
为了方便大家更好了解RAG的分块,将分块策略进行一些回顾和总结。
01
分块的重要性
分块策略在RAG(检索增强生成)系统中扮演着核心角色,其价值主要体现在三个关键维度:
-
效率优化:显著降低计算资源消耗
-
相关性提升:增强检索结果的精准度
-
上下文保持:确保信息的连贯性和完整性
同时在选择分块策略时,需要综合评估以下关键因素:
-
数据特性:结构化数据与非结构化数据的处理差异
-
查询复杂度:简单查询与复杂多跳查询的不同需求
-
资源条件:可用计算资源与响应时间要求的平衡
-
性能目标:在响应速度、结果准确性和上下文保持之间的权衡
02
RAG的典型工作流程

将其他信息存储为向量,将传入的查询与这些向量匹配,并将最相似的信息与查询一起提供给 LLM。
向量存储:将文件分块并编码,存入到向量数据库。
信息检索:用户输入查询,查询文本同样被编码为向量。
增强:将检索到的信息片段整合进发送给 LLM 的Prompt。
生成:LLM 基于原始问题和增强的上下文生成最终回答。
如果没有适当的分块,RAG 可能会错过关键信息或提供不完整、断章取义的响应。目标是创建在足够大以保留意义和足够小以适合模型的处理限制之间取得平衡的块。结构良好的数据块有助于确保检索系统能够准确识别文档的相关部分,然后生成模型可以使用这些部分来生成明智的响应。
03
5种分块策略详解

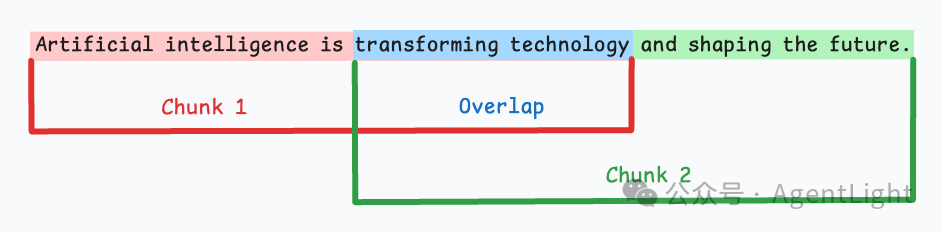
固定大小分块
生成块的最直观、最直接的方法是根据预定义的字符、单词或标记数量将文本拆分为统一的段。
优点:
-
实现简单高效,只需按字符数或Token数切分。
-
确定性结果,相同输入必然得到相同分块。
缺点:
-
语义割裂风险,暴力切割可能中断完整语义单元。
-
关键信息分散,关联内容被分配到不同块。
-
检索时可能遗漏上下文。
def fixed_size_chunk(text, max_words=100):words = text.split()return [' '.join(words[i:i + max_words]) for i in range(0, len(words),max_words)]# Applying Fixed-Size Chunkingfixed_chunks = fixed_size_chunk(sample_text)for chunk in fixed_chunks:print(chunk, 'n---n')
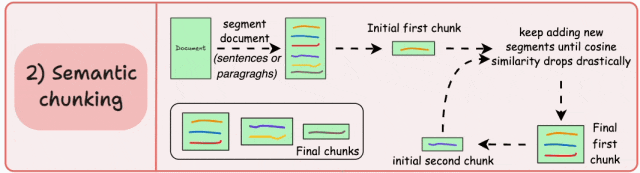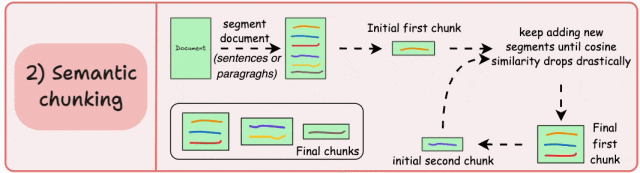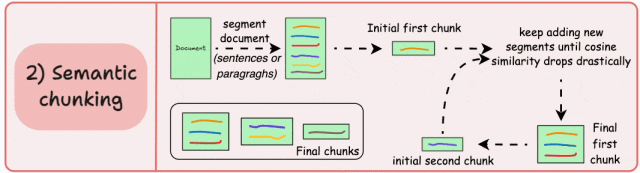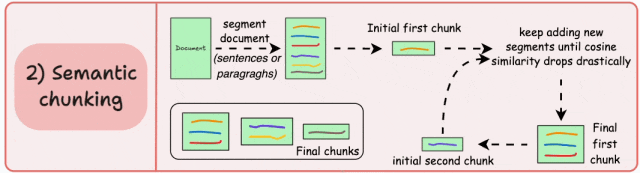
语义分块
根据有意义的单元(如句子、段落或主题部分)对文档进行分段。接下来,为每个区段创建嵌入。假设我从第一个 segment 及其嵌入开始。如果第一个段的嵌入与第二个段的嵌入具有较高的余弦相似度,则两个段将形成一个块。这种情况一直持续到余弦相似度显著下降。当它出现时,我们开始一个新的块并重复。
优点:
-
保留句子级别的含义。
-
更好的上下文保留。
缺点:
-
块大小不均匀,因为句子的长度不同。
-
当句子太长时,可能会超过模型中的标记限制。

def semantic_chunk(text, max_len=200):doc = nlp(text)chunks = []current_chunk = []for sent in doc.sents:current_chunk.append(sent.text)if len(' '.join(current_chunk)) > max_len:chunks.append(' '.join(current_chunk))current_chunk = []if current_chunk:chunks.append(' '.join(current_chunk))return chunks# Applying Semantic-Based Chunkingsemantic_chunks = semantic_chunk(sample_text)for chunk in semantic_chunks:print(chunk, 'n---n')
递归分块
首先,基于固有分隔符(如段落或节)进行 chunk。
接下来,如果大小超过预定义的数据块大小限制,则将每个数据块拆分为较小的数据块。但是,如果 chunk 符合 chunk-size 限制,则不会进行进一步的拆分。

优点:
-
语义完整性高,优先在自然边界(如段落结尾)分块,保持上下文连贯。
-
更好的上下文保留。
缺点:
-
实现比固定大小分块更复杂一些。
-
参数敏感,分隔符顺序和重叠量需精细调优。

def recursive_chunk(text: str,separators: List[str] = ["nn", "n", "。", "?", "!", ". ", "? ", "! "],chunk_size: int = 500,chunk_overlap: int = 50,) -> List[str]:"""递归分块核心算法:param text: 输入文本:param separators: 优先级递减的分隔符列表:param chunk_size: 目标块大小(字符数):param chunk_overlap: 块间重叠量:return: 分块结果列表"""chunks = []# 终止条件:文本已小于目标块大小if len(text) <= chunk_size:return [text]# 按优先级尝试每个分隔符for sep in separators:parts = re.split(f"({sep})", text) # 保留分隔符parts = [p for p in parts if p.strip()] # 移除空片段# 合并片段直到达到chunk_sizecurrent_chunk = ""for part in parts:if len(current_chunk) + len(part) <= chunk_size:current_chunk += partelse:if current_chunk:chunks.append(current_chunk)current_chunk = part[-chunk_overlap:] + part if chunk_overlap > 0 else partif current_chunk:chunks.append(current_chunk)# 如果成功分块则退出循环if len(chunks) > 1:break# 如果没有找到合适分隔符,强制分割if len(chunks) <= 1:chunks = [text[i:i+chunk_size] for i in range(0, len(text), chunk_size - chunk_overlap)]return chunks
文档基础结构分块
它利用文档的固有结构(如标题、部分或段落)来定义块边界。
这样,它通过与文档的逻辑部分保持一致来保持结构完整性。

优点:
-
精准的文档保持,保留文档逻辑单元(如完整表格、代码块、章节)。
-
划分方式自然,符合人类的阅读和理解习惯。
缺点:
-
格式依赖。纯文本文件无法获取结构信息,不同格式需要不同解析器(PDF/EPUB/PPT等)。
-
生成的块大小可能差异巨大,某些块可能非常长,超出 LLM 的处理限制。

基于LLM分块
利用大型语言模型 (LLM) 自身的理解能力来判断文本的最佳分割点。

优点:
-
可识别隐含语义边界(如科研论文中的”假设-论证-结论”逻辑结构)。
-
多维度上下文感知。
缺点:
-
资源消耗问题,由于通过LLM在进行分块,计算成本高,速度慢。
-
Prompt的设计复杂,并且上下文有限制。
以上就是基于RAG的5种分块策略。其他还有很多细分的RAG的分块策略,下次在进行介绍。

点击分享 让更多人看到
