

今天分享的是一篇由人大、快手发布的文章:
DMQR-RAG: 基于多样化查询重写的检索增强生成


01
论文概述
1. 查询重写:用户查询经常包含噪声和意图偏差,直接检索往往无法获得足够相关的文档。因此,查询重写对于检索到相关文档非常关键。
2. 检索增强生成(RAG):RAG通过检索和整合外部知识来增强LLMs。然而,由于原始查询中的噪声和意图偏差,直接检索常常失败。

02
相关工作
论文中提到的相关研究可以分为两大类:基于训练的方法(training-based methods)和基于提示的方法(prompt-based methods)。
基于训练的方法(Training-based Methods)
-
RQ-RAG:构建了一个包含搜索查询和重写结果的创新数据集,用于训练一个端到端模型来优化搜索查询。
-
RRR:提出了一种新颖的训练策略,利用响应模型的性能作为奖励,通过强化学习优化检索查询。
基于提示的方法(Prompt-based Methods)
-
Hyde:利用LLMs为原始查询提前生成一个伪答案,这个伪答案在语义上更接近正确答案,有助于检索正确的结果。
-
Step-back Prompting:通过在更高概念层面上重写具有广泛细节的查询,以检索更全面的答案。 -
Least-to-most prompting:将复杂查询分解为几个较易处理的子查询,分别检索以收集回答原始查询所需的所有文档。
这些相关研究构成了DMQR-RAG框架的理论基础和方法论背景,旨在通过多样化的查询重写来提高检索增强生成的性能。

03
核心内容
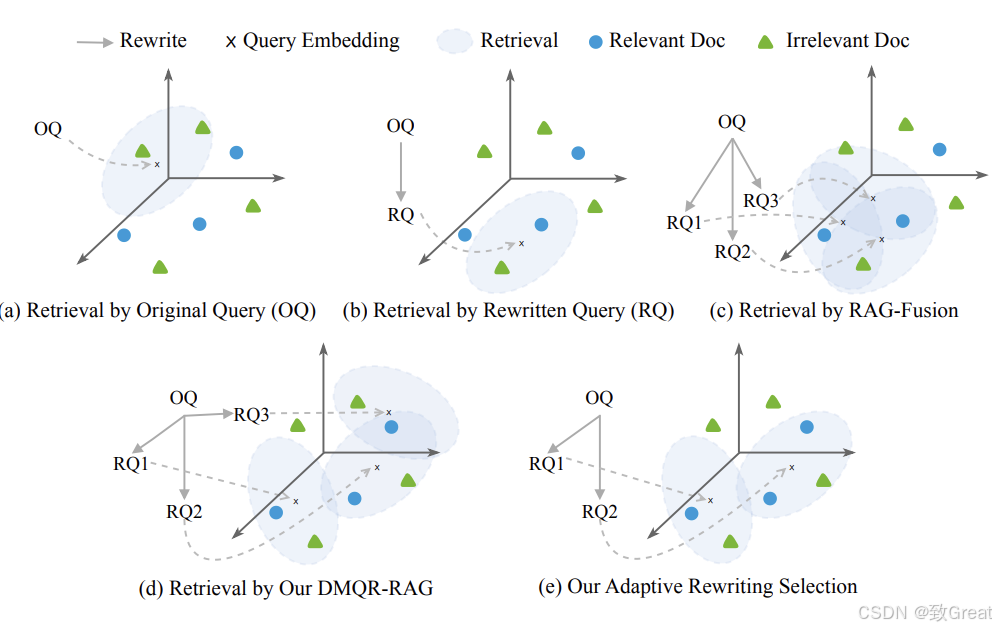
1. 多查询重写策略(Multi-Query Rewriting Strategies)
-
信息平等(Information Equality): -
一般查询重写(General Query Rewriting, GQR), 去除噪声,提炼原始查询,同时保留所有相关信息。 -
关键词重写(Keyword Rewriting, KWR), 从查询中提取关键词,特别是名词和主题,以快速定位相关文档。 -
信息扩展(Information Expansion):伪答案重写(Pseudo-Answer Rewriting, PAR), 利用LLMs的先验知识为检索生成伪答案,丰富原始查询。 -
信息缩减(Information Reduction):核心内容提取(Core Content Extraction, CCE), 去除查询中的多余细节,提取关键信息。
2. 自适应重写策略选择(Adaptive Rewriting Strategy Selection)
3. 标准化的重写评估设置

04
论文实验
1. 数据集(Datasets)
-
使用了三个代表性的开放域问答数据集:AmbigNQ、HotpotQA 和 FreshQA。
-
还包括了来自工业界的数据集。
2. 评估指标(Metrics)
-
检索效果使用Top-5命中率(H@5)和精确度(P@5)。 -
对于端到端响应,使用官方评估方法,包括精确匹配(EM)、F1分数和准确度(Acc)。
3. 基线方法(Baselines)
4. 主要结果(Main Results)

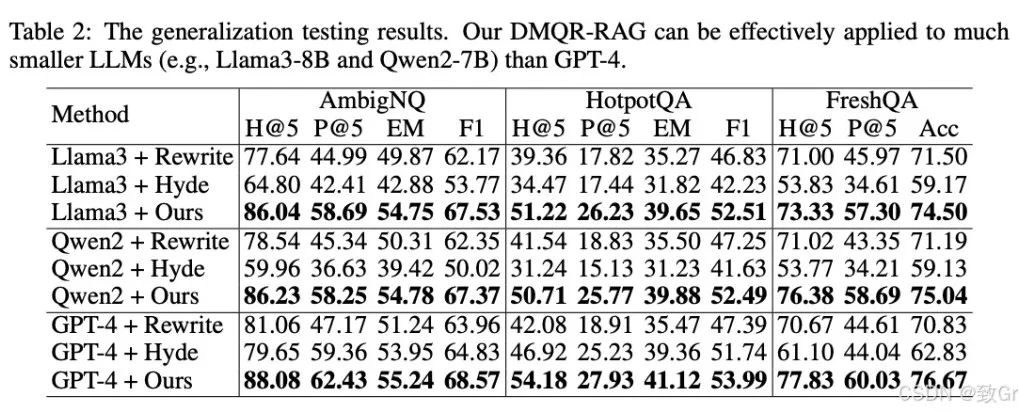
-
原始查询的重要性:原始查询(OQR)在某些场景下可以准确表达用户意图,并提供有助于文档检索和端到端响应的上下文。这表明,将原始查询与其重写版本结合在检索策略中是合理且有效的。 -
多重查询重写的优势:相比单一查询重写,多重查询重写表现更优。在文档检索任务中,DMQR-RAG方法在所有数据集上的表现均优于现有的重写方法。例如,在FreshQA数据集上,DMQR-RAG相较于最佳基线的P@5提升了14.46%。 -
在复杂问题上的表现:在HotpotQA这样的复杂多跳问题中,DMQR-RAG显著提高了检索性能,P@5提升约8%,说明该方法适用于多种类型的查询,具有较强的通用性。 -
端到端响应性能:在端到端响应任务中,DMQR-RAG超越了最佳基线方法Hyde。在AmbigNQ数据集上,EM和F1分别提高了1.30%和3.74%;在FreshQA数据集上,准确率比Rewrite提升了5.84%。这表明,DMQR-RAG的检索结果能够为响应模型提供准确的外部知识,从而显著提升响应性能。 -
与RQRAG的比较:尽管RQRAG针对复杂多跳问题进行了专门设计,并在HotpotQA上取得最佳效果,但DMQR-RAG在各类查询中仍表现出色,展现了良好的通用性。 -
与RAG-Fusion的比较:DMQR-RAG整体优于RAG-Fusion,尤其在AmbigNQ数据集上,P@5提升约10%。此外,通过自适应的重写选择机制,DMQR-RAG在更具挑战性的场景下进一步展现了其优越性。

05
问题讨论
