

之前笔者已经介绍了如何通过 Chunking 和 Embedding 来优化 RAG 系统。今天我们来聊聊评估 RAG 系统性能的指标体系。我们的重点会放在评估大模型的输出的指标上。
在优化基于检索增强生成(Retrieval-Augmented Generation, RAG)的系统时,明确性能评估方法是关键的一步。本篇文章将围绕 RAG 系统的评估指标展开,重点探讨如何通过科学评估优化系统性能。
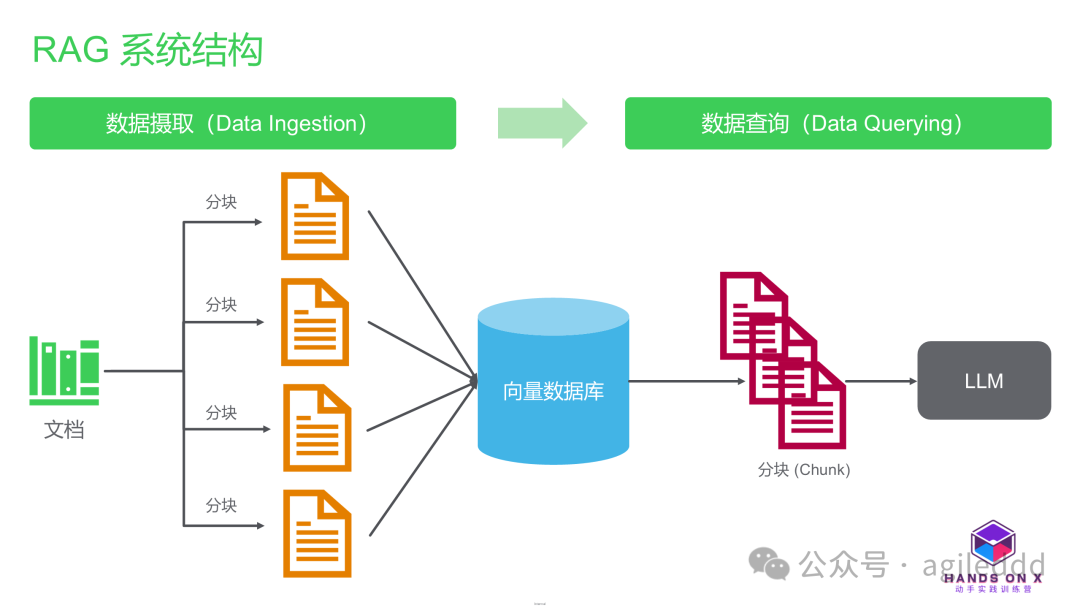
1. RAG 的基本组成部分
RAG 系统通常由两个主要阶段组成:
1.1数据摄取(Data Ingestion):
-
将结构化或非结构化数据转化为适合向量数据库的形式。 -
数据准备的典型步骤包括清洗、分词、嵌入生成等。 -
举例:对新闻文章进行分块处理并生成嵌入以便后续检索。
1.2数据查询(Data Querying):
-
检索(Retrieval): 从向量数据库中提取与用户查询相关的内容。 -
合成(Synthesis): 将检索内容与用户查询结合,通过大模型生成最终回答。 -
应用场景: 包括客户支持、企业知识问答系统等。
2. 如何评估 RAG 的性能
优化 RAG 系统的关键是定义合适的评估指标,并基于这些指标改进系统设计。
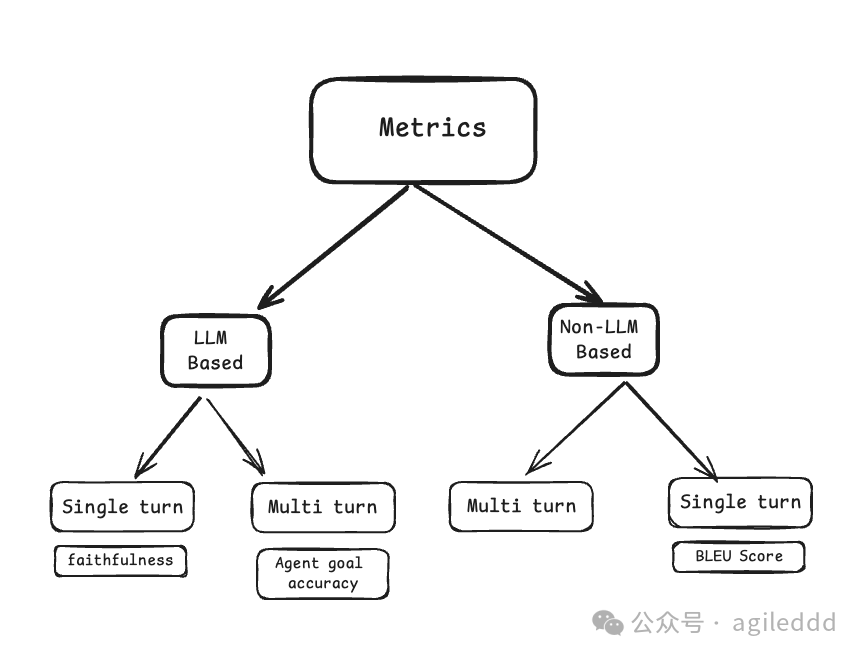
2.1确定指标评估 RAG 系统时常用两类指标:
-
基于 LLM 的指标:
-
通过调用大语言模型(LLM)进行评估,例如利用其判断回答的质量、相关性等。 -
优点:与人类评价高度相关,适合复杂语言任务。 -
缺点:结果可能存在一定的不确定性,因 LLM 输出具有随机性。 -
非 LLM 的指标:
-
依赖传统方法,如字符串相似度、BLEU 分数等。 -
优点:结果确定性强,适合系统开发和早期调试阶段。 -
缺点:在复杂语言任务上的表现与人类评价相关性较低。
2.2准备评估数据集为了评估 RAG 系统,需要一个高质量的测试数据集,其中包括用户查询与正确答案的匹配对。构建数据集时需注意以下几点:
-
来源: 数据可以来源于真实用户交互日志,也可以通过人工标注或使用 LLM 合成。 -
多样性: 确保问题类型、复杂性和领域的多样性,以测试系统的广泛适用性。 -
规模: 数据集应包含足够多的样本,以确保评估结果具有统计显著性。 -
验证: 对于自动生成的数据,需引入人工或其他模型验证环节,确保答案质量。
举例:构建一个企业知识问答数据集,可以从实际客服记录中提取常见问题,并手动或自动生成答案。
3. 评估大模型的输出结果的四大类指标
在评估 RAG 系统时,之所以需要特别关注大模型输出结果相关的指标,是因为这些指标直接反映了最终用户体验的质量。与基于 LLM 的指标和非 LLM 的指标相比,前者更能捕捉复杂语言任务的细微差异,例如回答的依托性和相关性,而后者则擅长提供确定性的基准评估。在 2.1 部分中,我们已经讨论了这两类指标的优缺点。本节将从更实际的角度出发,通过具体的四大类指标分析如何优化 RAG 系统的输出质量。
3.1Groundedness(依托性/真实性)
-
定义: 检查生成的回答是否基于检索到的上下文,而非凭空生成(幻觉)。 -
方法: -
基于上下文嵌入计算生成回答与原始内容的相似度。 -
使用 LLM 自动打分,判断回答是否引用了检索内容。 -
重要性: 在知识密集型场景(如医学、法律问答)中,确保回答的依托性至关重要。 -
优化建议: 提升检索内容的质量,同时优化模型的提示词以减少幻觉。
3.2Completeness(完整性)
-
定义: 回答是否全面覆盖了用户查询的所有需求。 -
方法: -
基于检索内容与生成回答的覆盖率评分。 -
使用 LLM 逐项检查问题中的每个子问题是否得到解答。 -
重要性: 在需要回答复杂、多步骤问题的场景中尤为关键。 -
优化建议: 增强检索阶段对多样化内容的覆盖能力,或调整生成策略以综合回答多个维度的问题。
3.3Utilization(利用率)
-
定义: 衡量每个检索片段对最终回答的贡献。 -
方法: -
对每个检索内容片段,评估其在最终回答中的体现。 -
计算检索内容与生成回答的匹配率。 -
重要性: 高利用率意味着更高效的检索与生成过程,避免资源浪费。 -
优化建议: 如果利用率低,可以分析无效片段并调整检索策略或嵌入生成方法。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
• 检查你的分块策略,以增加数据块内的上下文 • 增加数据块数量 • 评估是否有未返回的数据块可以提高完整性。如果有,调查它们未被返回的原因 • 遵循完整性部分的指导 |
• 检查你的分块策略,以增加数据块内的上下文。如果使用固定大小的数据块,考虑增加数据块大小。 • 调整你的提示以改进回复 |
3.4Relevance(相关性)
-
定义: 回答是否与用户问题直接相关。 -
方法: -
基于嵌入计算回答与问题的相似度。 -
使用 LLM 判断回答内容是否聚焦于问题本身。 -
重要性: 在用户问题较为模糊或检索信息噪声较高时,相关性尤为重要。 -
优化建议: 优化向量数据库的构建与检索算法,确保返回内容的高相关性。
4. 案例分析:如何用评估指标改进 RAG 系统
假设我们正在优化一个企业知识问答系统:
-
背景: 用户需要查询公司政策相关信息。 -
问题: 系统生成的回答偶尔出现虚假信息,或者遗漏关键信息。
通过评估:
-
Groundedness: 检查发现部分回答未引用检索内容,调整提示词以减少幻觉。 -
Completeness: 通过分析未解答的子问题,优化检索阶段的多样性。 -
Utilization: 识别部分低利用率的检索片段,重新生成嵌入或改进分块策略。 -
Relevance: 提升检索算法的精准度,减少噪声内容干扰。
5. 结论
在 RAG 系统的优化过程中,科学合理的评估指标是成功的关键。通过 Groundedness、Completeness、Utilization 和 Relevance 四大类指标,开发者可以多维度地了解系统的性能,并有针对性地进行改进。
未来,随着评估工具的进步与指标的完善,RAG 系统的优化将变得更加高效和精准。这不仅有助于提升系统性能,也为更广泛的实际应用奠定了基础。
