

今天分享的是解决检索增强生成系统中预检索信息差距的一个方法:ERRR。

论文链接: https://arxiv.org/pdf/2411.07820v1

01
简介

02
框架
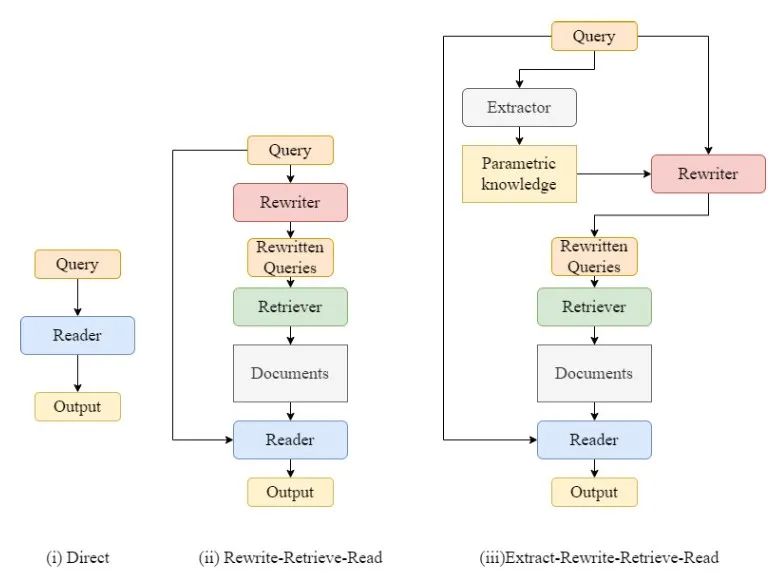
ERRR 的整体框架如上图 (iii) 所示,其主要由参数知识提取 (Parametric Knowledge Extraction)、查询优化 (Query Optimization)、检索 (Retrieval) 和生成 (Generation) 这四部分组成。下面详细介绍每一组成部分。
1. 参数知识提取 (Parametric Knowledge Extraction):
-
目标:从LLM中提取与原始查询相关的参数知识,以便为后续的查询优化提供重要的上下文信息基础。 -
方法:使用直接提示,让LLM生成包含与原始查询相关的背景信息的伪上下文文档。
2. 查询优化 (Query Optimization):
-
目标:根据参数知识和LLM的特定知识需求,生成一个或多个经过优化的查询,其能更准确地反映LLM的知识需求和用户的查询意图,以便检索到更相关的文档。 -
方法:使用LLM作为查询优化器,并通过提示生成优化查询。此外,为了提高灵活性和降低计算成本,文章还提出了一个可训练的方案,该方案使用一个较小的可调整模型作为查询优化器,并通过知识蒸馏从大型教师模型中进行精炼。
3. 检索 (Retrieval):
-
目标:根据优化查询检索相关文档,作为LLM生成答案的依据。 -
方法:为了提高框架在各种检索系统和数据源之间的适应性,该框架提供了两种不同的检索系统。 -
Web 搜索工具: 例如 Google 或 Brave Web Search Engine。 -
本地密集检索系统: 例如 Dense Passage Retrieval (DPR)。
4. 生成 (Generation):
-
目标:使用LLM根据检索到的文档和原始查询生成最终答案。
-
方法:使用指令提示与示例性提示,让LLM生成最终答案: -
指令性提示:直接告诉LLM阅读器使用检索到的文档和原始查询来生成答案。 -
示例性提示:为每个数据集,提供几个示例,说明如何使用检索到的文档和原始查询来生成答案,以保持对LLM对不同任务的特定输出格式的控制。

03
总结
