

你是否曾经遇到过这样的情况:向ChatGPT提问专业问题时,它给出的答案看似合理,但实际上缺乏深度或存在事实错误?今天,我们将探索一项解决这一问题的前沿技术——图检索增强生成(GraphRAG),这项结合知识图谱与检索增强生成的创新方法正在彻底改变AI在专业领域的应用方式。
引言
大语言模型(LLM)如GPT系列在文本理解、问答和内容生成等多种任务上取得了令人瞩目的突破。然而,当面对需要专业领域知识的任务时,这些模型往往表现不佳。这主要是因为如下三个原因:
-
• 知识局限性:LLM的预训练知识在专业领域往往广而不深; -
• 推理复杂性:专业领域需要精确的多步推理,而LLM难以在长推理链中保持逻辑一致性; -
• 上下文敏感性:专业领域中同一术语在不同情境下可能有不同含义,LLM常常无法捕捉这些细微差别。
传统RAG的挑战与局限
传统的检索增强生成(RAG)技术通过引入外部知识库,在一定程度上改善了大语言模型的表现。然而,当面对复杂的专业问题时,传统RAG仍然面临三大挑战:
-
1. 复杂查询理解困难:专业领域的问题往往涉及多个实体和复杂关系,传统RAG基于向量相似度的检索方法难以捕捉这些复杂语义关系。给定一个查询,这些RAG方法只能从包含锚实体的文本块中检索信息,无法进行多跳推理。随着粒度的减小,这一限制在处理领域知识时变得更加明显。 -
2. 分散知识整合不足:领域知识通常分散在各种文档和数据源中。虽然RAG使用分块来将文档分割成更小的片段以提高索引效率,但这种方法牺牲了关键的上下文信息,显著降低了检索准确性和上下文理解能力。此外,向量数据库存储文本块时没有对模糊或抽象概念进行层次组织,使得解决此类查询变得困难。 -
3. 系统效率瓶颈:传统RAG通常使用基于向量相似度的检索模块,缺乏对从庞大知识库中检索内容的有效过滤,提供过多但可能不必要的信息。考虑到LLM固有的限制,如固定的上下文窗口(通常为2K-32K标记),难以从过多的检索内容中捕获必要信息。虽然扩展块粒度可以缓解这些挑战,但这种方法显著增加了计算成本和响应延迟。
这些挑战促使研究人员开发出GraphRAG——一种结合知识图谱与检索增强生成的创新技术,旨在解决传统RAG的局限性。
GraphRAG技术介绍
GraphRAG(图检索增强生成)通过将知识图谱与检索增强生成相结合,从根本上提升了大语言模型处理专业知识的能力。与传统RAG不同,GraphRAG将文本转换为结构化知识图谱,明确标注实体间关系,然后基于图遍历和多跳推理检索相关知识子图,最后保持知识结构生成连贯回答。这种方法的核心优势在于能够发现概念间的隐含关联,支持多步推理解决复杂问题,并提供可解释的推理路径。
工作流程
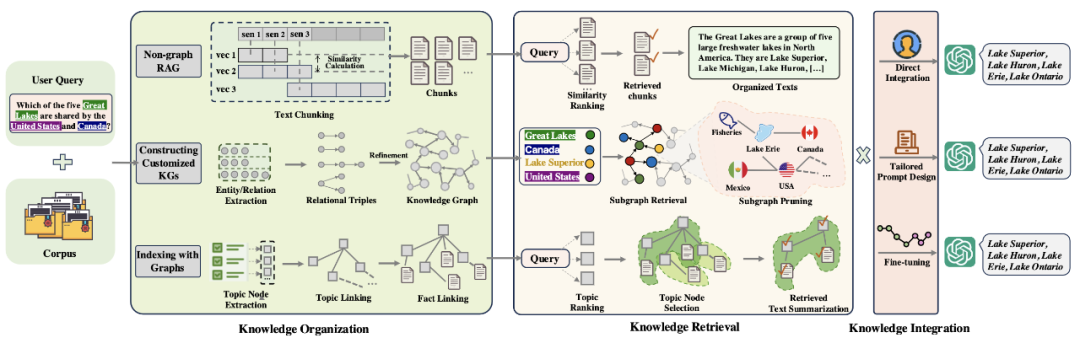
GraphRAG的工作流程可分为三个关键阶段:首先是知识图谱构建,通过自动提取实体和关系形成结构化知识网络;其次是图检索,根据问题定位相关节点并沿关系路径智能扩展;最后是知识融合,将检索到的结构化知识整合成连贯一致的回答,保留原始知识的逻辑关系。这种流程使AI能够像人类专家一样,通过关联不同知识点来解决复杂问题。
GraphRAG与传统RAG的对比
传统RAG与GraphRAG在整个工作流程上存在本质差异。传统RAG采用简单直接的三步流程:首先将文档分割成独立文本块并向量化存储;然后基于语义相似度检索与查询相关的片段;最后简单拼接这些片段作为LLM的上下文生成回答。这种方法虽然实现简单,但难以捕捉复杂的知识关联,常常导致上下文碎片化和推理能力有限。
相比之下,GraphRAG采用更为精细的三阶段工作流程:在知识组织阶段,它不仅提取文本,还识别实体与关系,构建结构化知识图谱;在知识检索阶段,通过图遍历和多跳推理发现隐藏的知识关联,形成完整的知识子图;在知识集成阶段,保留知识的结构关系,融合多源信息并消除冗余,生成连贯且可解释的回答。这种方法特别适合处理需要综合多源信息、进行深度推理的专业领域问题,如医疗诊断、法律分析和科研探索等,同时支持知识的增量更新,维护成本更低。GraphRAG的核心优势在于它不仅能够回答"是什么"的问题,还能解释"为什么"和"如何",为复杂问题提供更深入的解答。
结语
GraphRAG通过引入结构化知识图谱,成功解决了传统RAG在专业领域的核心挑战。这项技术在医疗诊断、金融分析和法律咨询等场景中展现出独特优势,能够连接复杂知识网络、揭示隐藏关联并保持推理路径的可解释性,使AI真正成为专业领域的智能助手。
对于开发者而言,开源项目如浙大和蚂蚁金服开源的KAG[1]、英特尔开源的fast-graphrag[2]、微软开源的graphrag[3] 等工具降低了技术门槛,而医疗、金融等领域的应用案例则提供了实践参考。随着技术成熟,GraphRAG将推动AI从"知道很多"向"真正理解"的转变,为各行业带来更智能的解决方案。
