了一路,放下道:“轻!轻!轻!又不趁手!再乞另赐一件。”龙王笑道:“上仙,你不看看。这叉有三千六百斤重哩!”悟空道:“不趁手!不趁手!”龙王心中恐惧,又着□【左“鱼”右“便”】提督、鲤总兵抬出一柄画杆方天戟,那戟有七千二百斤重。悟空见了' metadata={'source': '../../data/西游记1.txt'}
--------------------------
page_content='棒名如意,斧号宣花。他两个乍相逢,不知深浅;斧和棒,左右交加。一个暗藏神妙,一个大口称夸。使动法,喷云嗳雾;展开手,播土扬沙。天将神通就有道,猴王变化实无涯。棒举却如龙戏水,斧来犹似凤穿花。巨灵名望传天下,原来本事不如他;大圣轻轻轮铁棒,着头一下满身麻。巨灵神抵敌他不住,被猴王劈头一棒,慌忙将斧架隔,呵嚓的一声,把个斧柄打做两截,急撤身败阵逃生。猴王笑道:“脓包!脓包!我已饶了你,你快去报信!快去报信!”
巨灵神回至营门,径见托塔天王,忙哈哈下跪道:“弼马温果是神通广大!末将战他不得,败阵回来请罪。”李天王发怒道:“这厮锉吾锐气,推出斩之!”旁边闪出哪吒太子,拜告:“父王息怒,且恕巨灵之罪,待孩儿出师一遭,便知深浅。”天王听谏,且教回营待罪管事。
这哪吒太子,甲胄齐整,跳出营盘,撞至水帘洞外。那悟空正来收兵,见哪吒来的勇猛。好太子:' metadata={'source': '../../data/西游记1.txt'}
--------------------------
===压缩=========
page_content='猴王喝道:“这泼魔这般眼大,看不见老孙!”魔王见了,笑道:“你身不满四尺,年不过三旬,手内又无兵器,怎么大胆猖狂,要寻我见甚么上下?”悟空骂道:“你这泼魔,原来没眼!你量我小,要大却也不难。你量我无兵器,我两只手勾着天边月哩!你不要怕,只吃老孙一拳!”纵一纵,跳上去,劈脸就打。那魔王伸手架住道:“你这般矬矮,我这般高长,你要使拳,我要使刀,使刀就杀了你,也吃人笑,待我放下刀,与你使路拳看。”悟空道:“说得是。好汉子!走来!”那魔王丢开架子便打,这悟空钻进去相撞相迎。他两个拳捶脚踢,一冲一撞。' metadata={'source': '../../data/西游记1.txt'}
--------------------------
page_content='悟空道:“我自生身之后,出家修行,得一个无生无灭之体。近因教演儿孙,守护山洞,奈何没件兵器,久闻贤邻享乐瑶宫贝阙,必有多馀神器,特来告求一件。”' metadata={'source': '../../data/西游记1.txt'}
--------------------------
page_content='猴王变化实无涯。棒举却如龙戏水,斧来犹似凤穿花。巨灵名望传天下,原来本事不如他;大圣轻轻轮铁棒,着头一下满身麻。巨灵神抵敌他不住,被猴王劈头一棒,慌忙将斧架隔,呵嚓的一声,把个斧柄打做两截,急撤身败阵逃生。猴王笑道:“脓包!脓包!我已饶了你,你快去报信!快去报信!”' metadata={'source': '../../data/西游记1.txt'}
--------------------------
====================================
孙悟空和魔王、巨灵神等人物打过架。
2.3 Langchain压缩器的其他实现
LLMChainFilter :使用 LLM 链来决定过滤掉哪些初始检索的文档块。
LLMListwiseRerank :使用基于LLM的文档重排序 ,是一种更可靠但成本更高的方案。
EmbeddingsFilter :通过将文档和查询问题进行嵌入处理,仅返回与问题足够相似的嵌入结果(超过阈值)
