RAG(Retrieval Augmented Generation)作为大模型最火热的应用之一,最初是为了解决 LLM 的各类问题的(如超长上下文)产生的,但后面大家发现在现阶段的很多企业痛点上,使用 RAG 是一个更好的解决方案。
于是,RAG 被越来越多提到,相关的论文,vectorDB,开源框架,一时间百花齐放。
但是我相信很多去实践 RAG 的人已经发现了一个情况,就是 RAG 入门很简单,基本不到半天就可以从头搭建一个基本的 RAG 系统。然而,要真正达到企业产品级应用的要求很难。
很多初学者对 RAG 中的各类组件、流程也不太了解,也不知道从哪儿下手去优化 RAG。所以这篇文章,我们就来聊聊 RAG,以及关于 RAG 的一些优化。
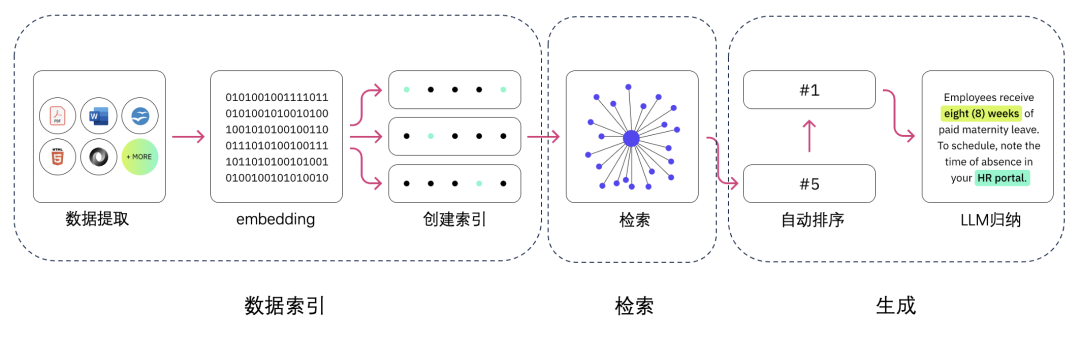
首先我们来看一下 RAG,简单来说,RAG 可以理解为 Retrieval 和 Generation,也就是检索与生成,在加上向量化和索引的工作,对 RAG 就可以总概方式地理解为“索引、检索和生成”
以下就是 RAG 的主要组成,依次是数据提取(分片)——向量化——创建索引——检索——排序/重排序——LLM 归纳生成。
今天我们先来重点聊一下检索模块的调优,可以这样说,检索模块的调优才是整个 RAG 系统中可操作空间最大的部分,而并非大模型基座本身,也不是 prompt。
因为首先你得查得准,才是最终能吐出正确结果的大前提条件。如果这一部分效果不行,后面无论怎么 summary,效果也不会好,这一现象在专有领域的问答场景更为明显。
我个人的经验是,在垂域的问答系统,至少有 60% 以上的 badcase 来源于检索模块。
很多同学可能脱口而出,优化 embedding!SimCSE,BCE,BGE,M3E。。。从榜单上挨个试下来,总有一款适合我。
在这里,我想说,拿来主义不能体现对业务深入的理解,作为一个成熟的 RAG 工程师,所采用的手段应该远不局限于此。
有些也称为意图识别模块。如果你的业务数据比较小而且垂直,这个模块还可以做成一个拒识模块。采用的手段有很多,这个模块不用很复杂,可以是一个浅层的分类模型。
主要目的是对用户 query 进行快速落域分类,把明显不是属于该领域的数据先过滤掉,去除无关信息这一步,可以明显提升检索准确率。
召回就从落域的知识库中来做,就算是检索错误,也大概是和目标领域相关的,不会出现过分的偏离。
实际业务系统肯定不局限于只用向量召回,这也是做文本搜索老生常谈的话题了。
比如可以增加字面召回,如 es 里的 bm25,浅层语义召回 x2vec,深度语义召回 DSSM 等,QQ 匹配,QA 匹配等等。
有些专有领域还可以结合知识图谱,graph embedding 召回,还有专有名词,实体词召回等等。召回源越丰富,真实答案被漏掉的可能性也相应就越小了。
这一般采用解释,改写,同义词替换,规范化等操作。目的是让某些专有名词,简称,缩略语等做字面层面的扩展,让大模型更容易理解。
这个就是采用推荐/搜索的做法,把检索过程做成漏斗型。
例如先从大量文本中得到 100 个召回结果,然后初排得到 20 个结果,接着 rerank 重排得到 8 个结果。最后把这 5 个结果送给大模型,结合提示归纳生成最终的结果。
这一过程主要是对齐不同召回源的评分标准,通过对多个召回结果进行二次排序,提高其与用户查询语义的匹配度,从而优化排序结果。
最后总结一下,在业务系统中要做好 RAG 是需要花很多功夫的,每个环节都要考验工程师对数据的深层次理解。
检索模块调优是其中一个重要的环节,上面提到的每一项优化方向,要深入做下去都可以干上很久,从 demo 到打磨成一个成熟的产品,这个周期就是积攒算法经验的过程,以上都是一些工作中的小经验分享,希望对大家有用。