


.01
.02

-
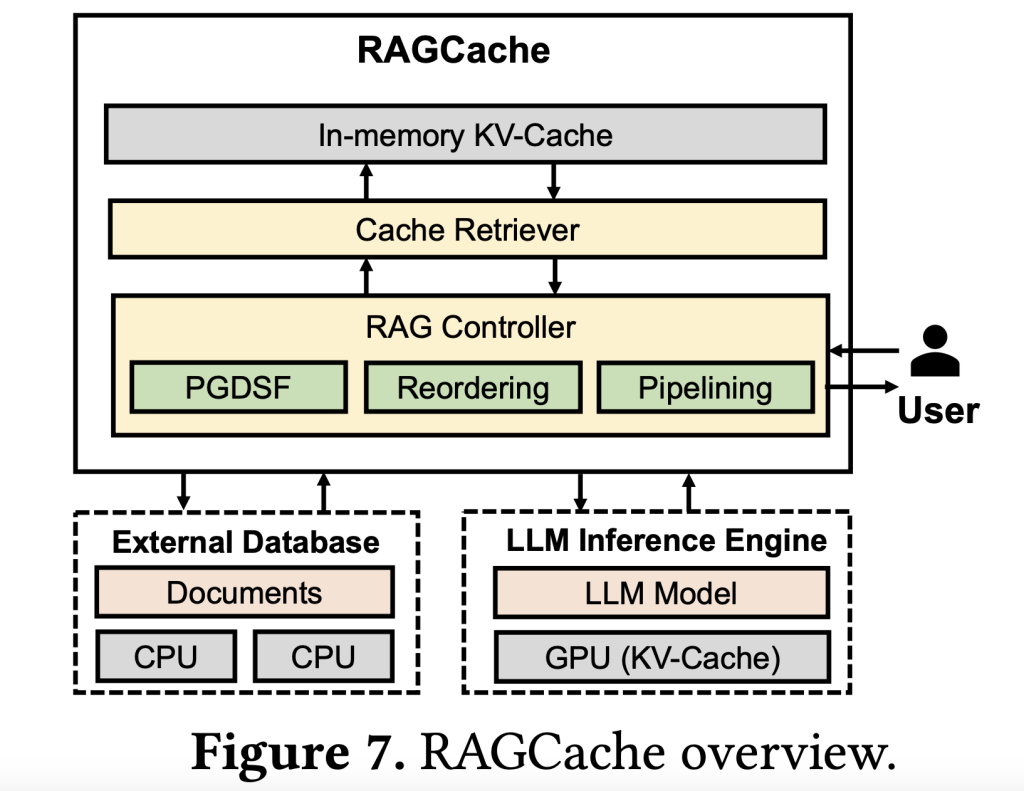
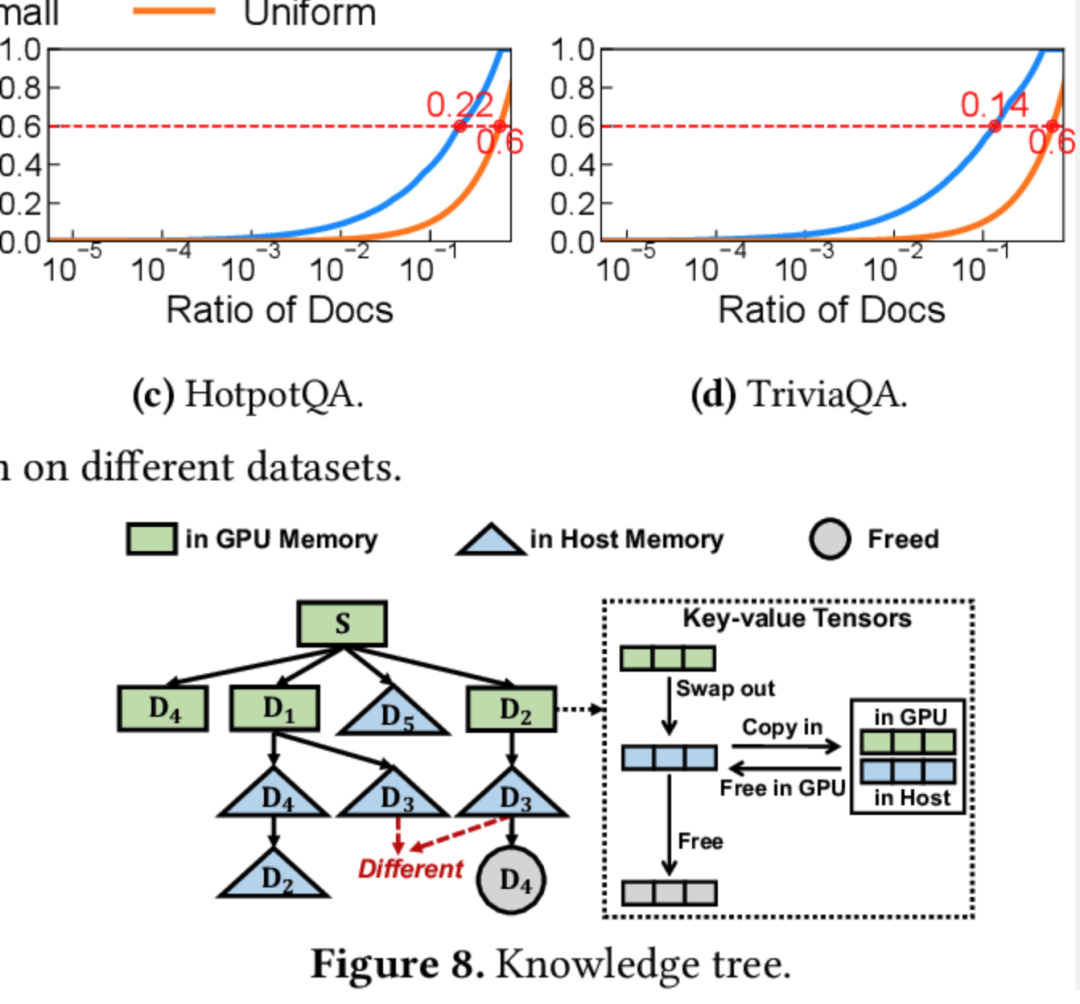
知识树缓存:通过构建一个知识树结构,RAGCache能将检索到的知识缓存为键值张量(key-value tensors),使得常访问的知识存储于GPU,较少访问的内容则缓存在主机内存中。这种多级存储机制不仅降低了对GPU资源的需求,也使得模型能够迅速获取到常用的知识。 -
智能替换策略:前缀感知的PGDSF替换策略在考虑文档的顺序、频次、大小及近期访问情况的基础上,智能选择哪些内容应保留在缓存中。这种策略确保缓存空间始终用于存储最有价值的中间状态,从而减少了缓存未命中情况,提高了生成效率。 -
动态预测流水线:RAGCache实现了矢量检索与LLM生成步骤的动态重叠,使得模型能够同时进行检索与生成,避免了传统RAG系统中的顺序执行瓶颈,大幅降低了响应延迟。
.03
.04
-
实时客服和智能助理:客服场景中的AI需要在短时间内处理海量的用户请求,RAGCache的高缓存命中率和快速响应能力,能显著减少用户等待时间,提升用户体验。 -
内容生成和实时推荐:在内容推荐系统中,RAGCache的缓存机制可以帮助系统快速调用常用知识,使得AI在内容生成、推荐等方面更加智能化。 -
大规模检索和企业知识管理:在需要频繁访问外部数据库的知识密集型应用中,如法律、金融等领域,RAGCache通过减少重复计算和资源浪费,有助于提升AI模型的生产力。
.05
.05
.06
