

在人工智能技术迅猛发展的当下,Retrieval-Augmented Generation(RAG,检索增强生成)凭借其将信息检索与文本生成相结合的独特优势,已成为企业和开发者构建智能应用的重要技术选择。然而,在实际应用过程中,许多开发者常常面临一个令人困扰的问题:明明采用了先进的RAG框架,生成的结果却时常出现"文不对题"或"逻辑混乱"的情况。经过深入分析发现,这些问题往往源于一个被忽视的关键环节——文档预处理的质量。本文将系统解析RAG技术的工作原理,揭示影响其性能的关键因素,并着重探讨如何通过优化文档预处理流程(包括标准化文档结构、提升文本质量等)来充分释放RAG的技术潜力。
RAG技术的核心竞争力在于其能够从海量知识库中精准检索相关信息,但如果基础文档存在格式混乱、内容冗余或结构缺失等问题,即便最先进的算法也难以发挥应有水平。当前实践中主要存在以下几大典型挑战:
-
文档格式杂乱:知识库中可能包含PDF、Word、网页、Markdown等多种格式,结构不统一,导致检索时信息提取困难。
-
内容质量参差:文档可能包含冗余、过时或低质量内容,干扰检索准确性。
-
语义不清晰:文档缺乏明确的标题、段落划分或关键词标注,AI难以理解内容与查询的关联性。
案 例
近期帮助客户把一批文档录入到AI知识库系统进行问答效果验证,上传的过程中发现了一些实际的问题。
文档标注前后对比
-
原始文档(分段不准确,内容被截断)
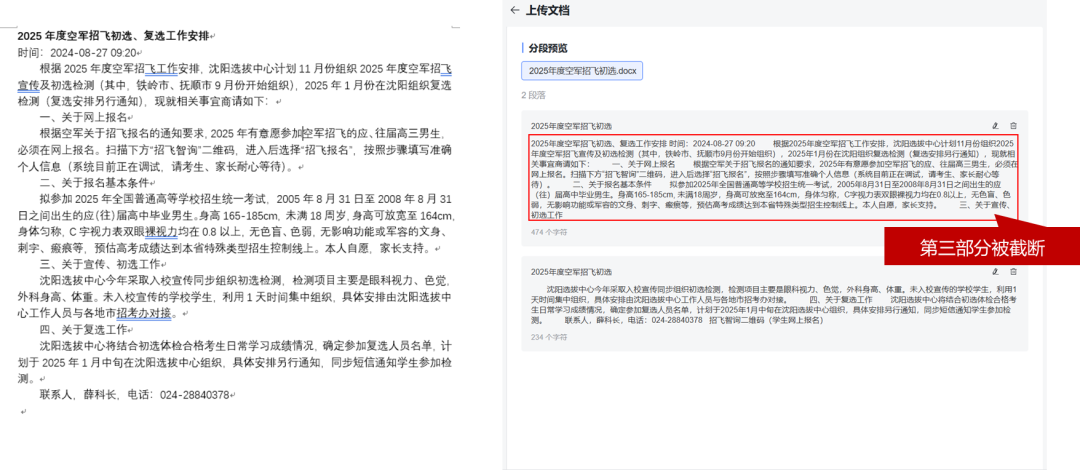
-
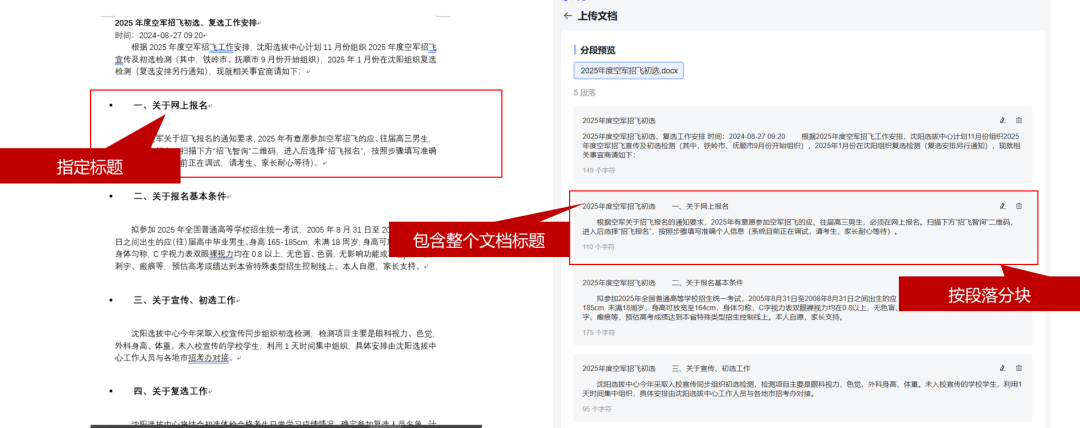
声明段落后的文档(分段包含层次结构,以及相对完整的内容)
表格文档标注前后对比
-
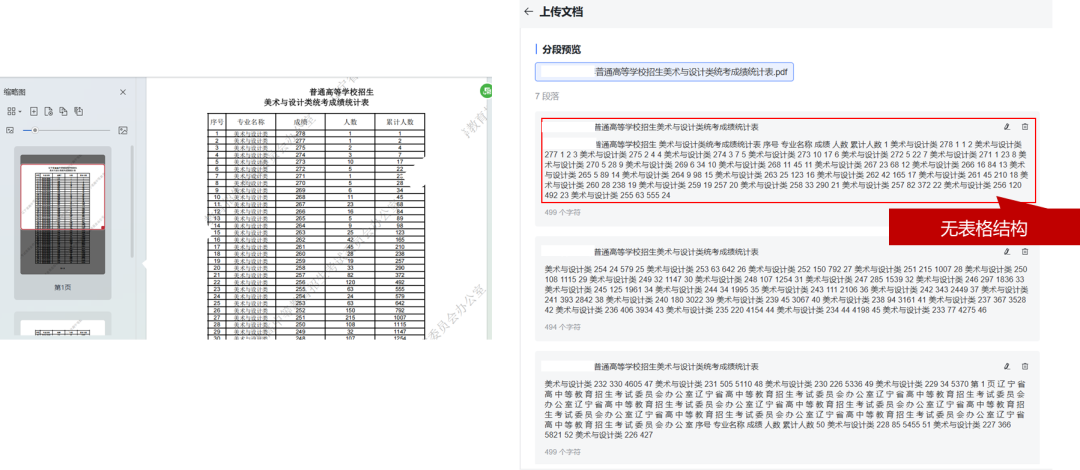
PDF表格文档(无法识别表格结构)
-
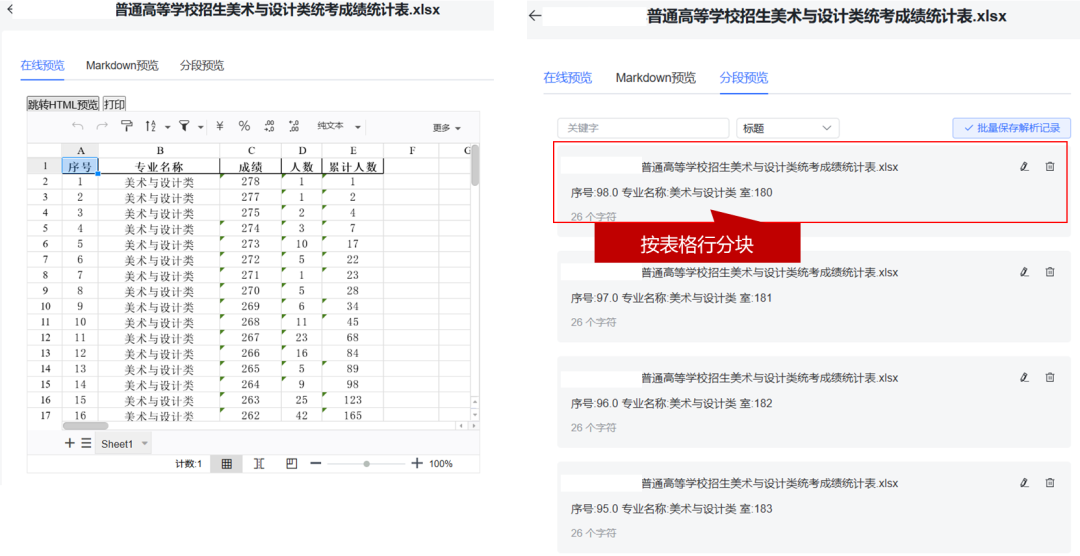
更改为Excel表格文档(按行分段)
文档解析分段过程中发现的关键问题
-
Word中包含表格(规则、不规则)
-
Word中包含图片
-
Word中包含图表
-
PDF文档布局排版
-
PDF文档表格、图片、图表
-
文档中的层级关系
-
文档中的文图链接(多跳情况)
关键策略
-
标准化预处理:将知识库中的文档统一转换为Markdown结构化的格式,包含段落、图片、文档中的表格,便于AI解析,支持清晰的标题层次结构,段落。例如,Markdown的层级标题(#、##)能帮助AI快速定位内容。
-
结构化文档采用行存,采用明确语义的字段标题。
-
规范化命名:为文档设置统一的能够最大反应主题的命名规则,如“[部门]-[主题].docx”,便于检索和管理。
-
特殊文档特殊处理,比如法律条款、Q&A、单篇内容聚合等,人为指定解析规则进行上传。
-
多维度结构化的事实数据可以考虑利用知识图谱进行存储,揭示知识之间的关联性,当用户查询与特定节点或边匹配时,相关连接的节点/边也可以加起来,为响应提供更多上下文。
针对上述策略,在应用系统开发过程中采用以下功能尝试解决与实现。
非结构化文档预处理
-
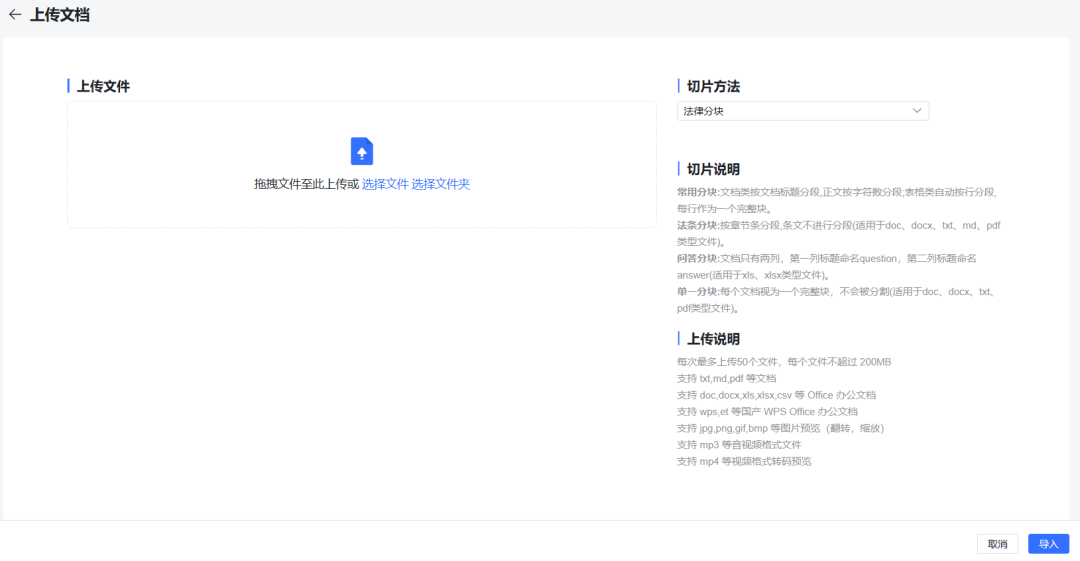
上传文档,上传过程中人为选择切片方法
-
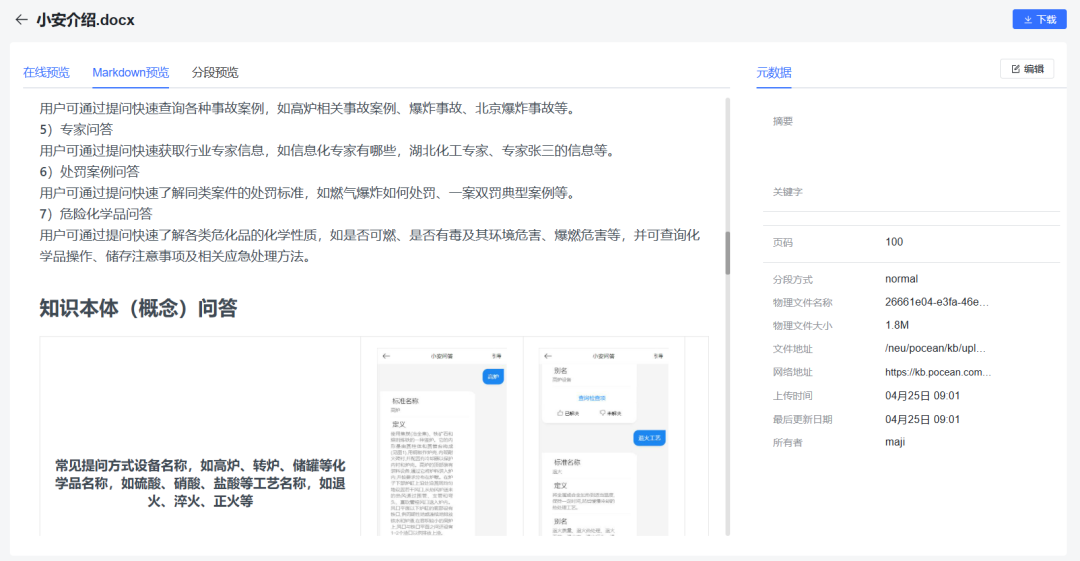
MARKDOWN文档预览,支持同时提取段落、表格和图片
-
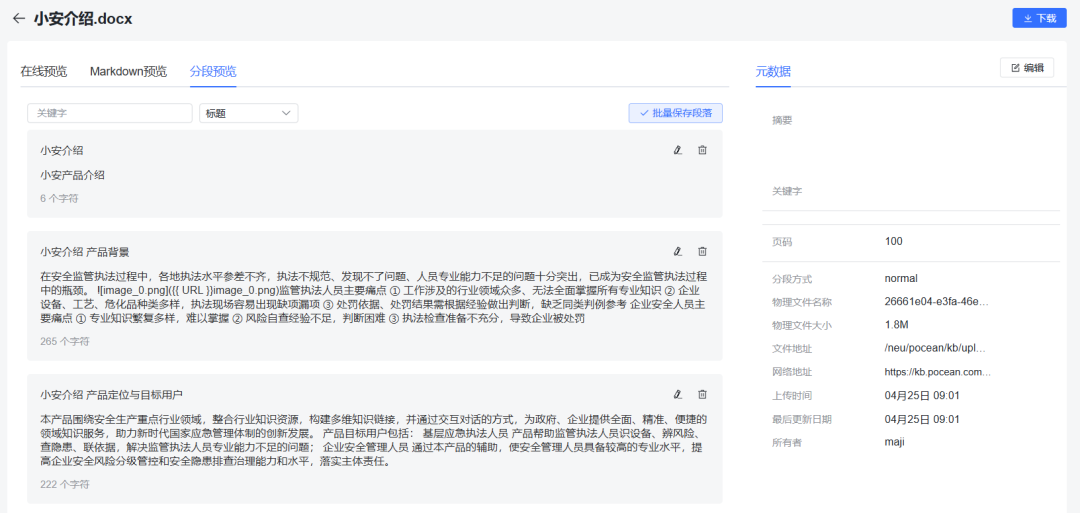
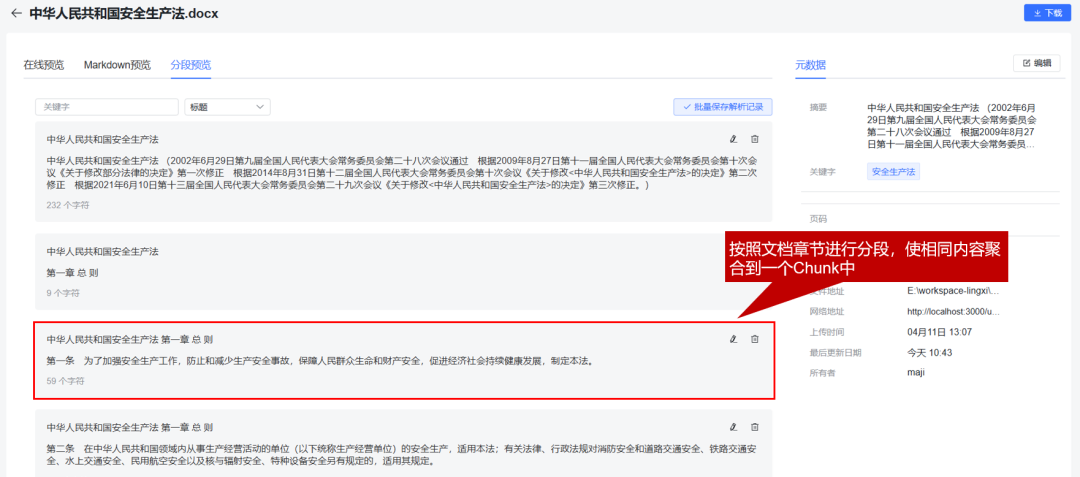
分段预览,包含文档名称、段落层次以及段落内容,都作为向量进行存储。
知识图谱数据预处理
目前利用AI从非结构化文档中提取知识图谱依然面临着较大的不确定性以及人工审核成本,所以个人看法知识图谱的实际落地应用目前还是应该以结构化数据为主,将多维度的关联性数据导入到知识图谱中,进行基于实体和关系的问答或者复杂推理。
-
问答效果
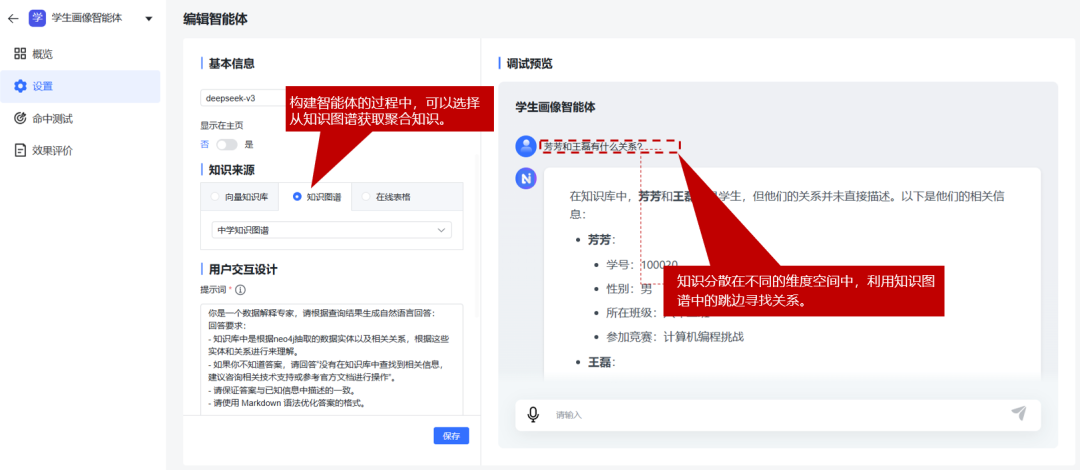
-
实体及关系展示
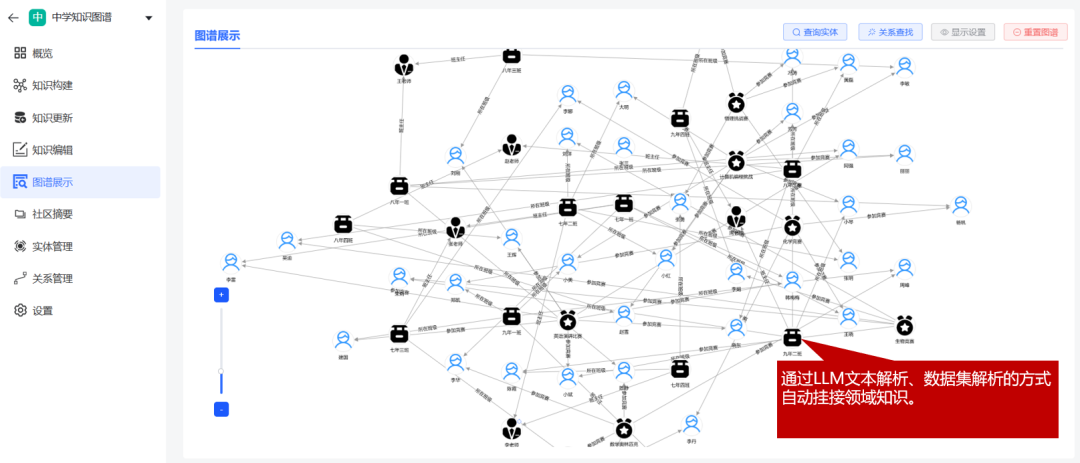
结语
-
语料加工是RAG中的一个十分重要环节,其属于龙头地位,加工的程度和质量,直接影响知识问答效果;
-
怎么把文档挖得好,挖的深,纵使有很多工具,但依旧无法脱离人工的成分,要保证质量可信的话,需要人进行check;
-
知识图谱是另一种形式的规则知识文档,可作为一个规范/实施引导大模型做可控性生成。
-
利用结构化知识,构建场景知识图谱,进行Cyther图检索辅助大语言模型做问答。
