

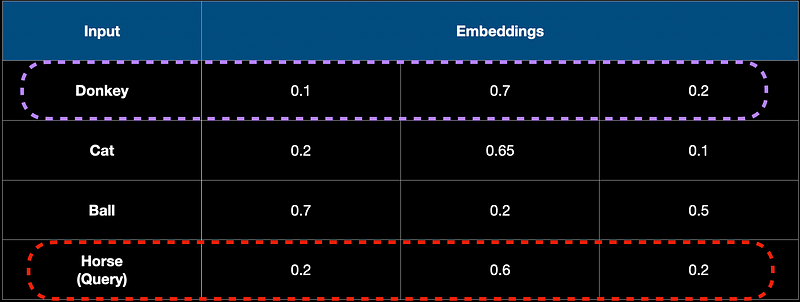
.01
-
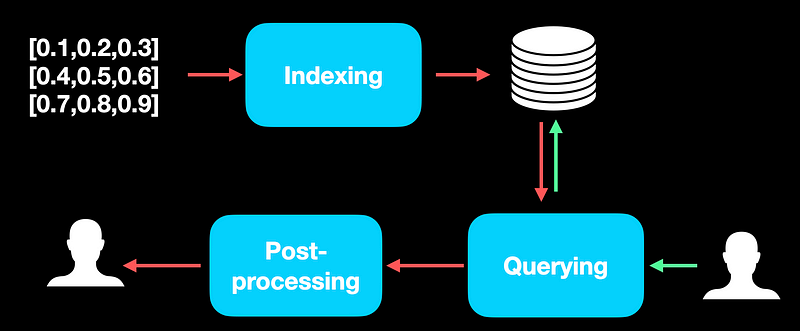
索引构建(Indexing) -
查询处理(Querying) -
后处理(Post-Processing)
-
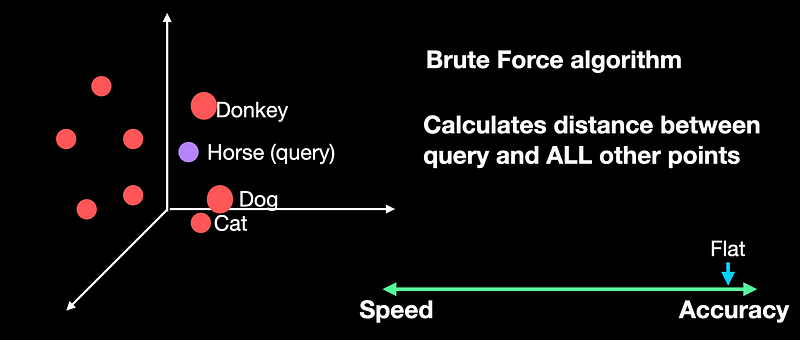
优点:精度最高,适合对查询结果要求极高的场景。 -
缺点:速度慢,尤其在高维数据和大规模数据集上。

-
特点:适合处理包含大量相似向量的大型数据集。 -
挑战:哈希函数和桶大小的选择直接影响性能。
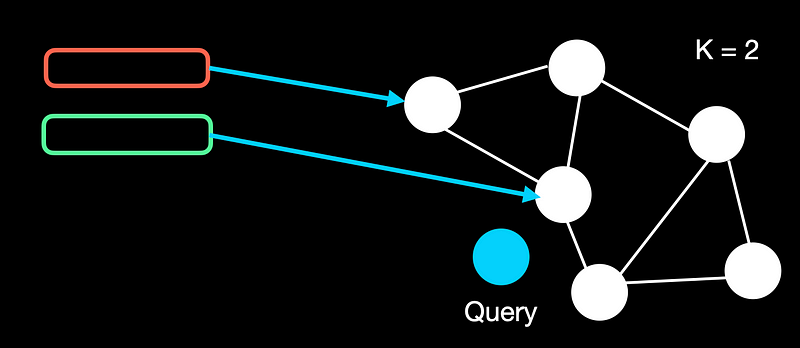
-
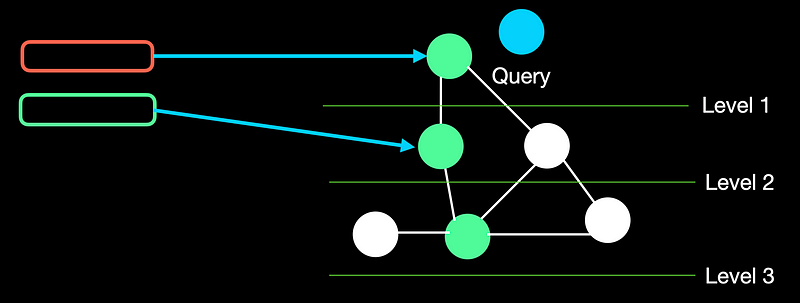
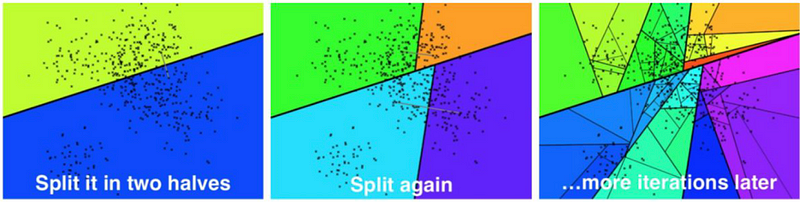
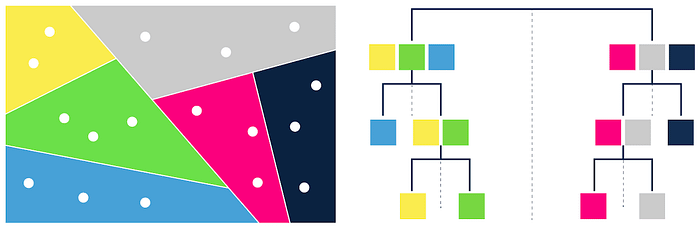
工作原理:查询时从顶层随机节点开始,逐层向下搜索相似节点,最终在底层找到最相似的向量。 -
优势:高效处理大规模数据,查询速度快。
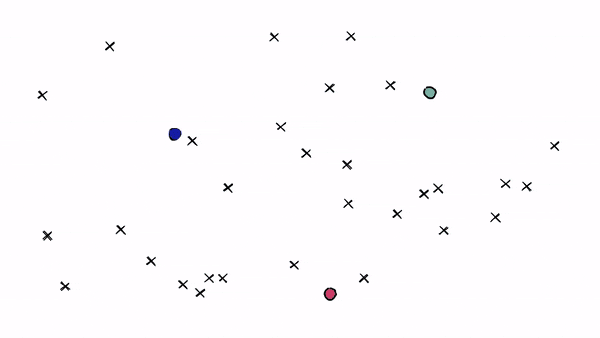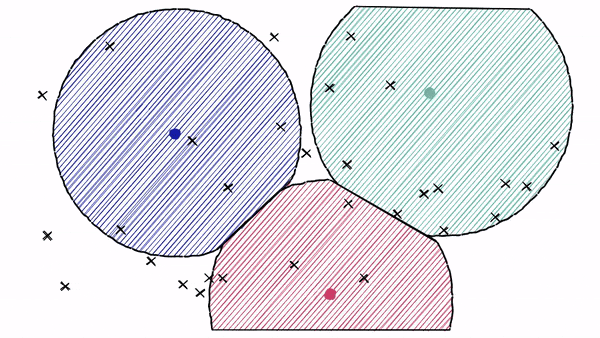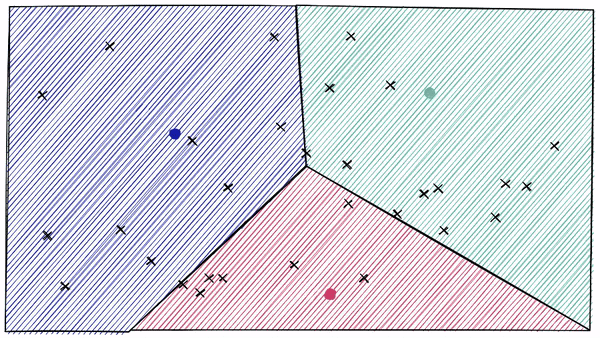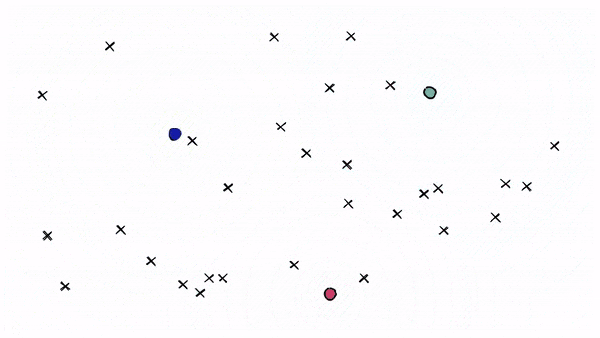
-
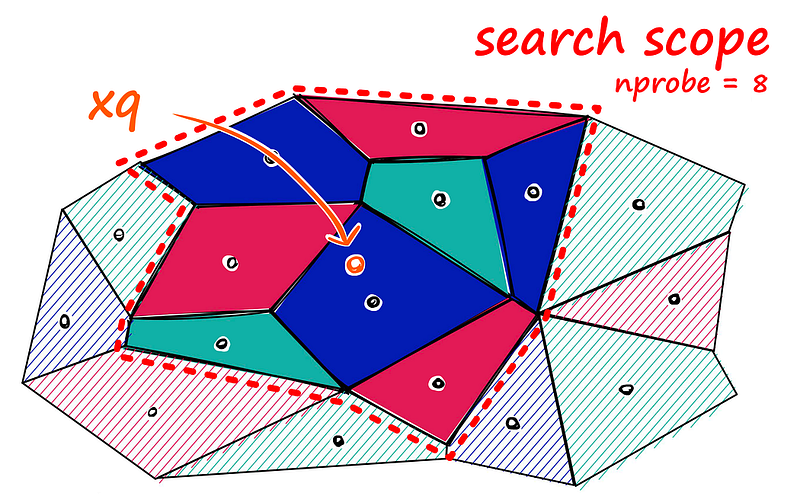
特点:通过控制簇的数量(nprobes)权衡精度与速度。 -
应用:适合中等规模数据集的快速查询。

-
优点:显著减少存储需求,同时保持相似性信息。 -
适用场景:需要在存储和性能之间寻求平衡的应用。
-
特点:轻量、高效,特别适合小型数据集或实时场景。
-
优点:大幅减少维度,同时保留查询的准确性。 -
应用:适合维度极高的数据集。
-
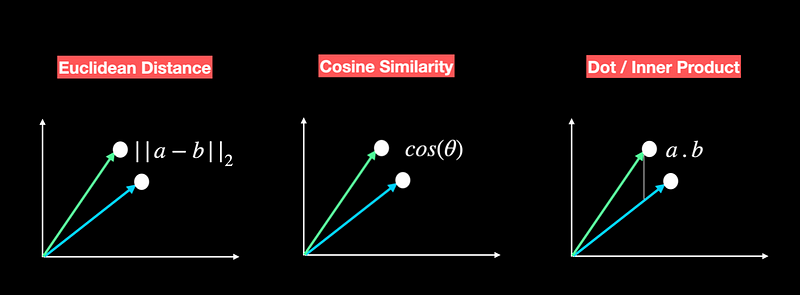
点积(Dot Product):衡量两个向量间的点积值,适合高维空间的相似性计算。 -
余弦相似度(Cosine Similarity):计算向量间夹角的余弦值,范围从-1到1。 -
欧几里得距离(Euclidean Distance):计算两向量间的直线距离,用于衡量绝对相似性。
