

前面为大家介绍过大模型相关的专业术语,比如AGI、RAG、LLM。也提到了当前阶段AI大模型存在的一些不足,比如对训练数据的数量和质量要求、对算力和电力的开支,以及大模型最大的问题:信息幻觉。
目前业内对大模型信息幻觉的处理方法,一般都采用了RAG的方法,即Retrieval-Augmented Generation,检索增强生成。简单来说就是通过大模型+知识库的方式,从广泛的知识库中检索相关片段,然后根据这些内容生成最终结果。
这种方式的好处在于,一方面可以缓解大模型的信息幻觉问题,提高在特定领域的结果表现;另一方面,可以提高信息检索和结果生成的效率以及用户体验。
我们常见的各种ChatBot(即聊天机器人),就是基于这种技术原理实现的。与之相关的技术框架,常见的有如下几种:
-
LangChain:开源框架,提供了丰富的组件和工具,用于构建RAG系统。 -
LLama-Index:专为LLama模型设计的RAG框架,适用于特定场景下的应用。 -
RAGFlow:一个较新的RAG框架,注重简洁性和效率,提供预设组件和工作流。 -
Haystack:一个常用的开源框架,支持向量存储和编排层,是RAG系统的重要组成部分。 -
GraphRAG:专注于大模型驱动的RAG技术,通过优化向量库构建与推理性能来提升RAG系统的效率。
以LangChain为例,利用RAG减缓信息幻觉的实现原理,有如下多个步骤:
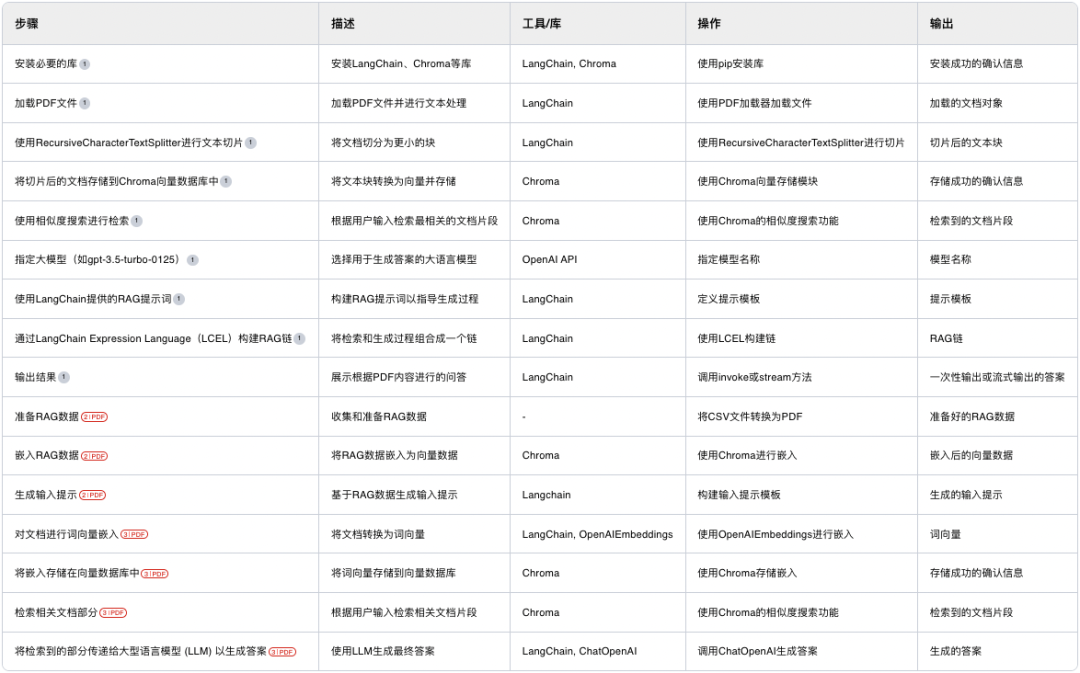
对上述步骤进行简化,可以得到如下七个关键步骤:
-
上传文档:用户上传相关的知识文档,LangChain支持txt、pdf、docx等多种格式,并将其自动转化为markdown格式存储。 -
文本切割:为了便于分析处理,需要将长文本切割为多个小块(chunk),类似于tcp协议的信息传输机制(先切分再传递+丢包检测)。 -
文本向量化:将切割后的文本小块,通过EMB(数据拆分和映射)技术转换为算法可以处理的向量,并存入向量数据库。 -
问句向量化:将用户的提问内容进行向量化处理(切割+拆分+映射)。 -
语义检索和匹配:将向量化后的用户提问内容与向量库中的文本块匹配,按规则匹配出与用户问句向量最相似的Top X(大小取决于规则定义)个。 -
提交prompt至LLM:将匹配得到的文本和用户问句,添加到已定义好的提示词模版中,提交给LLM进行处理。 -
生成最终的输出答案:LLM生成最终的输出答案,并返回给用户。
用一张图来概括,基于LangChain实现RAG能力的原理如下:
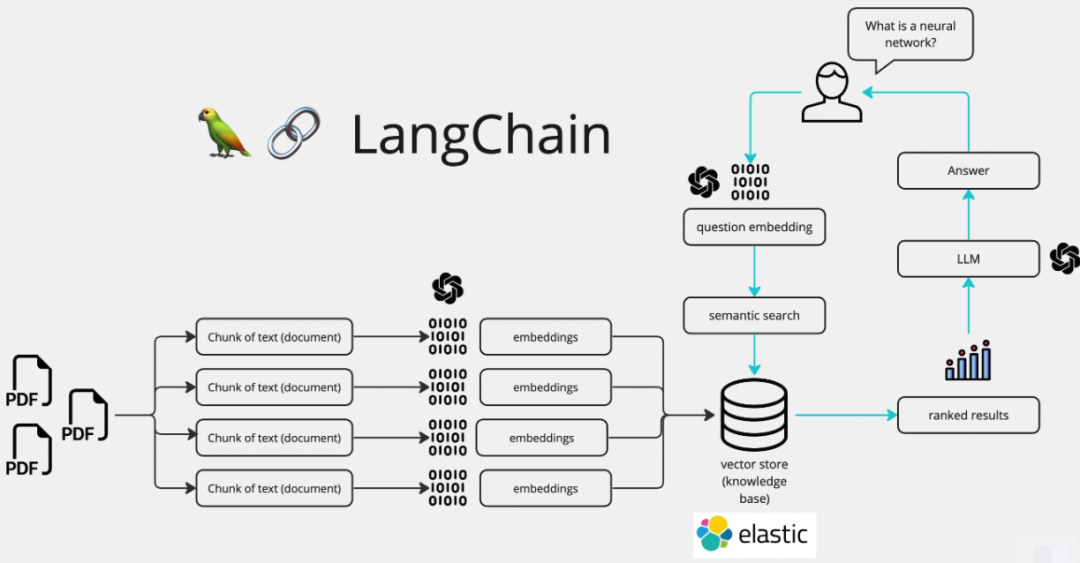
至此,利用RAG能力缓解大模型信息幻觉的一个ChatBot就完成了,接下来就是对其进行模型效果评测。
注意,并不是说基于上述方案就可以实现一个回答精度很高的ChatBot,而是需要通过持续大量的训练,才能得到更匹配我们预期的大模型,这也是大模型训练过程的缩影。
模型效果评测,首先需要确定评测标准。评测标准的定义,需要基于训练模型的预期目标和实际的业务场景,对大模型输出的回答内容评测。按照技术领域的通用测试原则,需要构建评测集(即IT技术领域的测试用例),对其展开评测。
评测集需要满足如下几点要求:
-
可以理解用户提问内容。 -
可以匹配正确的知识库内容。 -
基于用户问句和知识库内容的回答要确保全面准确。 -
输出的最终回答是否包含知识库内容以外的信息(简单理解就是联网/不联网)。 -
输出的最终回答是否可靠(即需要对多轮次评测的输出结果进行对比,判断差异是否过大)。 -
需要支持基于上下文的追问,且追问后输出的最终回答同样必须满足上述几点要求。
