
.01
.02
-
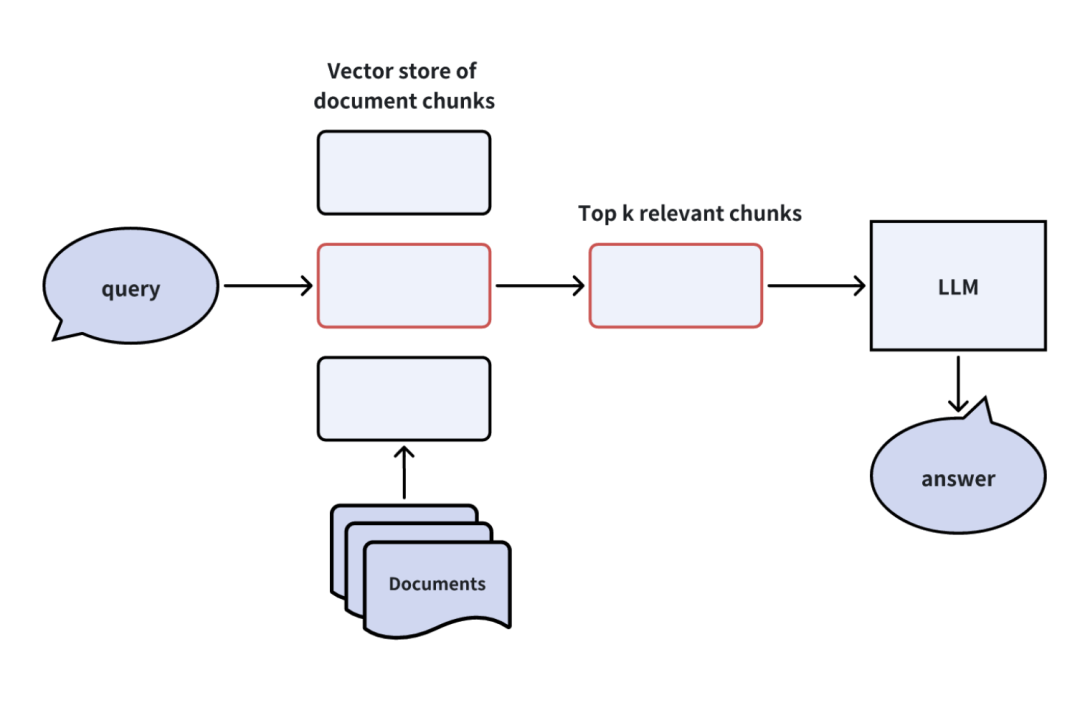
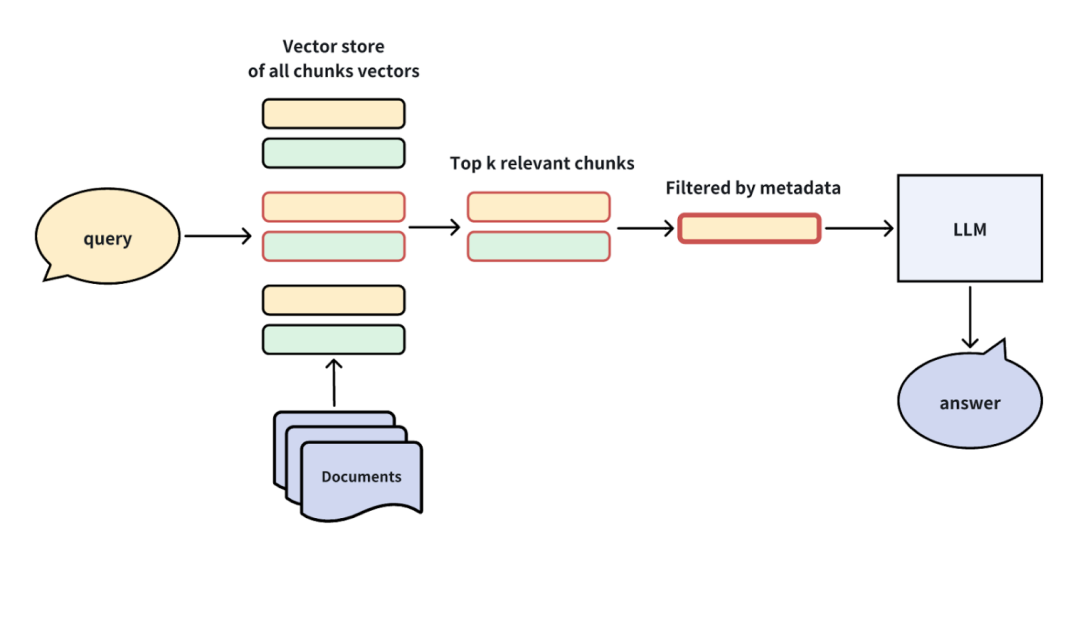
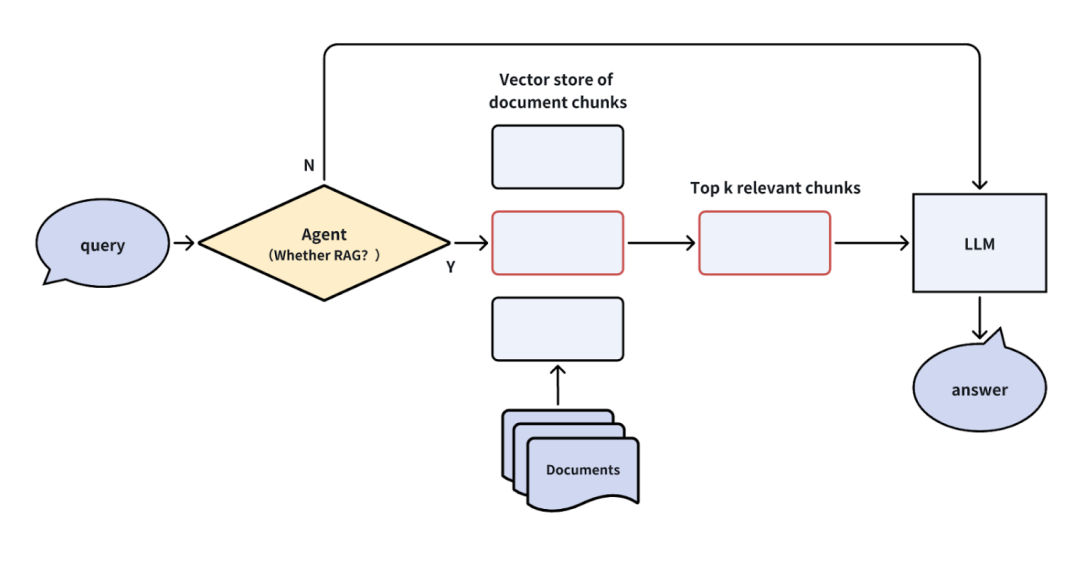
文档加载与分块:将文档内容拆分为多个小块(chunk),并将这些块存储到向量数据库(如Milvus或Zilliz Cloud)。 -
检索相关内容:根据查询,向量数据库找到与查询最相关的Top-K文档块。 -
注入上下文:将检索到的文档块作为上下文注入大语言模型(LLM)的提示中。 -
生成回答:LLM结合上下文生成最终的答案。
.03
-
查询优化(Query Enhancement):通过修改用户查询表达方式,使意图更清晰,提升查询准确性。 -
索引优化(Indexing Enhancement):通过改进索引方式,增强文档块的检索效率。 -
检索器优化(Retriever Enhancement):提升检索阶段的准确性与上下文覆盖范围。 -
生成器优化(Generator Enhancement):改善提示设计,确保生成更优质的答案。 -
管道优化(Pipeline Enhancement):优化整体RAG管道流程,动态调整系统执行方式。
一、查询优化:为系统注入“清晰思路”
-
流程:先根据文档块生成假设性问题,将其存储于向量数据库中。当用户提交实际查询时,系统先检索假设性问题,再返回相关文档块供LLM生成答案。 -
优点:缓解跨领域查询的对称性问题,提高检索精度。 -
缺点:生成假设性问题可能增加计算开销,且存在不确定性。
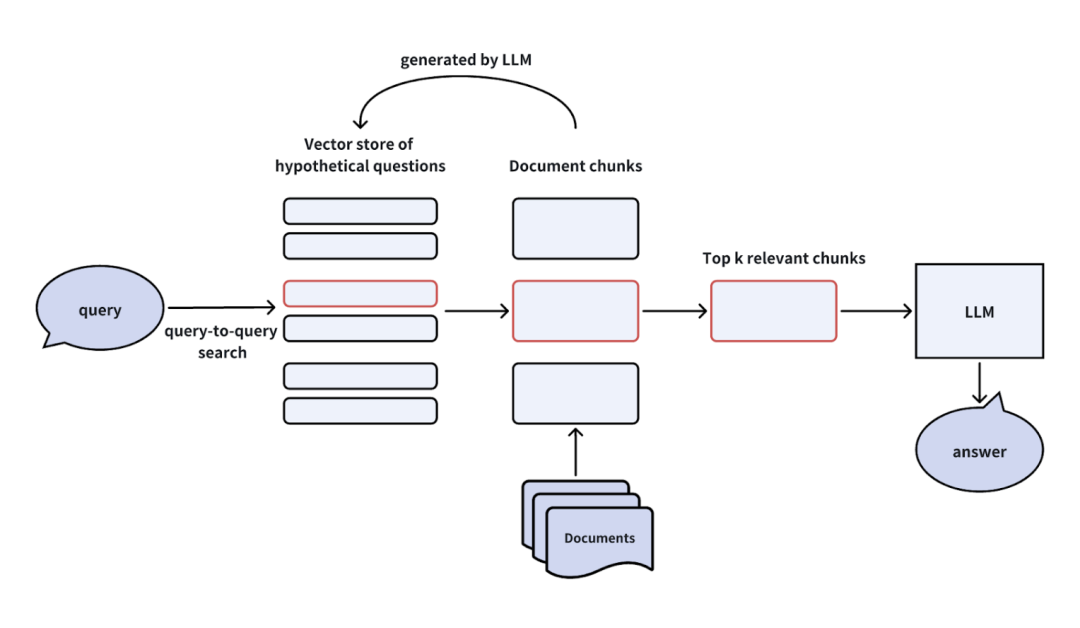
-
优势:类似于假设性问题生成,但通过直接生成答案有效处理复杂查询。 -
不足:生成“假设性回答”需要额外的计算资源。

-
原始查询:Milvus和Zilliz Cloud的功能有什么不同? -
拆分后: -
子查询1:Milvus的功能有哪些? -
子查询2:Zilliz Cloud的功能有哪些?
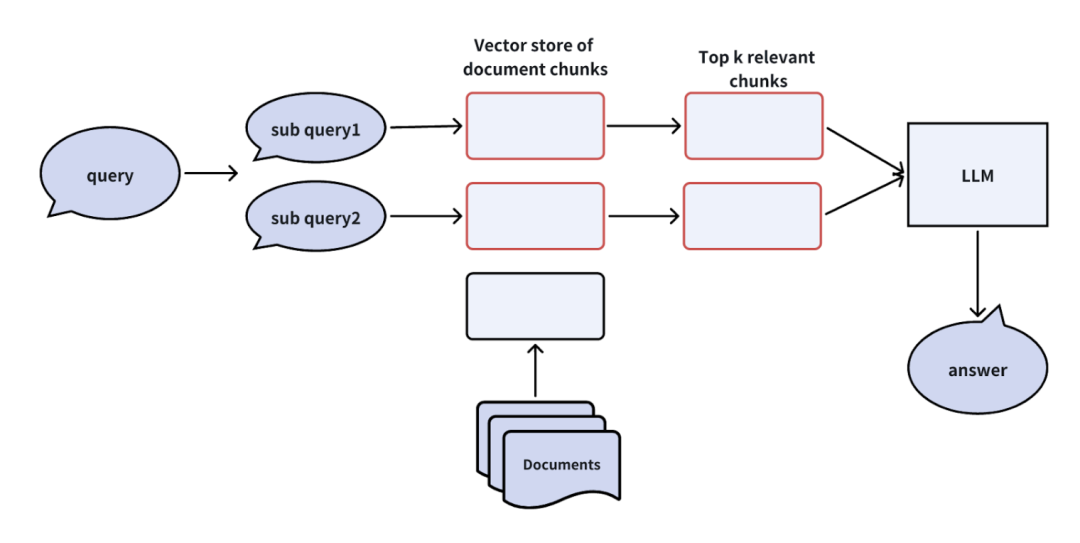
-
用户问题:Milvus是否可以存储10亿条记录的数据集? -
退一步问题:Milvus能处理的数据集规模上限是多少?
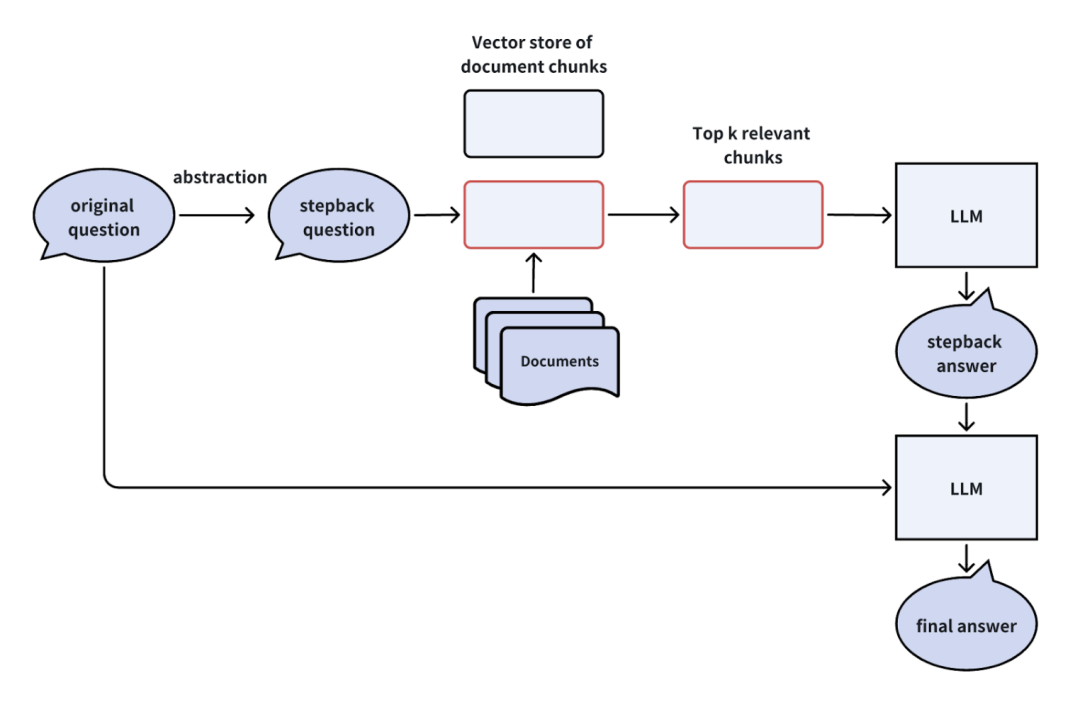
-
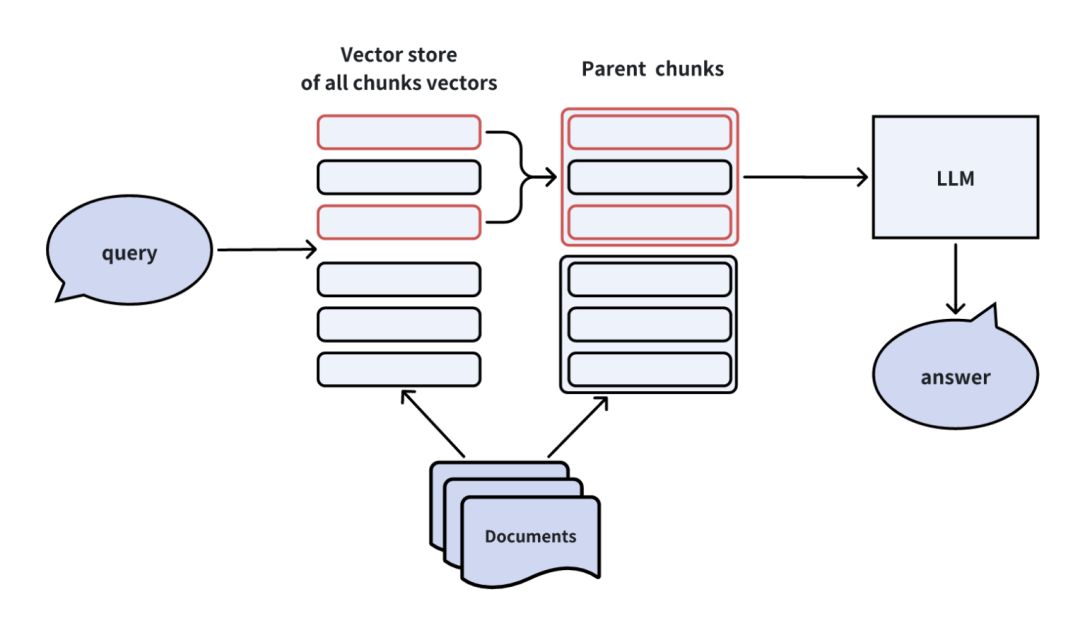
初始检索时聚焦细粒度子文档块。 -
如果多个子块来自同一父文档,则将父文档提供给LLM作为上下文。
-
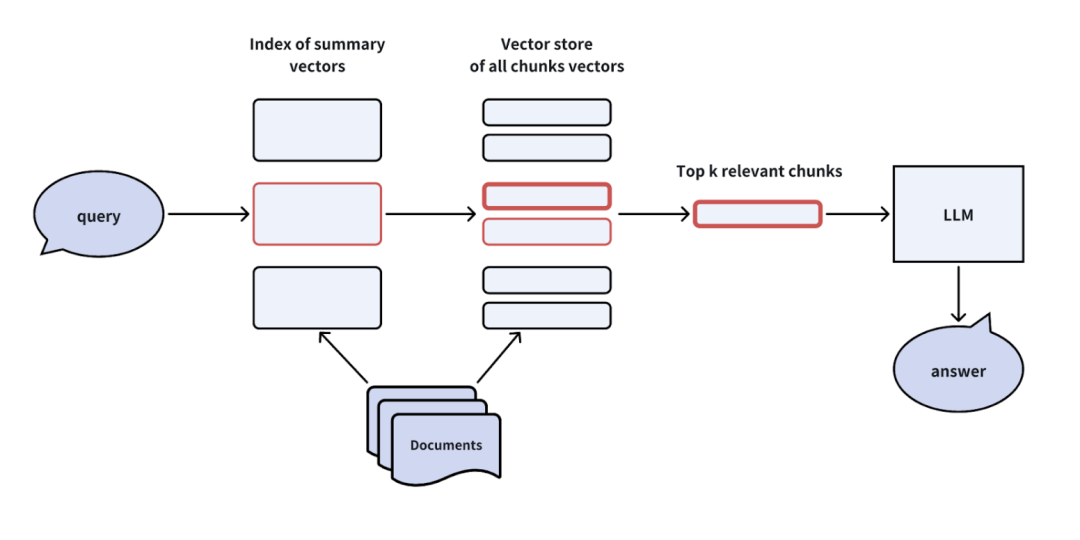
第一级存储文档摘要,用于快速筛选相关文档。 -
第二级存储文档块,仅检索筛选出的相关文档内的内容。
-
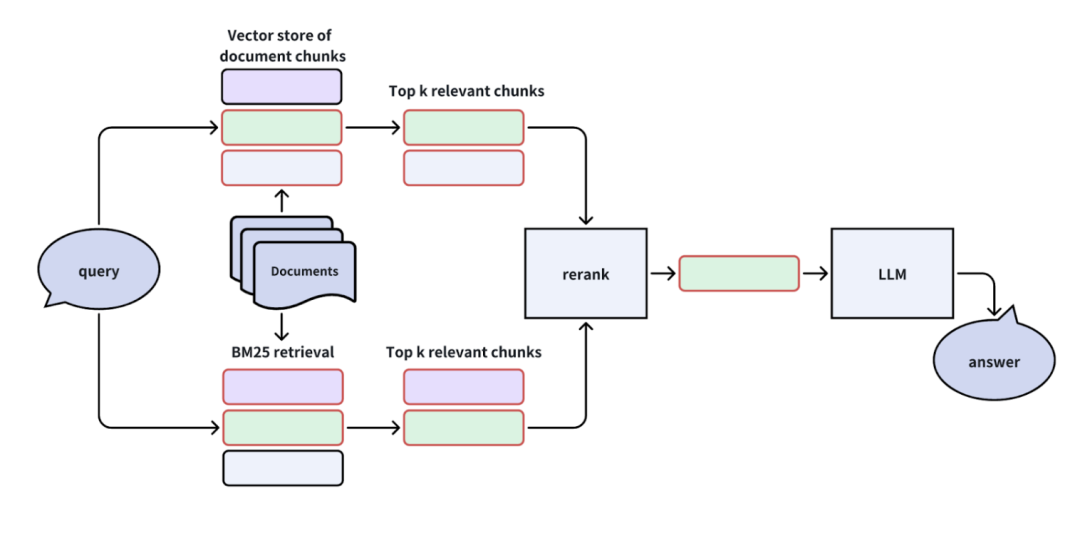
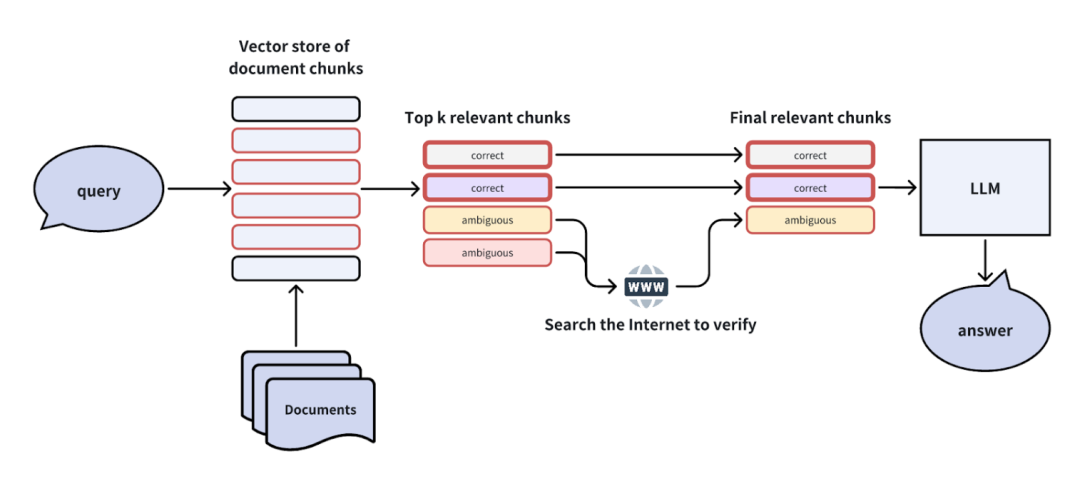
优点:提升了检索覆盖率,减少向量召回不足的问题。
-
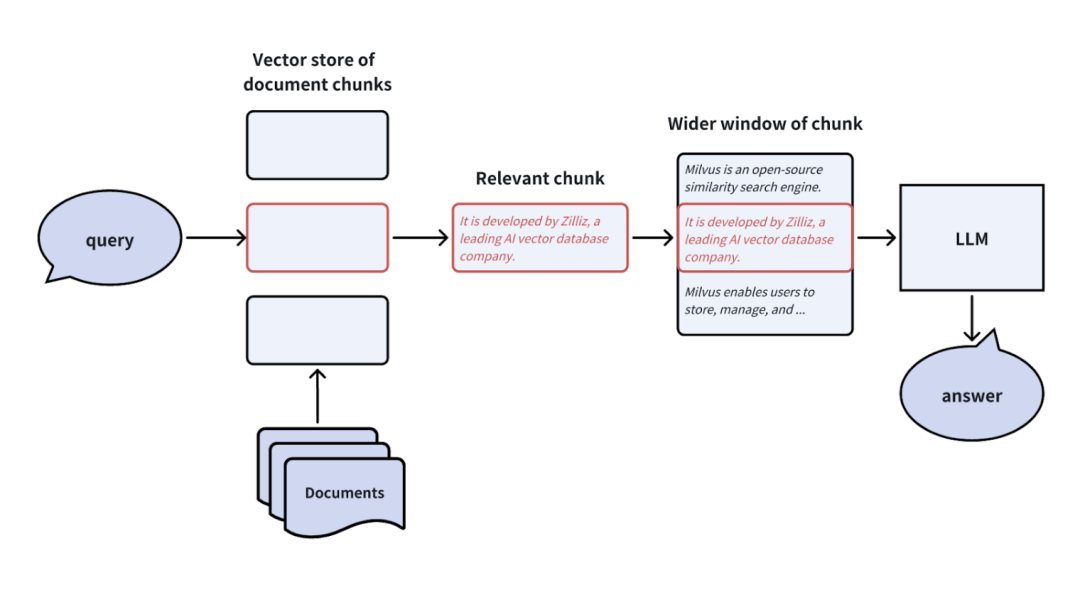
注意:窗口大小需要根据业务需求动态调整,避免过多无关信息干扰。
-
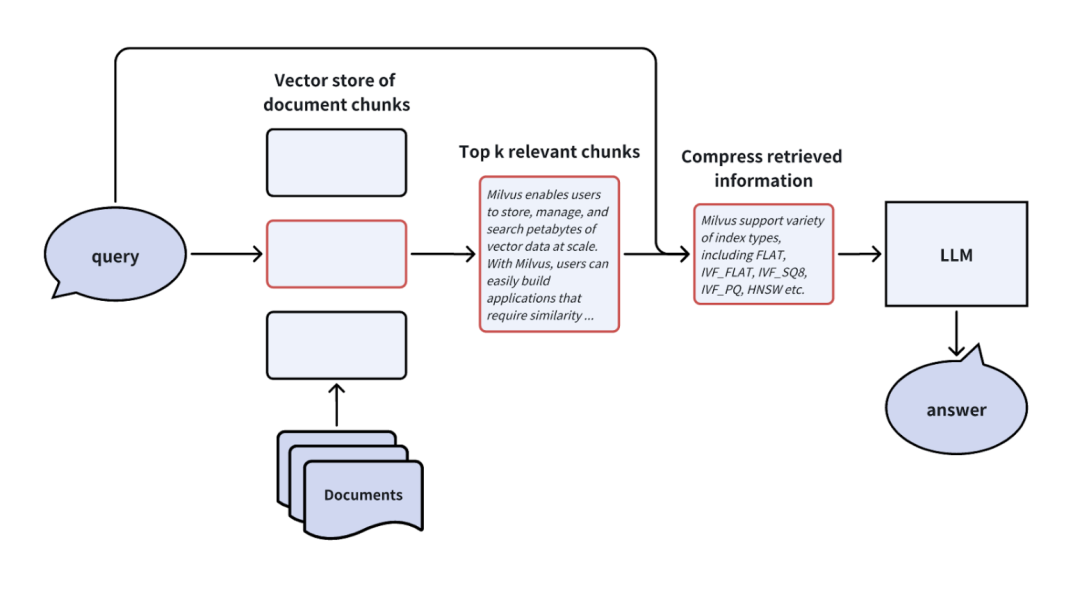
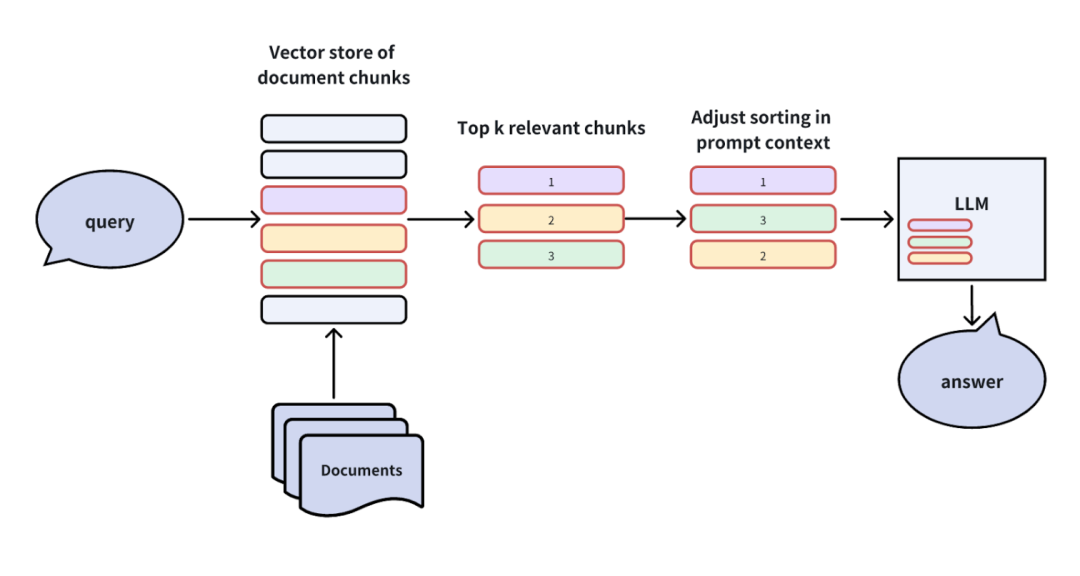
优点:优化有限提示窗口内的信息利用率,提高生成答案的准确性。
-
优势:提升响应速度,避免不必要的管道资源消耗。
.03
