

导读 本文将介绍#知乎 直答产品搭建过程中的实践经验。
1. 知乎直答产品介绍
2. 实践经验分享
3. 直答专业版介绍
分享嘉宾|王界武知乎AI 算法负责人
编辑整理|蔡郁婕
内容校对|李瑶
出品社区|DataFun
知乎直答产品介绍

-
认真专业:与知乎专注专业内容生产的调性相符,严格把控参考来源与质量,确保回答认真且专业。 -
连接创作者:可在使用中关注、与创作者交流互动获取专业见解。 -
真实可信:依托知乎经用户校验的内容,有更高的公信力。 -
多元#数据源:除自身图文数据,还引入了公开英文文献、维普等专业论文库及全网数据以补充知识。
实践经验分享
1. 检索增强生成(RAG)框架
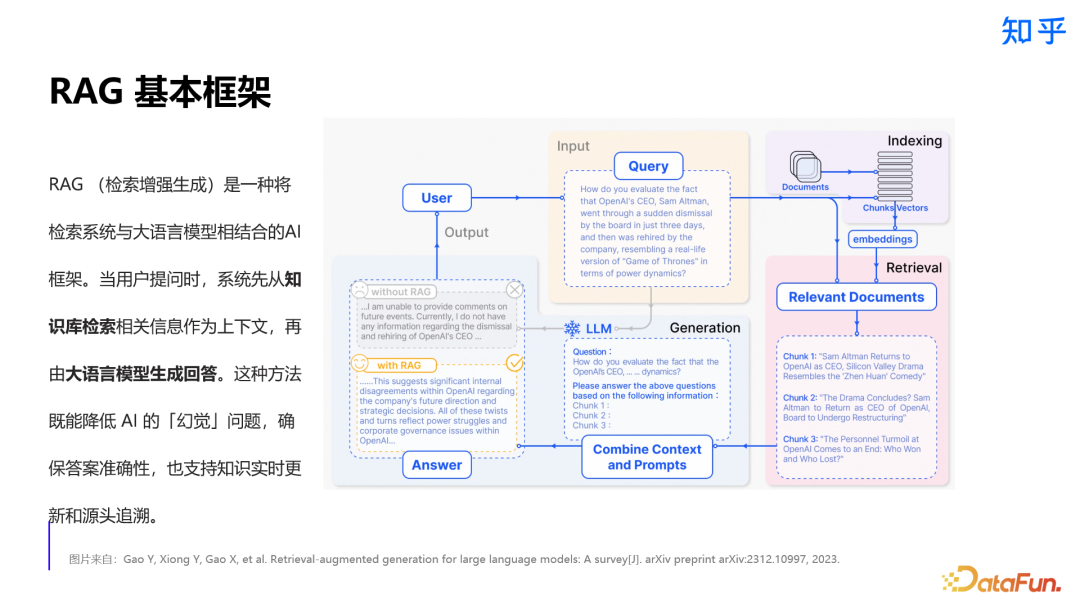

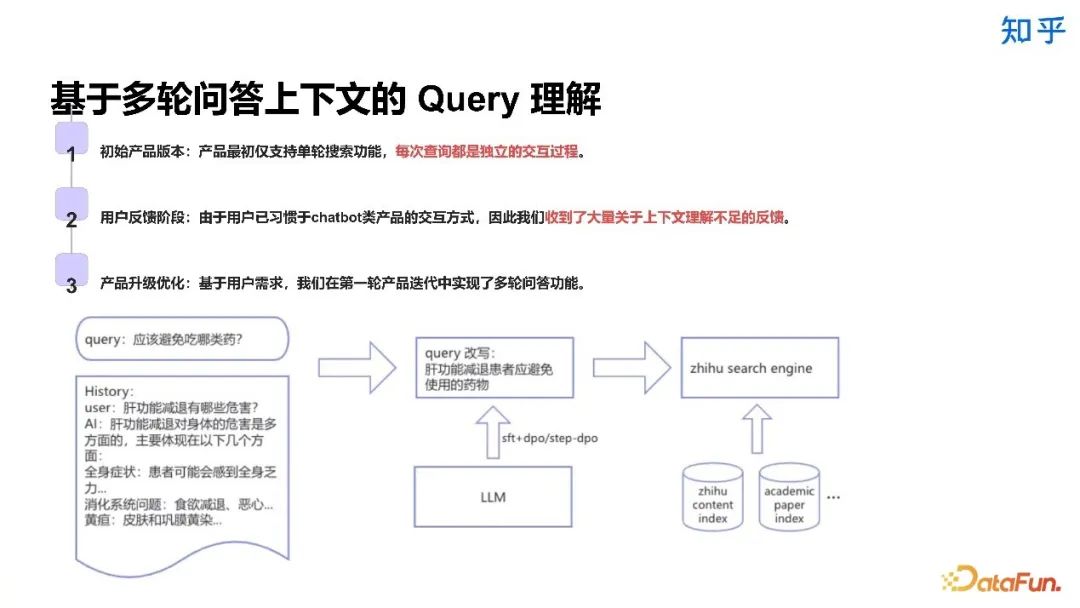
2. Query 理解相关实践

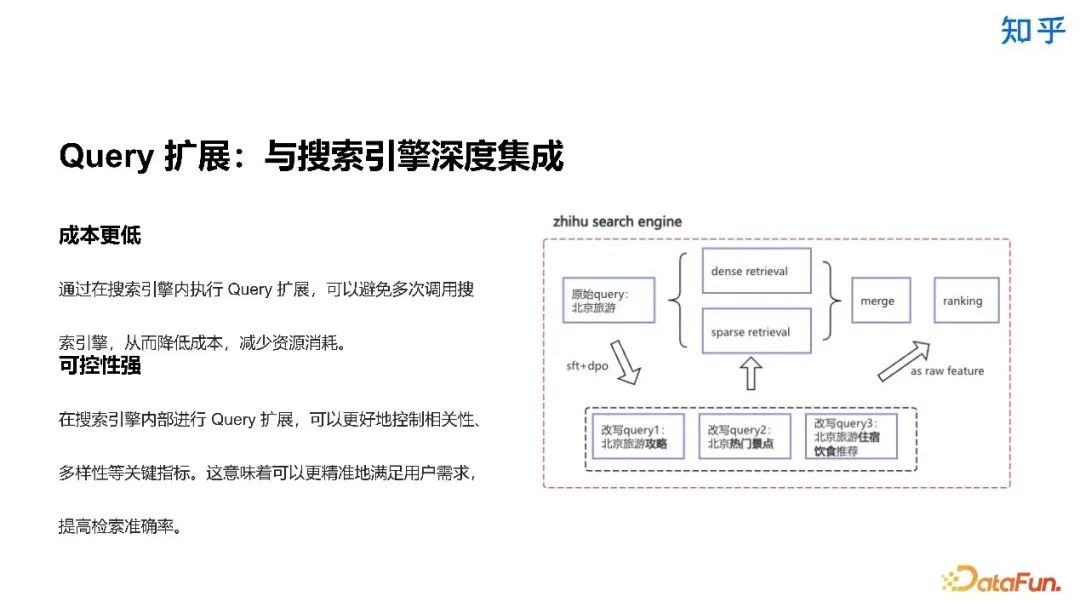
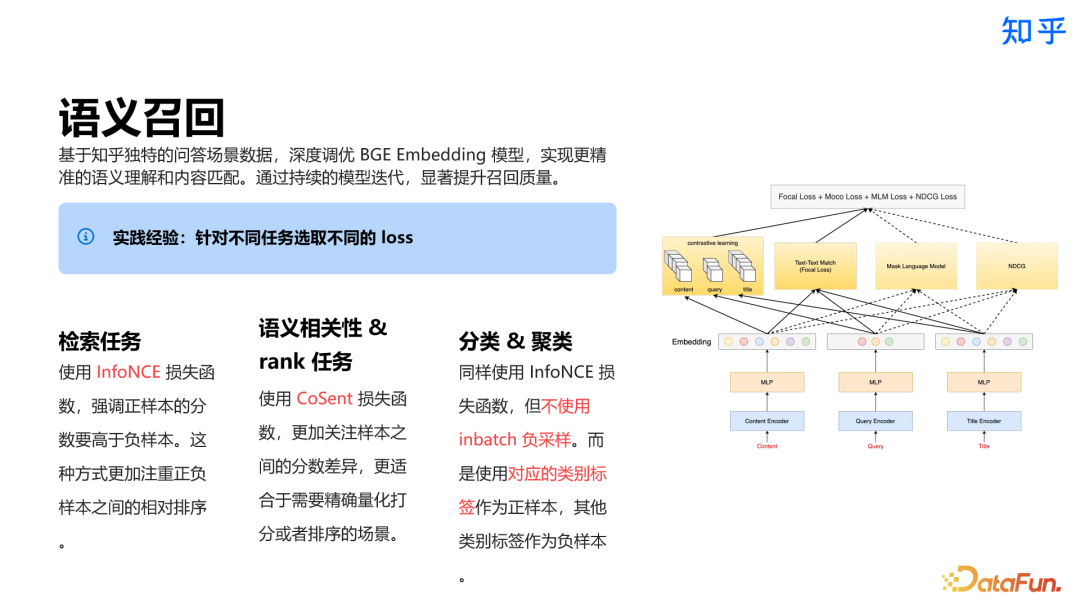
3. 召回方案
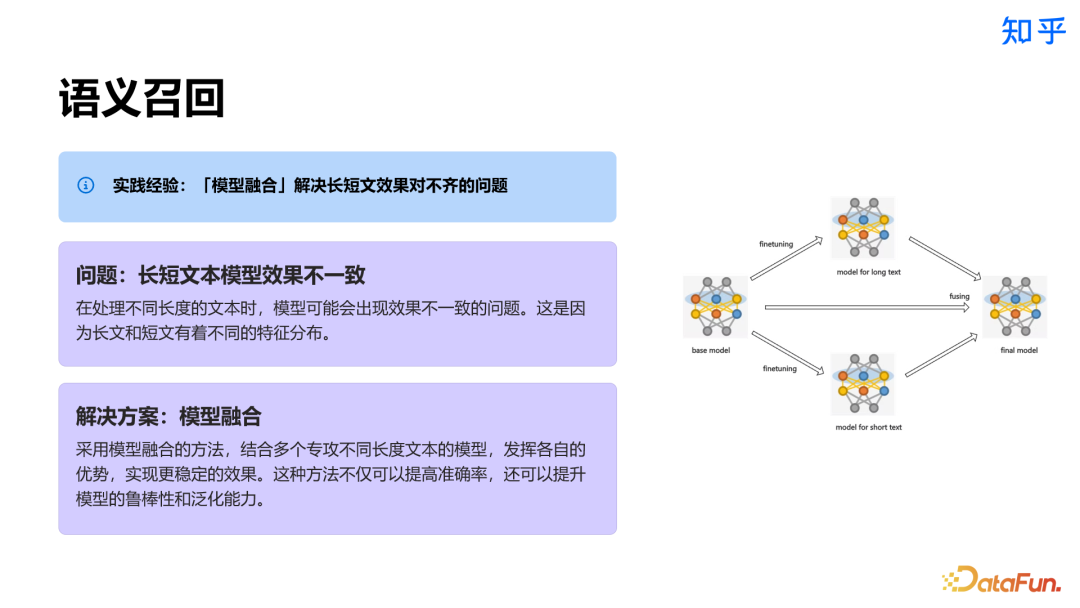


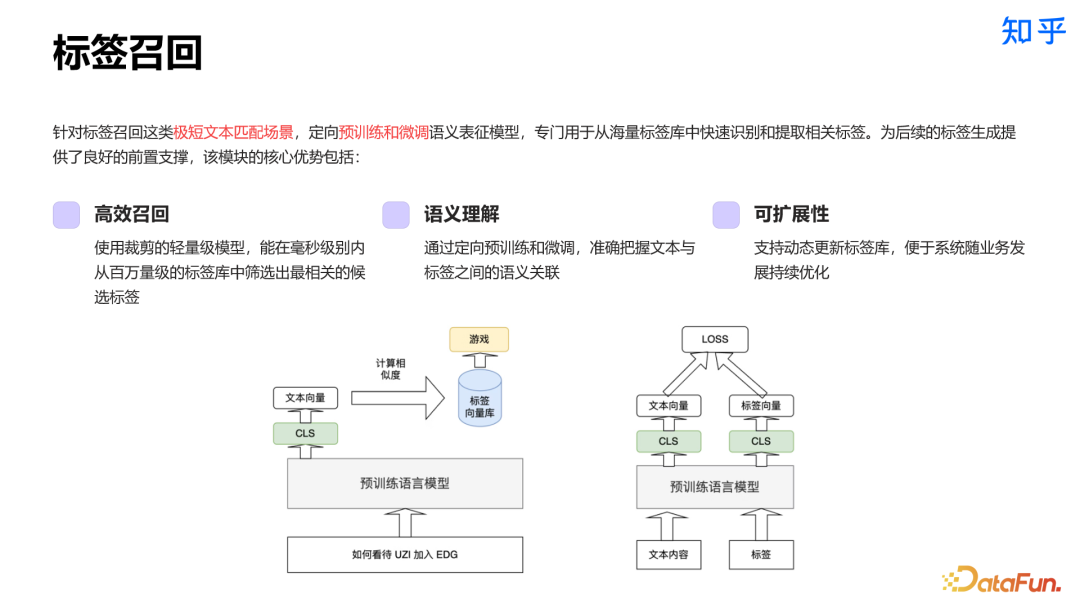

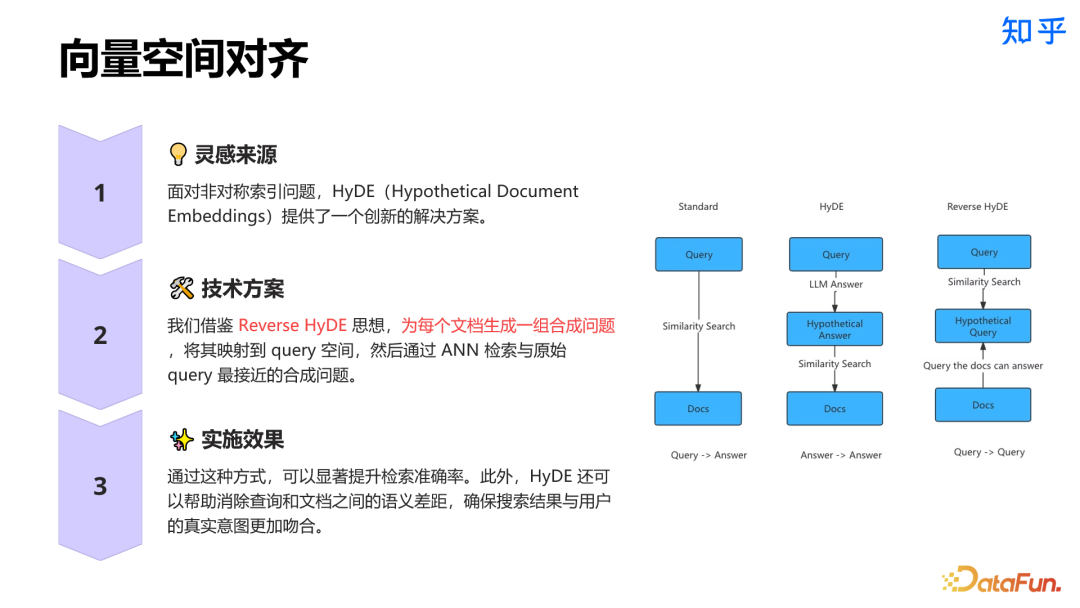
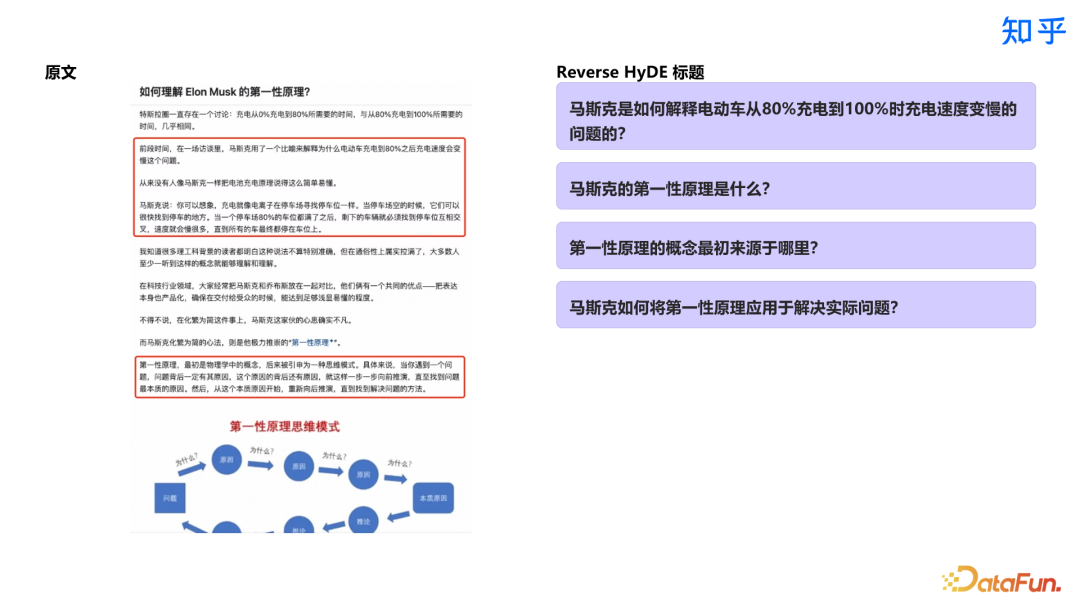
4. Chunk 相关实践
-
降低成本与延迟:通过 chunk 技术压缩上下文长度,可以显著降低推理计算成本,同时减少响应延迟,提升系统整体性能。 -
提升信息利用效率:大模型在处理过长上下文时容易出现「Lost in the Middle」现象,难以准确抓住关键信息。chunk 通过提炼核心内容,帮助模型更高效地利用有限的上下文窗口。
-
语义连贯性受损:不当的 chunk 处理可能导致上下文割裂,引发模型产生错误理解和虚假信息。 -
信息完整性缺失:过度压缩可能造成重要信息丢失,导致模型无法提供完整准确的回答。 -
噪声干扰问题:在信息提取过程中可能引入无关信息,影响最终输出的质量和准确性。
-
技术实现简单,处理速度快。 -
分块大小的选择直接影响效果,较大分块能保持完整语义,有助于理解全局内容;而较小分块处理更快,资源消耗更少。


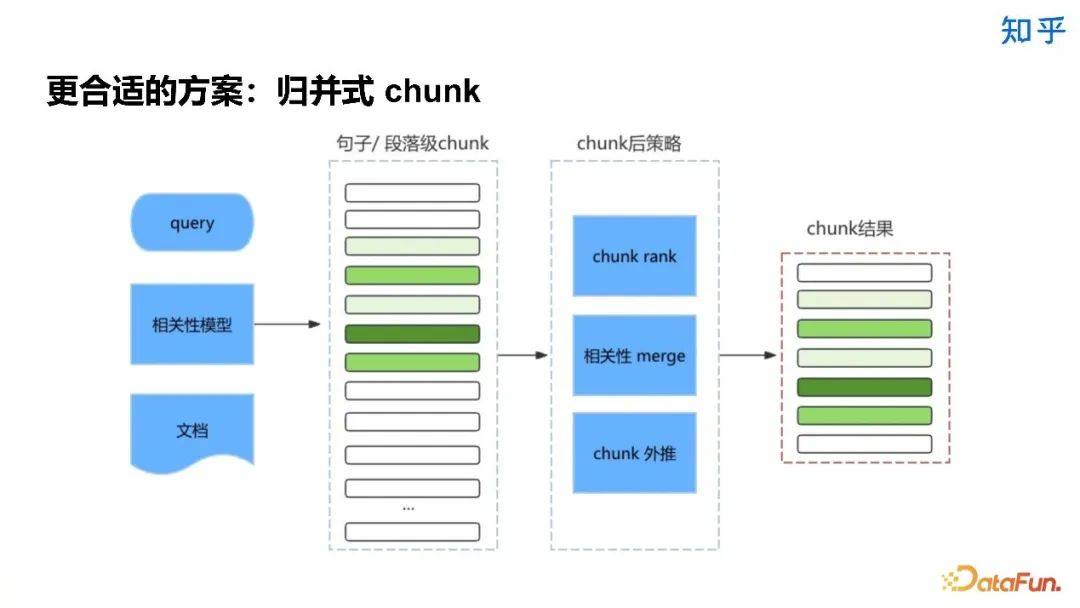
5. Rerank 相关经验
-
关键信息感知:过多的上下文可能会引入更多的噪声,削弱 LLM 对关键信息的感知。因此需要通过相关性控制,确保生成的内容集中于最重要的信息。 -
多样性控制:冗余信息可能会干扰 LLM 的最终生成,因此需要通过多样性控制,确保生成内容具备丰富性和创新性。 -
提升生成内容权威度:结合知乎社区投票机制加权排序,可以提升生成内容的权威性和可信度,满足用户对高质量内容的需求。
6. Generation 相关经验
-
上下文信息元数据增强:通过精心组织上下文结构,融入可验证的元数据信息(如来源、时间、作者等),显著提升输出内容的可信度和权威性。同时确保生成内容的准确性和连贯性。 -
Planning 能力探索:探索大模型的 planning 能力,通过任务分解和推理链等技术,不断增强系统解决复杂多步骤问题的能力。重点提升对专业领域问题的处理水平。 -
模型优化与对齐:持续优化模型调优与对齐策略,通过细致的 badcase 分析和针对性训练,全面提升模型的指令理解和执行能力。确保生成结果始终符合预期标准和用户需求。




7. 评估机制
-
偏向语言风格:评测结果可能更多地反映了模型的语⾔⻛格,而不是其真实的能⼒。恭维、幽默或专业术语的使用都可能影响评测结果。 -
观点差异:不同的评测人对功能、价值、及重要性等问题可能有较大的主观观点差异,这会影响评测结果的一致性和可信度。 -
错误偏好:如果某个模型固定会犯某些错误,这些错误可能会在后续的评测中更容易被注意到,从而影响结果。

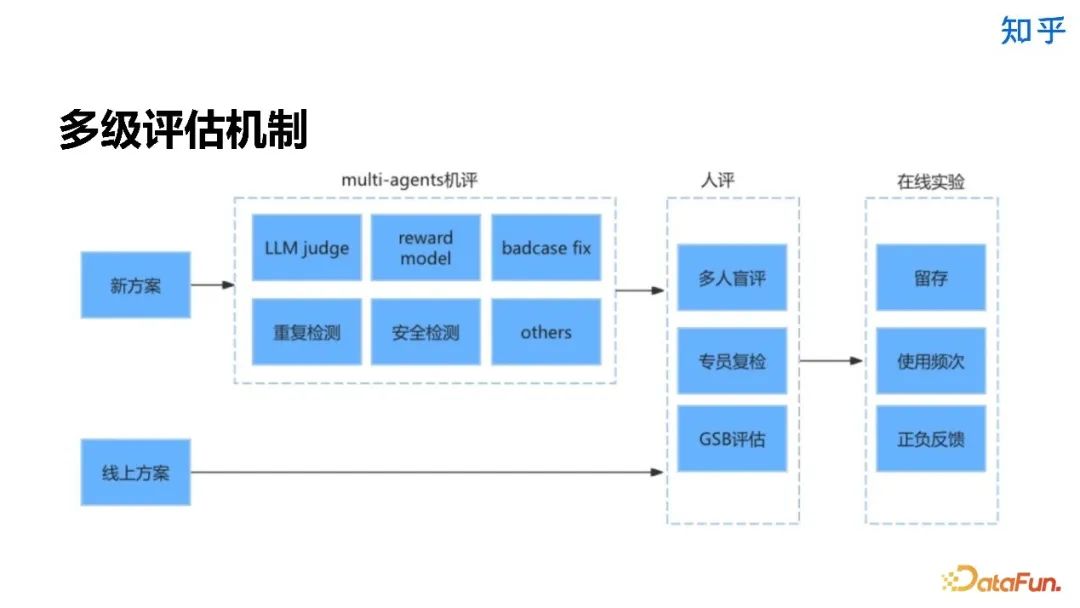
8. 工程优化和成本控制



直答专业版介绍
-
引入优质数据源:知乎直答专业版引入了多种高质量的数据源,包括维普论文库、公开英文文献、知乎精选等内容,经过严格筛选确保内容专业可信。 -
海量论文期刊数据库:引入国内外海量的论文库和期刊库,用户可以全面搜索并获取相关原文内容,满足对高质量信息的需求。 -
支持学术研究和专业工作:这些优质的数据源为用户的学术研究和专业工作提供了坚实的基础和全面的信息支持。
-
文档上传:支持 PDF 等多种格式上传,系统可智能解析文档内容。单轮交互最多支持 99 个文档,满足专业需求。 -
智能解析:系统自动处理上传的文档内容,支持基于文档的智能问答功能。 -
定向问答:支持基于个人知识库的定向问答,帮助用户更高效地利用已有知识,打造结构化的知识体系。
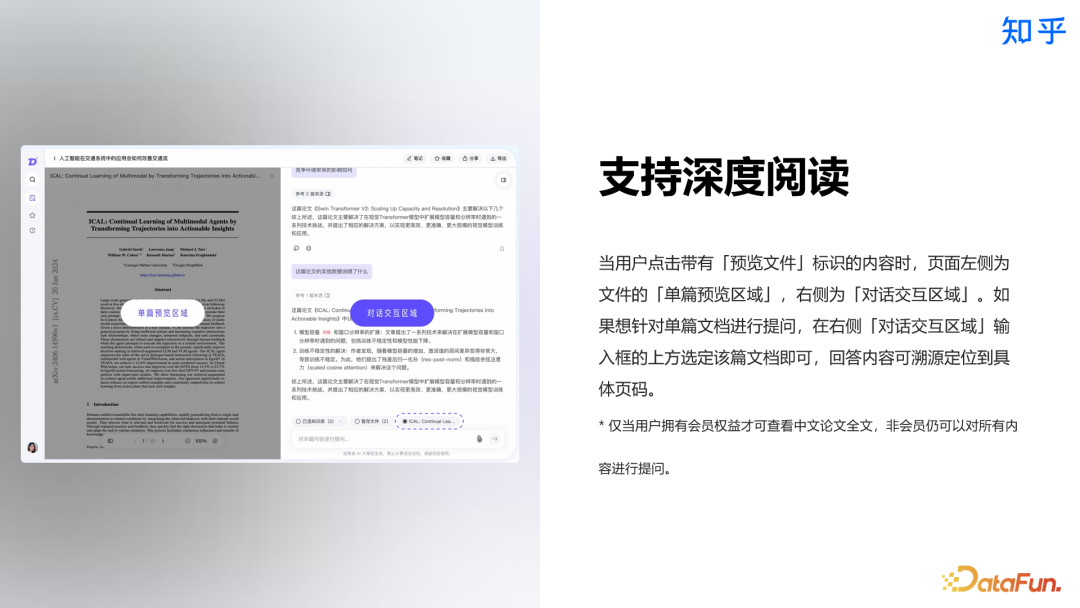

-
融合:将直答与知乎社区深度融合,满足用户「找答案」的需求,提供更加丰富、全面、及时的内容。 -
多模态:拓展更加丰富的交互模式和富媒体结果展示,让用户获取信息更加便捷生动。 -
推理能力:Reasoning 能力 o1 化,使直答具备更强的解决复杂问题能力 -
专业化:不断优化专业版,满足科研群体的专业需求,提供极致的使用体验。
