我们知道,检索增强生成 RAG 通过整合外部知识库与生成模型,有效缓解了大模型在专业领域的知识局限性。传统的知识库以文本为主,通常依赖于纯文本嵌入来实现语义搜索和内容检索。
然而,随着多模态数据需求的增长和复杂文档处理场景的增多,传统方法在处理混合格式文档(如包含文本、图像、表格的 PDF)或长上下文内容时,往往面临性能瓶颈。Cohere Embed v4 的出现为这些挑战提供了创新解决方案,其多模态嵌入能力和长上下文支持显著提升了 RAG 系统的性能和适用性。
Cohere Embed v4 是一个能够满足企业需求的多模态嵌入模型,发布于 2025 年 4 月 15 日。它可以处理文本、图像和混合格式(如 PDF),非常适合需要处理复杂文档的场景。它的关键功能如下,
-
多模态支持:可以统一嵌入包含文本和图像的文档,如 PDF 和演示幻灯片。 -
长上下文:支持高达 128K 的上下文长度,约 200 页,适合长文档。 -
多语言能力:覆盖 100 多种语言,支持跨语言搜索,无需识别或翻译语言。 -
安全性和效率:优化用于金融、医疗等行业,可在虚拟私有云或本地部署,并提供压缩嵌入,节省高达 83% 的存储成本。
下面,我们来测试一下这个 Cohere Embed v4,它作为嵌入模型,需要配合大模型来一起搞事情,比如 Gemini Flash 2.5。
首先,我们不妨先来理一下Cohere Embed v4 和 Gemini Flash 2.5 在这个任务中是什么关系以及具体是如何协作的呢?
我们要实现一个基于视觉的检索增强生成 (RAG) 系统。在这个系统中,Cohere Embed v4 和 Gemini Flash 2.5 扮演着不同的角色,它们相互配合完成了任务:
-
Cohere Embed v4 负责检索部分。它将图像和文本转换为向量表示(嵌入),然后利用这些嵌入来搜索与用户问题最相关的图像。 -
Gemini Flash 2.5 负责生成部分。它是一个强大的视觉语言模型 (VLM),能够理解图像和文本,并根据它们生成答案。
它们如何配合完成任务的?以下是它们协作的流程:
-
图像嵌入: 首先,使用 Cohere Embed v4对所有图像进行编码,生成图像嵌入,并存储起来。 -
问题嵌入: 当用户提出一个问题时, Cohere Embed v4也会将问题编码成嵌入。 -
检索: 系统将问题嵌入与图像嵌入进行比较,找到与问题最相关的图像。 -
答案生成: 将检索到的图像和用户的问题一起发送给 Gemini Flash 2.5,它会根据图像和问题生成最终的答案。
小结
简而言之,Cohere Embed v4 充当信息检索器,找到与问题相关的图像,而 Gemini Flash 2.5 充当答案生成器,根据检索到的图像和问题生成答案。它们协同工作,实现了基于视觉的 RAG 系统,让用户可以通过自然语言提问来获取图像中的信息。
下面,我们给出的实验代码主要是给出一个思路供实际用图像或 PDF 等构建知识库时参考。
实验代码
以下代码展示了一种基于纯视觉的 RAG 方法,甚至适用于复杂的信息图表。它由两个部分组成:
-
Cohere 最先进的文本和图像检索模型 Embed v4。它允许我们嵌入和搜索复杂的图像,例如信息图表,而无需任何预处理。 -
Vision-LLM:我们使用谷歌的 Gemini Flash 2.5。它允许输入图像和文本问题,并能够基于此回答问题。
首先,我们来看一下搭建好以后的问答示例。
代码,
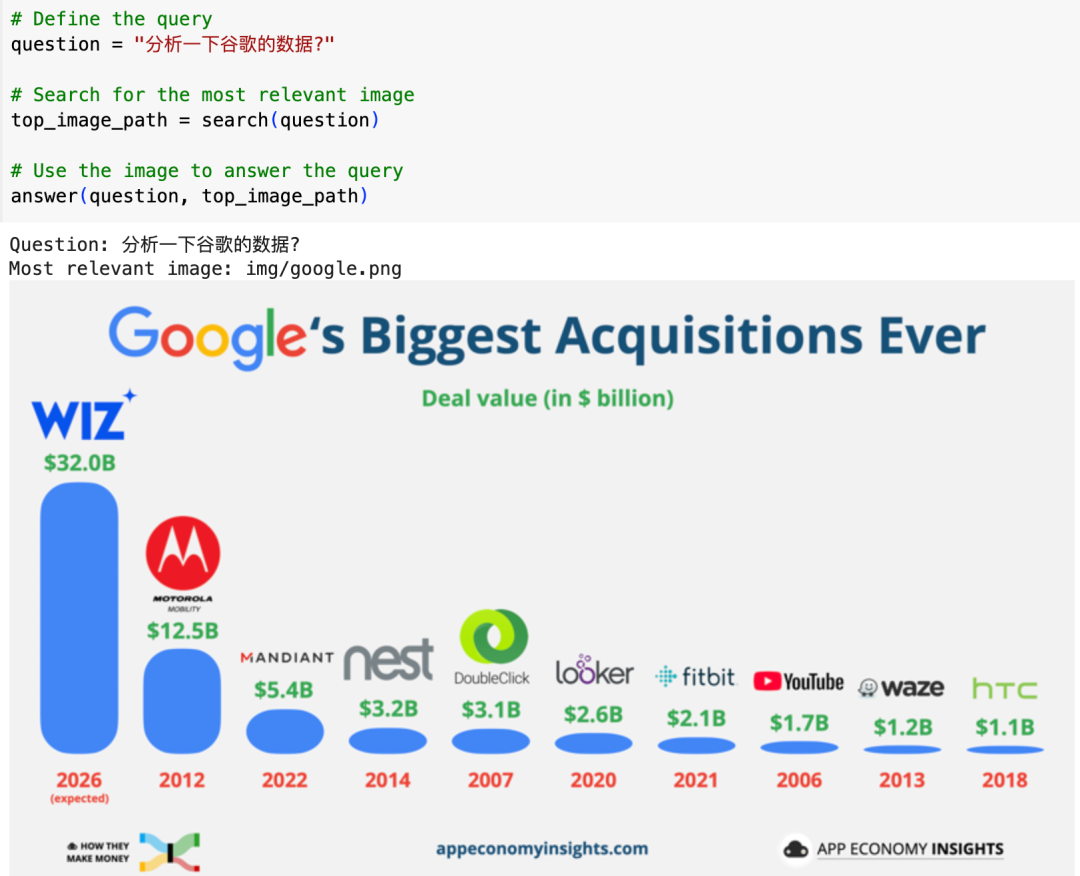
# 定义查询 queryquestion = "请用中文解释一下有鹅的图"# 搜索最相关的图像top_image_path = search(question)# 使用搜索到的图像回答查询answer(question, top_image_path)
根据搜索的图像回答如下,

这回答可以吧,竟然看出来了这张图像被上下颠倒过了。根据问题搜到库中的图像是 cohere 的功劳,解读这张图像是 Gemini 的功劳。
再来一张试试。
# 定义查询 queryquestion = "我记得有个图里有猫,请解释一下那个图是讲什么来着?"# 搜索最相关的图像top_image_path = search(question)# 使用搜索到的图像回答查询answer(question, top_image_path)
回答如下,
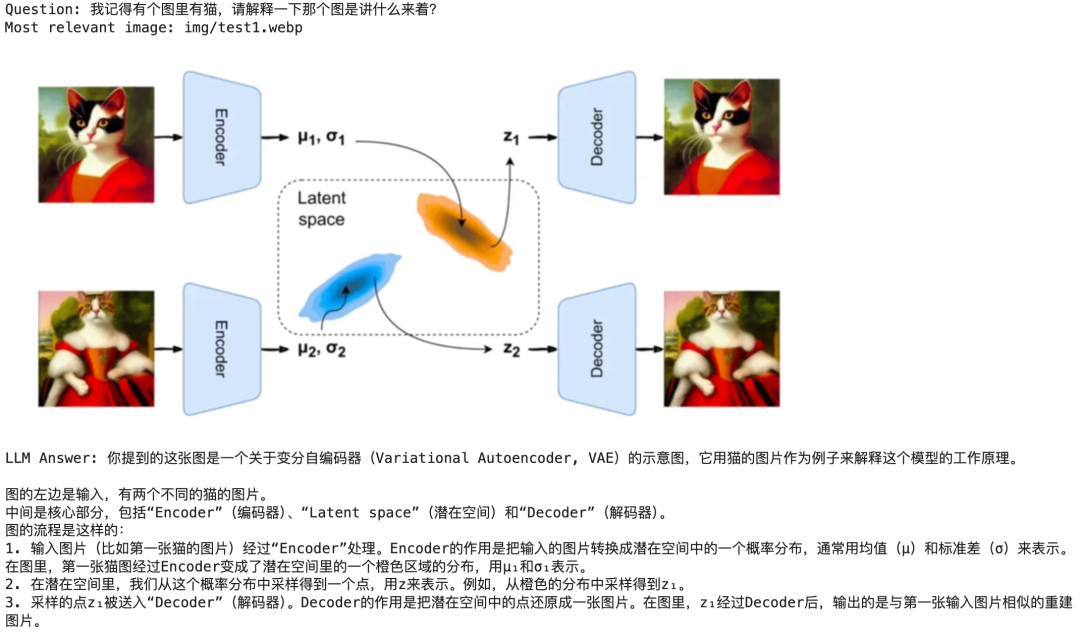

以下是安装和具体的代码。
访问 cohere.com,注册并获取 API key。
pip install -q cohere
# Create the Cohere API client. Get your API key from cohere.comimport coherecohere_api_key = "<<YOUR_COHERE_KEY>>" #Replace with your Cohere API keyco = cohere.ClientV2(api_key=cohere_api_key)
到 Google AI Studio 为 Gemini 生成一个 API 密钥。然后,安装 Google 生成式 AI SDK。
pip install -q google-genai
from google import genaigemini_api_key = "<<YOUR_GEMINI_KEY>>" #Replace with your Gemini API keyclient = genai.Client(api_key=gemini_api_key)
import requestsimport osimport ioimport base64import PILimport tqdmimport timeimport numpy as np# Some helper functions to resize images and to convert them to base64 formatmax_pixels = 1568*1568 #Max resolution for images# Resize too large imagesdef resize_image(pil_image):org_width, org_height = pil_image.size# Resize image if too largeif org_width * org_height > max_pixels:scale_factor = (max_pixels / (org_width * org_height)) ** 0.5new_width = int(org_width * scale_factor)new_height = int(org_height * scale_factor)pil_image.thumbnail((new_width, new_height))# Convert images to a base64 string before sending it to the APIdef base64_from_image(img_path):pil_image = PIL.Image.open(img_path)img_format = pil_image.format if pil_image.format else "PNG"resize_image(pil_image)with io.BytesIO() as img_buffer:pil_image.save(img_buffer, format=img_format)img_buffer.seek(0)img_data = f"data:image/{img_format.lower()};base64,"+base64.b64encode(img_buffer.read()).decode("utf-8")return img_data# 图像列表,有本地的,也有网络的。images = {"test1.webp": "./img/test1.webp","test2.webp": "./img/test2.webp","test3.webp": "./img/test3.webp","tesla.png": "https://substackcdn.com/image/fetch/w_1456,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fbef936e6-3efa-43b3-88d7-7ec620cdb33b_2744x1539.png","netflix.png": "https://substackcdn.com/image/fetch/w_1456,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F23bd84c9-5b62-4526-b467-3088e27e4193_2744x1539.png","nike.png": "https://substackcdn.com/image/fetch/w_1456,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa5cd33ba-ae1a-42a8-a254-d85e690d9870_2741x1541.png","google.png": "https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F395dd3b9-b38e-4d1f-91bc-d37b642ee920_2741x1541.png","accenture.png": "https://substackcdn.com/image/fetch/w_1456,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F08b2227c-7dc8-49f7-b3c5-13cab5443ba6_2741x1541.png","tecent.png": "https://substackcdn.com/image/fetch/w_1456,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0ec8448c-c4d1-4aab-a8e9-2ddebe0c95fd_2741x1541.png"}# 下载图像并计算每张图像的嵌入img_folder = "img"os.makedirs(img_folder, exist_ok=True)img_paths = []doc_embeddings = []for name, url in tqdm.tqdm(images.items()):img_path = os.path.join(img_folder, name)img_paths.append(img_path)# Download the imageif not os.path.exists(img_path):response = requests.get(url)response.raise_for_status()with open(img_path, "wb") as fOut:fOut.write(response.content)# Get the base64 representation of the imageapi_input_document = {"content": [{"type": "image", "image": base64_from_image(img_path)},]}# Call the Embed v4.0 model with the image informationapi_response = co.embed(model="embed-v4.0",input_type="search_document",embedding_types=["float"],inputs=[api_input_document],)# Append the embedding to our doc_embeddings listemb = np.asarray(api_response.embeddings.float[0])doc_embeddings.append(emb)doc_embeddings = np.vstack(doc_embeddings)print("nnEmbeddings shape:", doc_embeddings.shape)
看这些图像的嵌入:Embeddings shape: (9, 1536)。
以下展示了一个基于视觉的 RAG(检索增强生成)的简单流程。
-
首先执行 search():我们为问题计算嵌入向量。然后,我们可以使用该嵌入向量在我们预先嵌入的图像库中进行搜索,以找到最相关的图像,然后返回该图像。
-
在 answer() 中,将问题和图像一起发送给 Gemini,以获得问题的最终答案。
# Search allows us to find relevant images for a given question using Cohere Embed v4def search(question, max_img_size=800):# Compute the embedding for the queryapi_response = co.embed(model="embed-v4.0",input_type="search_query",embedding_types=["float"],texts=[question],)query_emb = np.asarray(api_response.embeddings.float[0])# Compute cosine similaritiescos_sim_scores = np.dot(query_emb, doc_embeddings.T)# Get the most relevant imagetop_idx = np.argmax(cos_sim_scores)# Show the imagesprint("Question:", question)hit_img_path = img_paths[top_idx]print("Most relevant image:", hit_img_path)image = PIL.Image.open(hit_img_path)max_size = (max_img_size, max_img_size) # Adjust the size as neededimage.thumbnail(max_size)display(image)return hit_img_path# Answer the question based on the information from the image# Here we use Gemini 2.5 as powerful Vision-LLMdef answer(question, img_path):prompt = [f"""Answer the question based on the following image.Don't use markdown.Please provide enough context for your answer.Question: {question}""", PIL.Image.open(img_path)]response = client.models.generate_content(model="gemini-2.5-flash-preview-04-17",contents=prompt)answer = response.textprint("LLM Answer:", answer)
然后,针对图像进行问答。
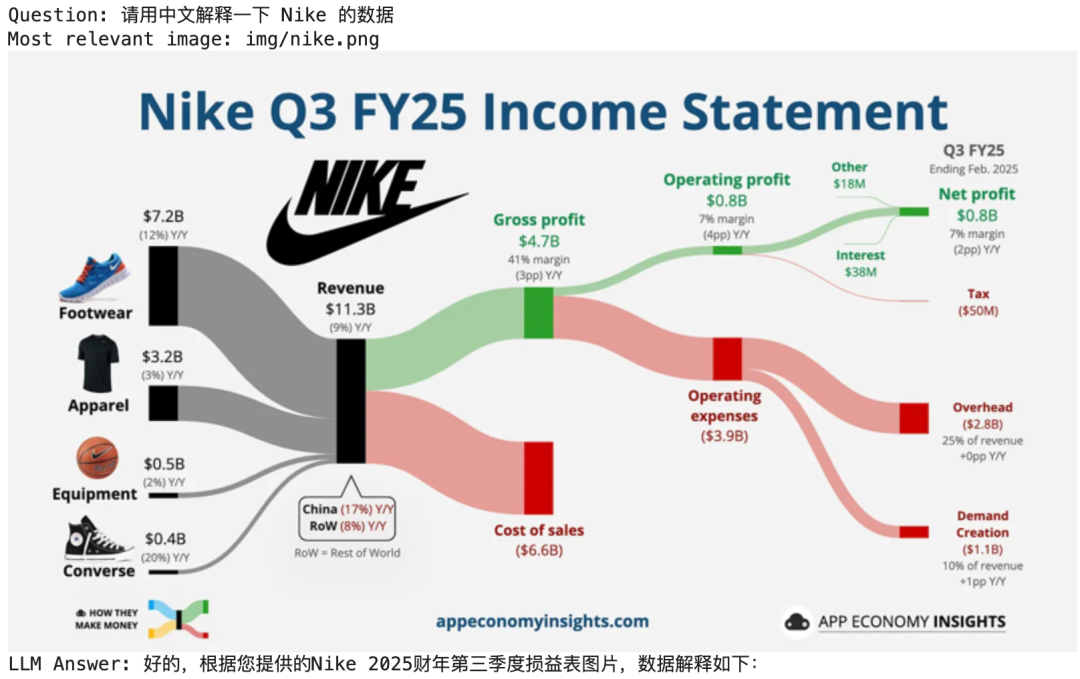
# Define the queryquestion = "请用中文解释一下 Nike 的数据"# Search for the most relevant imagetop_image_path = search(question)# Use the image to answer the queryanswer(question, top_image_path)
以下是回答,