

一周前分享了吴恩达|LLM何时进行微调?何时不进行微调?|拒绝技术自嗨式微调,吴恩达教授给出的最佳实践经验是“正式启动微调前,请确认是否已充分挖掘提示工程、RAG知识库、智能体工作流的潜力”。
而其中的【RAG知识库】一直也被称作是智能体的【第二大脑】”,对智能体的输出质量起到了举足轻重的影响。
本文,将深入探讨如何在dify中优化RAG过程的精度,包括:知识库的设置技巧及其背后的AI原理,为什么检索阶段采用了两段式结构?混合检索加Rerank有什么奥秘?在本文中都会一一给出答案。
一、知识库创建与分段参数设置
我们从最开始创建知识库开始,来到Dify的页面,点击[创建知识库],然后上传文件,建议上传MD文件,更有利于RAG“读懂”你的笔记。

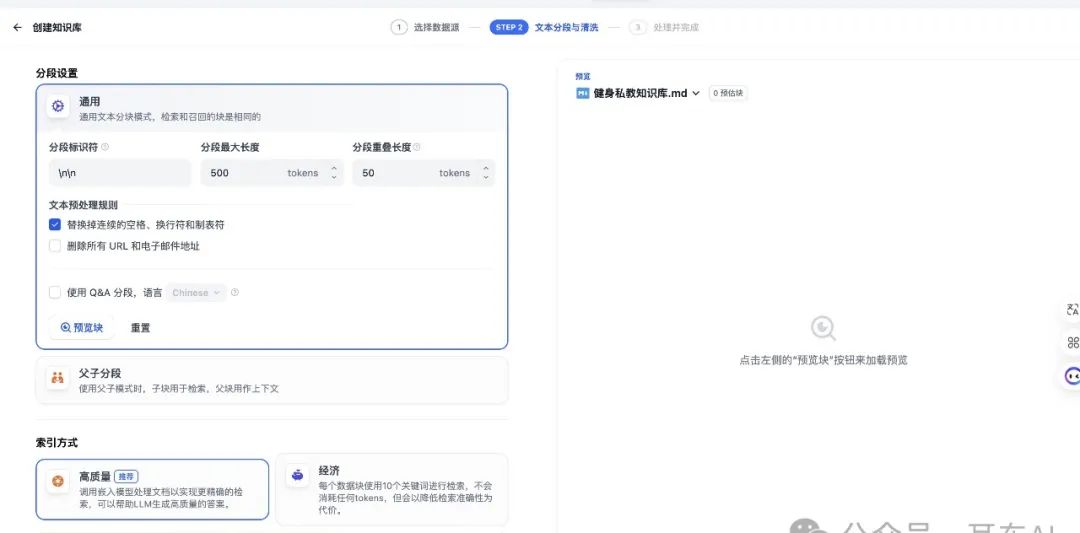
关键分段参数详解:
分段最大长度(Chunk Size)是最重要的参数之一。最佳长度要视情况而定,但可以参考一些测试结果。例如有篇关于Azure AI Search的测试,比较了512、1024、4096和8191四种Token长度的召回结果:
-
512 Token时召回率42.4% -
1024 Token时召回率41.7% -
4096 Token时召回率40.2% -
8191 Token时召回率39.8%
测试结果显示:512 Token长度表现最优,1024、4096和8191之间的召回率差异并不显著;
召回率计算方法:
假设检索到前50个文档中有10个高质量文档,而针对该查询应该有20个优质文档,那么召回率就是10/20=0.5(50%)。
分段重叠长度设置指的是允许段落间重叠,避免因分段而丢失语义。
划重点:测试显示,Token长度512并允许25%重叠时,召回率最高可达43.9%。
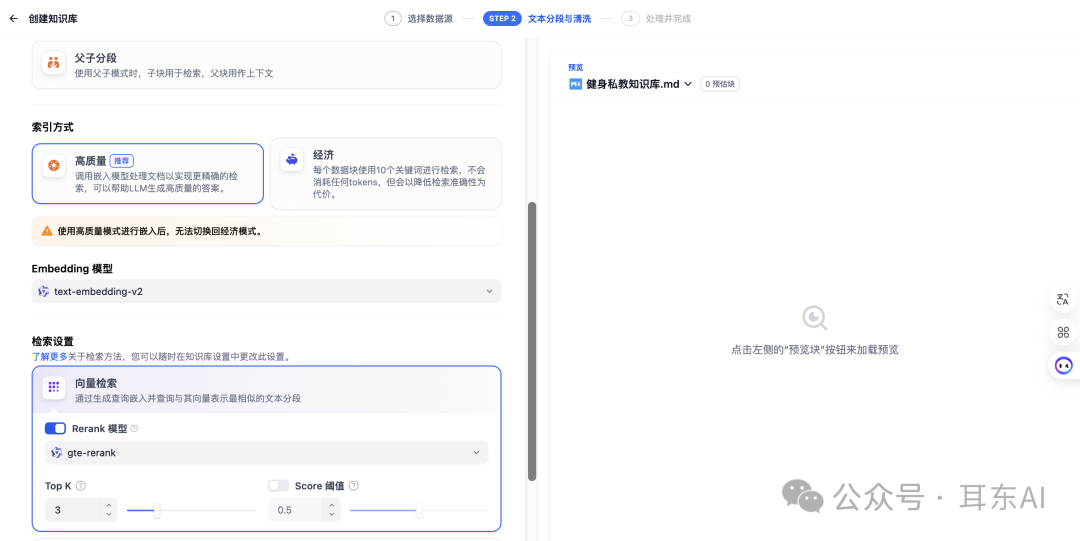
二、Embedding模型选择
在文本向量化的过程中,选择合适的嵌入模型也会影响RAG的效果精准度。
目前市场上有多种选择,主要可以分为两大类:
-
高端付费模型:以OpenAI的text-embedding-3-large为代表,这类模型通常具有更高的精度和更强的语义理解能力,适合对准确度要求较高且预算充足的项目。
-
免费开源模型:比如Dify平台提供的免费嵌入模型,虽然性能可能略逊于高端付费模型,但对于预算有限的项目来说是非常实用的选择。
因为我是本地部署的Dify,比较偷懒,嵌入的是通义千问的“通用文本向量-v3”
1. 向量检索的优势
向量检索是RAG的标配,擅长语义理解:
-
根据查询含义返回相关信息,即使文档中没有确切词语 -
对拼写错误、同义词和措辞差异不敏感 -
支持跨语言理解
例如搜索"最新iPhone旗舰机",向量检索能返回iPhone 16 Pro/Pro Max,即使没输入具体型号。
2. 关键词检索的优势
关键词检索(全文检索)擅长精确匹配:
-
快速找到包含确切关键词的内容 -
适合特定产品型号、技术术语等场景 -
基于TF-IDF(词频逆文档频率)算法
搜索"iPhone 16 Pro"时,关键词检索能精准找到包含该词组的文档,这是向量检索难以做到的。
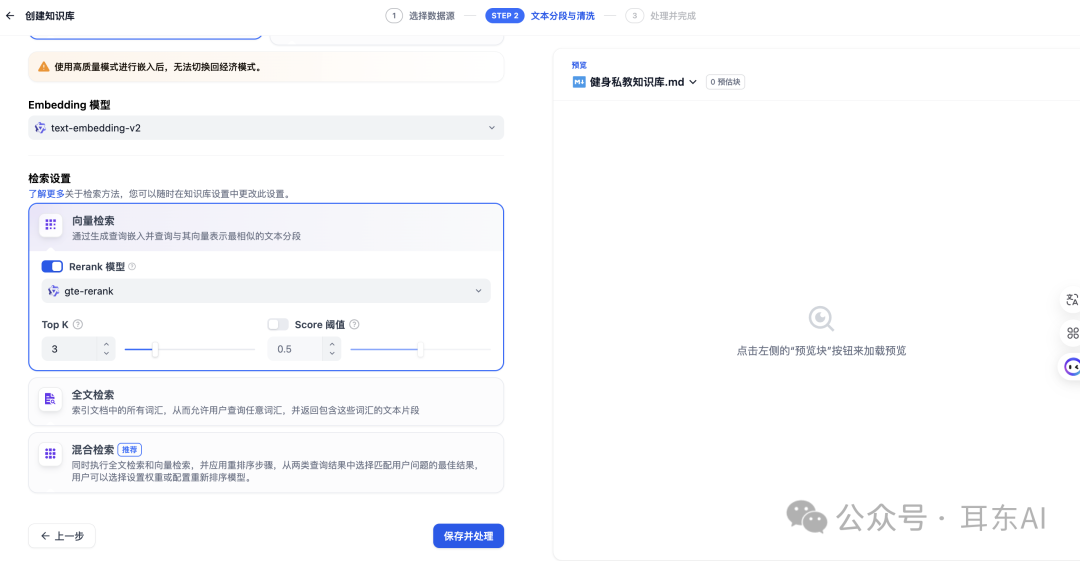
3. 混合检索的最佳实践
混合检索就是同时使用向量和关键词两种方法。
划重点:在Azure AI Search测试中,混合检索(Hybrid)得分比单独使用任一种都高,尤其是加上Semantic Ranker重排序模型后效果更佳。
四、Rerank重排提升检索准确性
Rerank(重新排序)是一种根据查询(Query)和文档的相关性打分并进行排序的技术。这项技术在检索系统中发挥着关键作用,能够更准确地排序返回的结果,从而提升用户体验。
2. Rerank与嵌入模型的区别
虽然Rerank看起来与嵌入模型的余弦相似度计算类似,但两者的实现原理存在明显差异:
双编码器模型(Bi-Encoder)
- 结构特点:
采用Bi-Encoder结构,通过两个神经网络分别生成查询和文档的向量表示。 - 实现方式:
通常使用相同的网络架构,可以理解为用同一个Embedding模型生成独立的向量。 - 优势
-
可以预先计算和索引文档的向量表示 -
查询时直接使用余弦相似度计算,极大提升速度 -
非常适合在大规模数据集上进行快速检索
- 局限性
-
文档信息被压缩成单一向量 -
查询时无法动态调整上下文 -
这种压缩可能导致信息丢失,影响检索精确度
交叉编码器(Cross Encoder)
- 工作原理
将查询(Query)和文档合并后输入同一个Transformer模型 - 特点
通过深度交互生成更高质量的相关性评分 - 优势
-
能够在具体查询的上下文下重新分析文档内容 -
生成的相关性分数更为精确
- 局限性
-
每次查询时都需要重新计算 -
速度较慢,不适合处理大规模数据集
3. 优化检索系统的最佳实践方案
在实际检索系统中,通常会结合Bi-Encoder和Cross Encoder的优点,以平衡速度与精度,典型的实现方式是采用二阶检索设计:
Dify中的四种典型检索配置
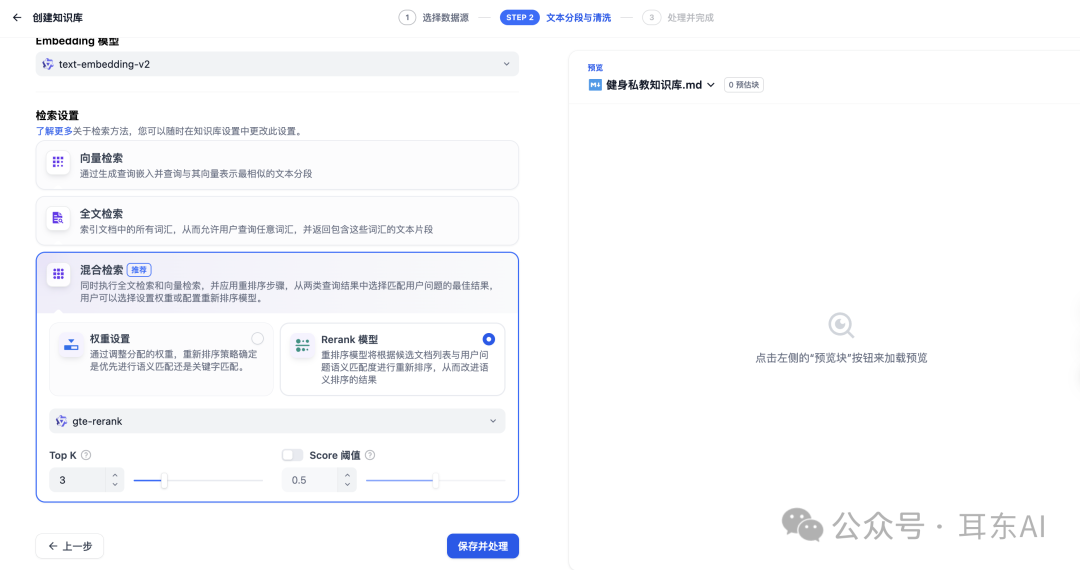
- 仅向量检索:
通过余弦相似度排序,设置Top K控制返回结果数量。 - 向量检索+Rerank:
Rerank模型优化第一阶段结果,可能将原本排名第五的文档提升至第二位。 - 全文检索+Rerank:
类似第二种,但第一阶段使用关键词检索。 - 混合检索+Rerank:
最强大的配置,可设置Score Threshold过滤低质量结果。
当需要检索多个知识库时,可以参考如下方式:
-
对各知识库分别进行混合检索 -
汇总所有结果 -
进行一次多知识层次的Rerank处理 -
通过Top K和Score Threshold筛选最佳结果
总结:通过合理配置Dify中的混合检索和Rerank模型,可以极大提升RAG系统的精度,从而帮助我们搭建更加优质的智能体。
