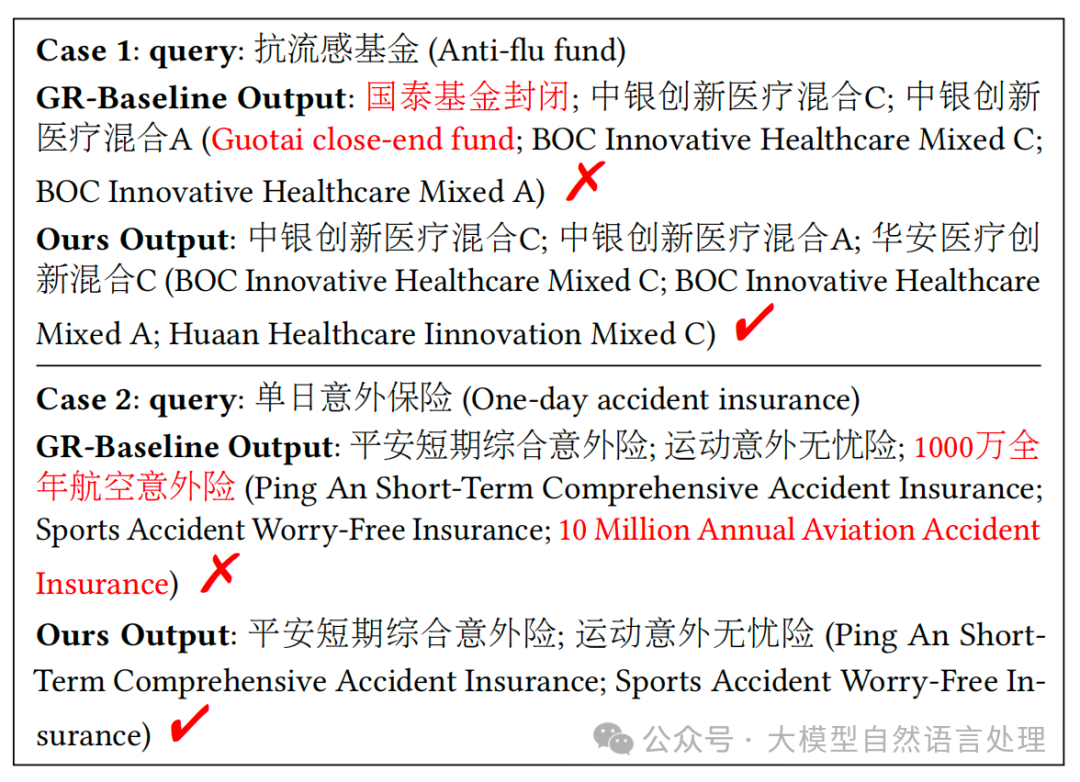
基于LLM的生成式检索(GR)在进行文档知识检索时或多或少的会引入幻觉,在一些对精度要求比较高的场景(如:金融等)如何缓解幻觉,下面来看下支付宝生成式检索缓解幻觉方案,供参考。
方法

如上图所示,框架分为两部分:知识蒸馏推理和决策Agent
知识蒸馏推理
目的:通过利用更大规模的LLM生成显式的推理数据,增强较小规模的LLM-based GR模型的训练。知识蒸馏推理模块提升了GR模型的检索精度,减少了幻觉现象。思路如下:
推理源数据构建
-
相关和无关查询-文档对的收集:
-
相关查询-文档对:从训练语料库 中采样得到 。
-
无关查询-文档对:通过以下步骤获取:
◦ 使用初步GR模型 对搜索日志中的查询集 进行检索,生成文档集合 。
◦ 使用一系列开源LLM 对每个查询-文档对 进行相关性判断,筛选出无关对 。prmopt如下:

◦ 只有当所有LLM都判定某个查询-文档对为无关时,才将其分类为无关。
-
构建推理源数据: 将相关和无关的查询-文档对组合成推理源数据 。
-
使用推理生成器 (一个比GR模型 更强大的模型)生成高质量的推理过程。
-
输入为查询-文档对及其相关性判断结果,输出为推理过程 。
-
使用下面Prompt进行推理生成:
-
利用生成的推理数据 增强模型对推理过程的理解。
-
使用更新后的训练数据集 对GR模型进行监督微调(SFT),得到新的GR模型 。
-
推理过程的训练损失函数为:

推理生成

蒸馏推理数据
将推理过程加入到训练数据中,通过监督微调增强GR模型的理解能力。步骤如下:
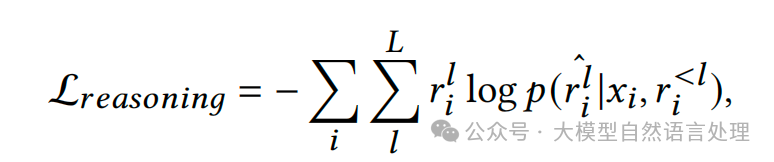
决策Agent
决策Agent的目的是进一步提高检索精度。总体流程如下:
-
输入:
-
一个由GR模型检索到的文档 。
-
候选文档集合 。
步骤:
• 步骤3:筛选最终结果:只有在所有评估视角下都被认为相关的文档才会被保留作为最终的检索结果。可以看作是多个LLM都投票一致。
-
步骤1:使用检索模型进行初步检索,利用一个检索模型(RM),可以是稀疏检索(SR)或密集检索(DR),为GR检索到的文档 检索出最相关的m个文档 。
-
步骤2:使用LLM进行多角度评估:使用一个强大的LLM(例如Qwen2.5-32B)从多个角度评估这些文档与查询的相关性。在本文的场景中,结构化信息如产品公司、产品类型和产品期限被用作评估的不同视角。prompt如下:

实验性能
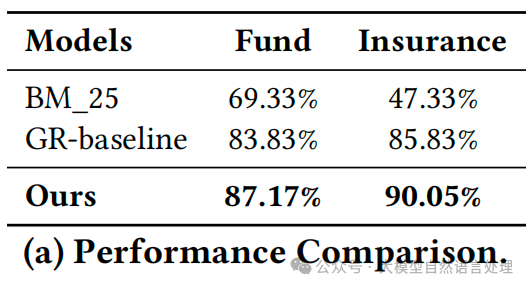
离线性能比较:与基线GR模型相比,提出的方法在基金数据和保险数据上的准确率(ACC)分别提高了3.34%和4.22%。与检索基线模型BM25相比,基金数据上的ACC提高了17.84%,保险数据上提高了42.72%。

消融研究:移除推理组件导致基金检索准确率下降2%,保险检索下降2.39%。决策代理模块分别提高了基金检索准确率1.67%和保险检索准确率3.88%。这进一步验证了推理和决策代理模块在提高生成式检索精度方面的有效性。
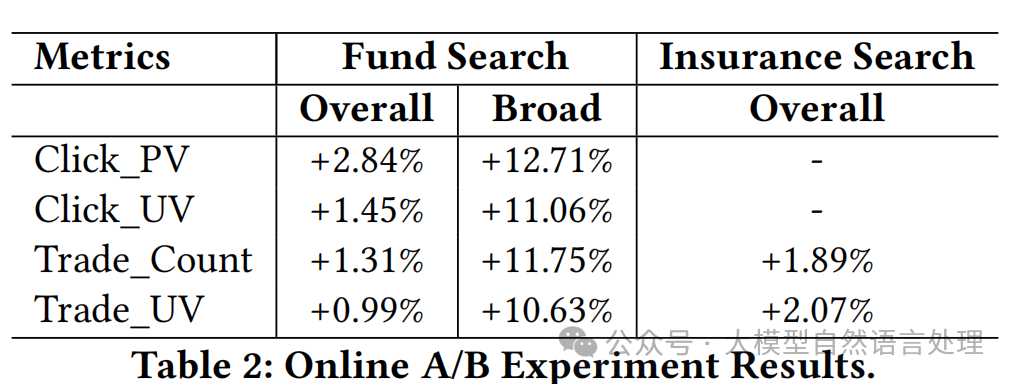
在线A/B测试:在支付宝的基金搜索和保险搜索中进行了在线A/B测试,结果表明在点击页面浏览量(Click_PV)、点击独立访客数(Click_UV)、交易次数(Trade_Count)和交易独立访客数(Trade_UV)等关键搜索指标上均有显著改进,统计显著性水平为95%(p值<0.05)。这表明所提方法在实际应用中也能显著提高搜索质量和转化率。