

近期,香港大学黄超团队提出了一种新的大模型 RAG 范式——LightRAG。这是一种简单快速的检索增强生成(RAG)系统,显著降低了与大语言模型(LLMs)相关的成本。LightRAG 通过图结构有效捕捉和表示实体间的复杂关系,采用双层检索范式,实现低层与高层信息的高效整合。此外,LightRAG 还具备快速适应动态数据变化的能力,能够及时整合新信息。


模型架构
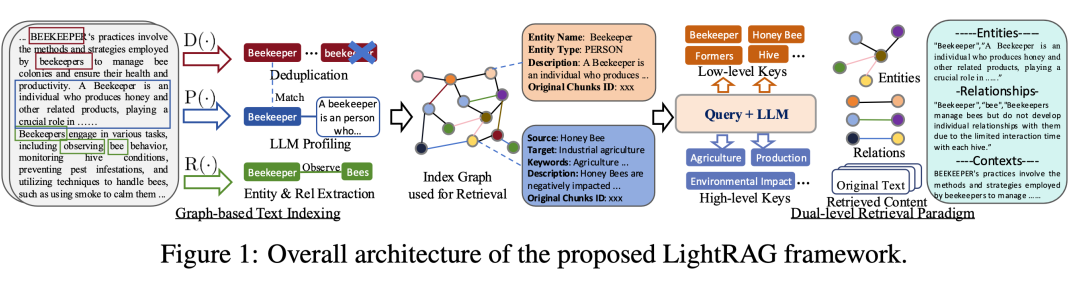
2.1 图增强的实体与关系提取
LightRAG 通过将文档拆分为更小的可管理片段,从而显著提升了检索系统的效率。这种方法使得相关信息的快速识别和获取变得更加便捷,无需逐篇分析整个文档。
接下来,我们利用大语言模型(LLMs)来识别和提取各种实体(如人名、日期、地名和事件)及其之间的关系。提取后的信息将用于构建一个综合性的知识图谱,旨在揭示文档集合中的联系与深层见解。以下是我们在图结构文本索引中使用的关键功能:
-
实体与关系提取 :该功能利用大语言模型(LLM)从文本数据中识别出实体(节点)及其相应的关系(边)。例如,它能够从句子“心脏病专家评估症状以确定潜在的心脏问题”中提取出“心脏病专家”和“心脏病”等实体,并识别出“心脏病专家诊断心脏病”的关系。为了提升处理效率,原始文本会被划分为多个小段。 -
LLM 生成键值对 :我们利用大语言模型(LLM)创建实体节点和关系边的键值对。每个索引键由特定的词或短语组成,以便实现高效检索,而对应的值则是从外部数据中提取的摘要信息,用于支持文本生成。实体名称作为独特的索引键,而关系则通过 LLM 扩展成多个索引键,涵盖与相关实体相关的主题。 -
去重与优化图操作 :我们通过去重功能识别并整合来自不同文本片段的重复实体和关系。这个过程显著降低了图操作的成本,从而提升了数据处理的效率。
LightRAG 的图结构文本索引模式提供了两个显著的优势。首先,增强的信息理解:构建的图形结构能够从多跳子图中提取整体信息,显著提高了模型在处理跨多个文档的复杂查询时的能力。其次,优化的检索性能:图生成的键值数据结构经过改进,能够迅速且准确地获取所需信息,优于传统方法中的嵌入匹配和低效的片段检索技术。
-
高效整合新数据:增量更新模块采用统一的方法来处理新信息,使模型能够在保持现有图结构的完整性的同时,顺利引入新的外部数据库。这一策略确保了历史数据的可用性,同时丰富了知识图谱,避免了信息的冲突或冗余。
-
优化计算资源:由于无需重新构建整个索引图,这种方法大幅度减少了计算的负担,并加速了新数据的整合。这样一来,模型不仅得以保持系统的准确性,确保信息的及时更新,还能显著节约资源,从而增强了 RAG 系统的整体效率。
2.3 双层检索范式
为了同时获取特定文档片段及其复杂的相互关系,LightRAG 提出了生成详细(Low-Level)和抽象(High-Level)两种层次的查询键。
-
细化查询:这些查询关注具体细节,通常涉及图中的特定实体,旨在准确检索与特定节点或边相关的信息。例如,细化查询可能是“《傲慢与偏见》的作者是谁?” -
抽象查询:与此相对,抽象查询更具广泛性,涉及摘要或全局主题,而非直接关联于特定实体。例如,一个概念查询可以是“人工智能对现代教育的影响是什么?”
为了应对多样化的查询需求,模型在双层检索模式中采用了两种不同的检索策略。这确保无论是细化还是概念查询,都能有效地得到响应,满足用户的期望。
-
Low-Level 检索:这一层次主要关注特定实体及其相关属性或关系。该层级的查询强调细节,旨在提取与图中特定节点或边准确相关的信息。 -
High-Level 检索:此层次处理更广泛的主题和全局概念。这类查询聚合多个相关实体和关系的信息,提供对高层概念和摘要的深刻理解,而非具体细节。
2.4 基于检索增强的答案生成

定义许多 RAG 查询(尤其是涉及复杂高层语义的查询)的真实值是一项巨大的挑战。为了解决这一问题,我们基于现有研究,采用了大语言模型(LLM)对回答的答案多维度评估比较的方法。在本次实验中,我们使用了 GPT-4o-mini 模型,对每个对比方法与 LightRAG 进行排名。总体而言,我们设定了四个评估维度:
-
全面性:答案在多大程度上涵盖了问题的各个方面和细节? -
多样性:答案在提供不同视角和见解方面的丰富程度如何? -
赋能性:答案在多大程度上帮助读者理解主题并做出明智的判断? -
总体表现:综合前三个维度的表现来评估最佳答案。
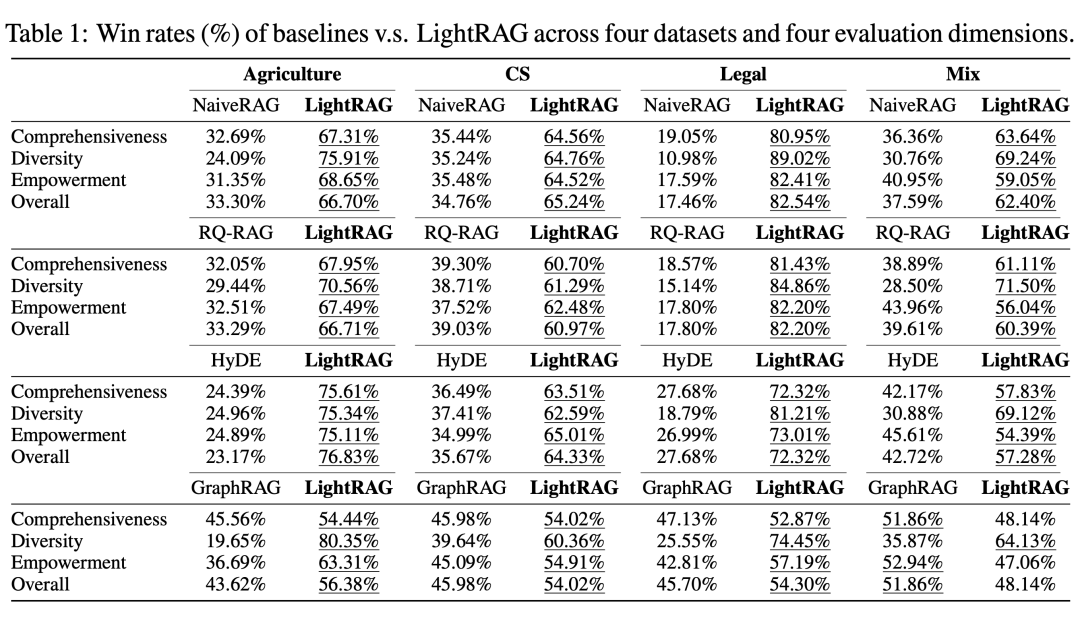
图增强RAG系统在大规模语料库中的优势
在处理大量 token 和复杂查询时,基于图结构的 RAG 系统(如 LightRAG 和 GraphRAG)展现出明显优于传统片段检索方法(如 NaiveRAG、HyDE 和 RQRAG)的性能。
与现有 RAG 方法相比,LightRAG 在“多样性”这一指标上展现出显著优势,尤其在较大的 Legal 数据集中。这一持续的领先表现表明,LightRAG 在生成多样化回答方面具有强大的能力,特别适用于内容丰富的场景。
尽管 LightRAG 和 GraphRAG 均采用图结构的检索机制,LightRAG 在较大数据集和复杂语言背景下仍表现出持久的优势。在包含数百万 token 的 Agriculture、CS 和 Legal 数据集中,LightRAG 明显超越了 GraphRAG,彰显了其在不同环境中全面理解信息的能力。
通过结合对特定实体的低层检索与对更广泛主题的高层检索,LightRAG 显著增强了回答的多样性。这种双层机制有效应对了详细与抽象查询,确保对信息的全面掌握。
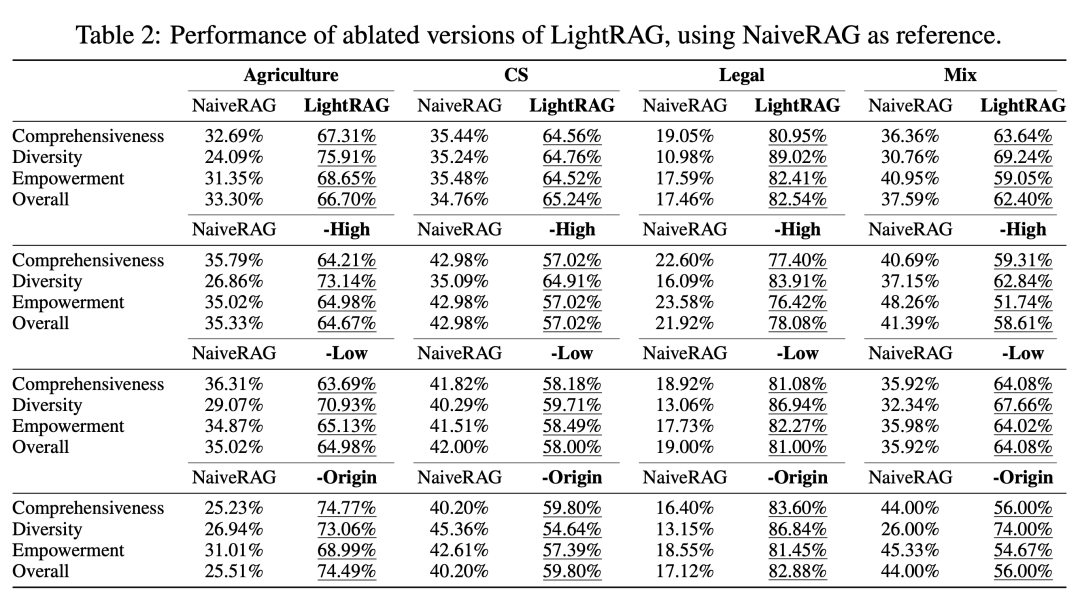
3.2 消融实验
我们首先分析了 Low-Level 和 High-Level 检索范式的影响。通过比较两种消融模型(分别移除一个模块)与 LightRAG 在四个数据集上的表现,我们得出了以下主要观察:
-
仅 Low-Level 检索:-High 该变体移除了高层检索,导致在几乎所有数据集和指标上均出现显著下降。这一下降主要源于其过于强调具体信息,专注于实体及其直接关联的邻居。尽管这种方法允许深入探索直接相关的实体,但在需要综合洞察的复杂查询中表现不足。 -
仅 High-Level 检索:-Low 这一变体通过利用实体间的关系来捕捉更广泛的内容,而非专注于具体实体。这种方法在全面性上显示出显著优势,能够收集更丰富和多样化的信息。然而,这也意味着它无法深入探讨具体实体,从而限制了提供详细洞察的能力。因此,在需要精准、详细答案的任务中,这种仅依赖高层检索的方法可能表现不佳。 -
混合模式:混合模式(即 LightRAG 的完整版本)结合了低层和高层检索的优势,既能广泛检索关系,又能深入探索具体实体。这种双层检索方法确保了广度与深度的有效结合,提供了全面的数据视图。因此,LightRAG 在多个维度上实现了平衡的表现。
3.3 模型成本与动态数据适应性分析
我们从两个关键角度对 LightRAG 与 GraphRAG 的成本进行了比较。首先,我们分析了索引和检索过程中的 token 数量和 API 调用次数。其次,我们评估了这些指标在动态环境中处理数据变化的表现。
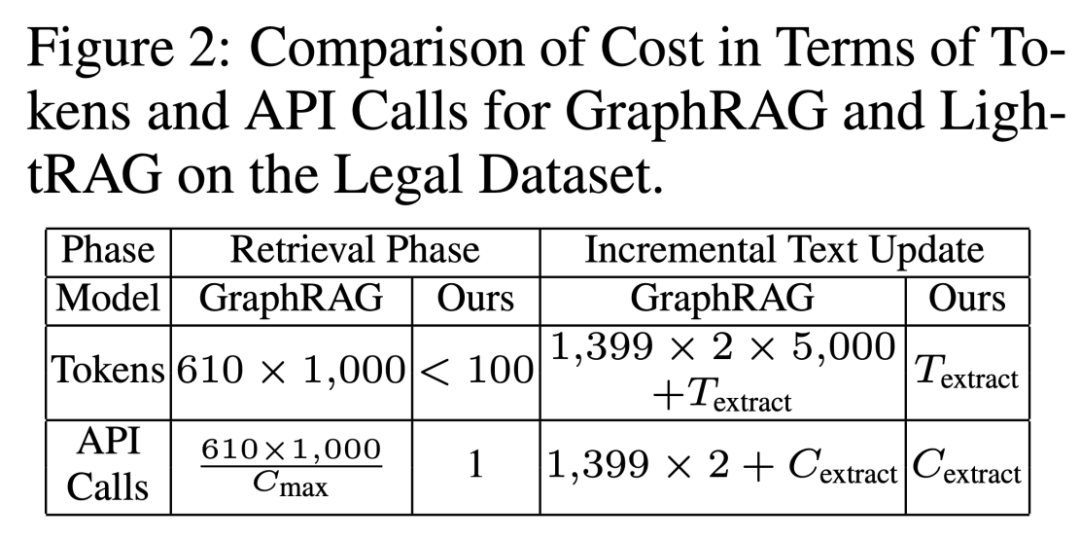
在检索阶段,GraphRAG 创建了 1,399 个 Communities,其中 610 个二级社区被用于本实验的检索。每个社区平均包含 1,000 个 token,因此总的 token 消耗量达到 610,000 个(610 个社区 × 每个社区 1,000个 token)。
此外,GraphRAG 需要逐一检查每个社区,导致了数百次 API 调用,这显著增加了检索成本。相较之下,LightRAG 对这一过程进行了优化,仅需使用不到 100 个 token 来进行关键词生成和检索,整个过程仅需一次 API 调用。这种高效性源于我们独特的检索机制,巧妙地结合了图结构与向量化表示,从而避免了对大量信息的预处理。
