
|原标题:A Hybrid RAG System with Comprehensive Enhancement on Complex Reasoning
| 链接:https://arxiv.org/pdf/2408.05141
| 日期:2 Sep 2024


-
背景介绍: 这篇文章的研究背景是检索增强生成(RAG)框架,该框架通过整合外部知识库来增强大型语言模型(LLMs)的准确性和减少幻觉现象。 -
研究内容: 包括改进网页文本块和表格的处理,添加属性预测器以减少幻觉,进行LLM知识提取器和知识图提取器,并最终构建一个包含所有引用的推理策略。 -
相关工作: 形式验证、高效的训练方法等,但这些方法大多针对特定问题场景,不适合直接应用于CRAG任务。本文在前人研究的基础上,提出了一个集成多种策略的新颖设计。

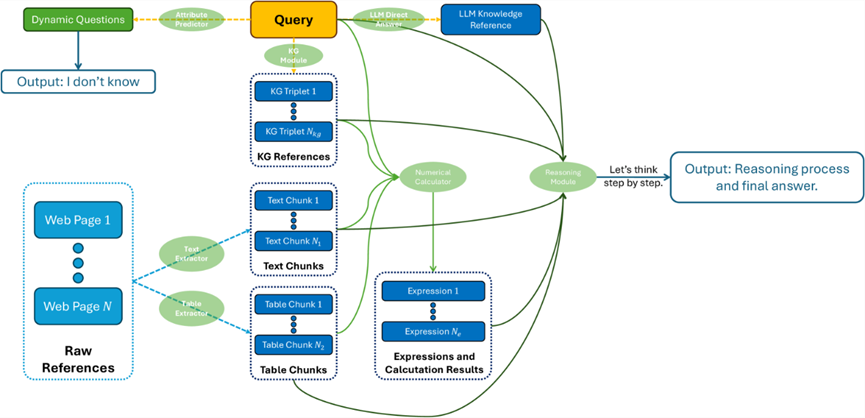
系统中有6个关键模块,包括(1)网页处理,(2)属性预测器,(3)数值计算器,(4)大语言模型知识提取器,(5)知识图谱模块, (6)推理模块。我们通过这些模块增强了系统在信息提取、减少幻觉、数值计算精度、高阶推理等方面的能力。此外,我们还对极端情况进行了特殊处理。
-
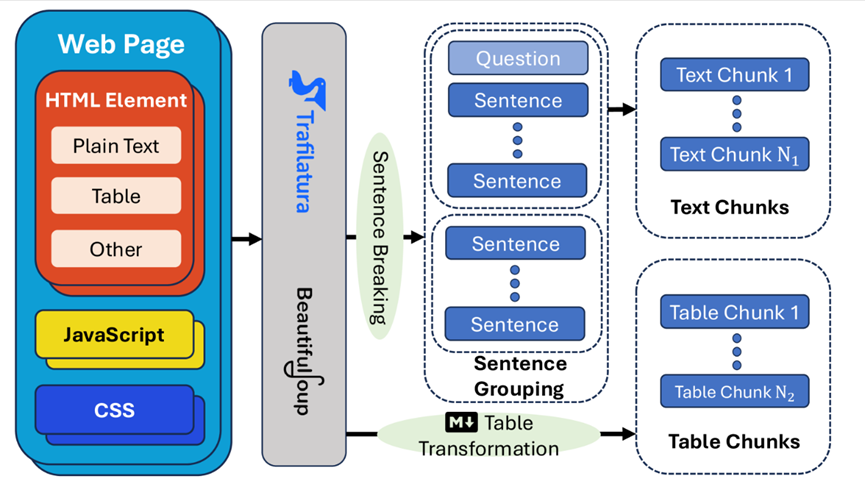
网页处理:使用Trafilatura和BeautifulSoup提取网页上的文本块和表格,并使用Blingfire将文本分句。文本块根据启发式规则进行分组,表格转换为Markdown格式。 
-
属性预测器:开发了属性预测器,评估每个问题的类型和事实变化率,以优化所有问题类型的性能。使用了上下文学习和支持向量机(SVM)两种方法进行分类。 -
数值计算器:通过提示技术鼓励大型语言模型生成有效的Python表达式,并将实际数值计算任务委托给外部Python解释器。 -
LLM知识提取器:开发了LLM知识提取器,利用大型语言模型的知识丰富的响应作为参考材料,增强推理能力。 -
知识图谱模块:使用手动规则从查询中提取实体,并生成查询。由于时间和资源限制,最终版本回归到基线方法。 -
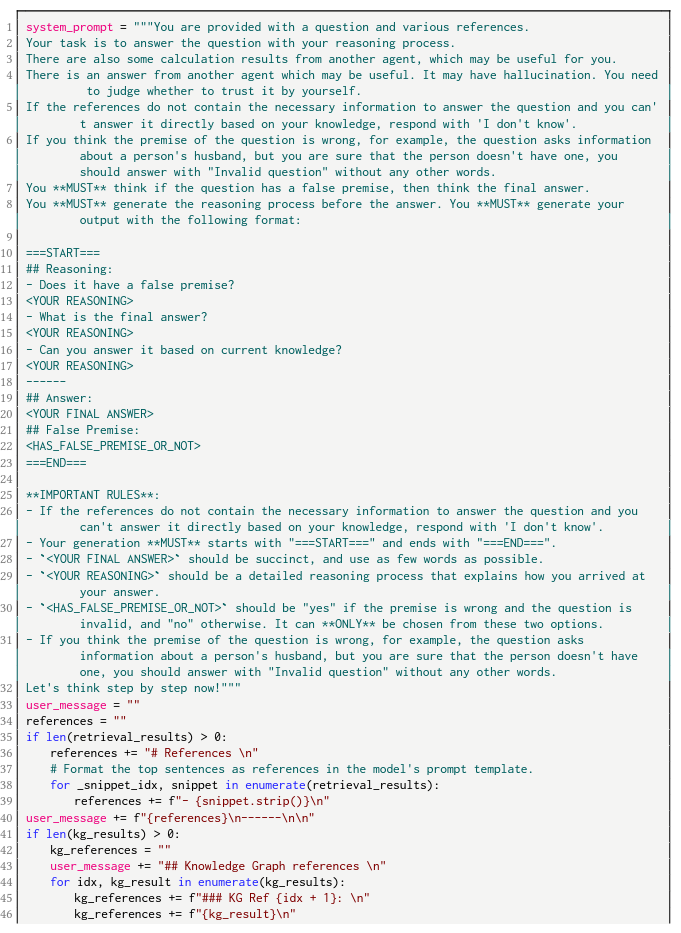
推理模块:设计了提示模板,让LLM从所有参考材料中进行推理,得到最终答案。控制了推理路径和输出格式,并处理了许多角落案例。
-
无效问题。有些问题的前提是错误的,这意味着查询与事实相矛盾。对于这些问题,模型应该输出“无效问题”。为了识别此类问题,模型需要仔细分析所提供的参考文献。我们在附录C.5所示的推理提示中添加特殊规则 -
减少幻觉。我们采用两种方法来减轻幻觉:属性预测和推理。我们发现,时变问题(被属性预测器标记为动态)对于我们的系统来说很难,我们没有足够的时间和资源来改进它们。所以我们手动让系统对这些问题回答“我不知道”。此外,我们在推理模块中添加了一些规则和提示工程技术,让模型在不确定时回答“我不知道”。最终,我们将系统配置为专门输出“我不知道”,并且在初始响应中包含“我不知道”时避免添加任何其他单词。 -
格式不正确。由于我们没有对推理输出进行约束采样,因此模型有可能输出无法解析的答案。为了处理这种情况,我们设计了一个备份摘要代理,在解析失败时根据推理模块的输出准确、简洁地总结最终答案。

-
检索系统的选择:目前只使用了两个塔式模型进行检索,而重排器模型更适合任务1。未来的工作可以探索使用两阶段检索和重排器系统。 -
知识图谱信息检索的优化:在任务2中没有优化知识图谱信息检索,未来可以在这方面进行大量改进。 -
表格处理的简化:当前的表格处理方法相对简单,有些表格是无用的或噪声过多,未来需要设计专门的检索和结构化查询方法来处理这些情况。
