

概述
这篇文章深入探讨了 Wang 等人在 2024 年的研究,旨在为构建高效的检索增强生成(RAG)系统提供最佳实践建议。文章由 Towards AI 的联合创始人兼 CTO Louis-Francois 撰写,分析了 RAG 系统的核心组件与策略。
主要内容摘要
-
查询分类:通过分类任务决定是否需要进行检索,确保系统只在必要时检索外部数据。
-
数据分块:为数据选择合适的块大小至关重要,理想的块大小在 256 至 512 个 token 之间,有助于减少噪音和提高效率。
-
元数据与混合搜索:元数据(如标题或关键词)与混合搜索(结合语义搜索和传统关键词搜索 BM25)可显著提升检索精度。
-
嵌入模型选择:挑选适合的嵌入模型,文章推荐使用像 FlagEmbedding 这样性能与效率均衡的模型。
-
向量数据库:使用像 Milvus 这样的高性能向量数据库来处理大量检索请求,确保系统的长期稳定性。
-
查询转换:在检索前进行查询转换以提高准确性,如通过查询重写或分解复杂问题,改进系统的检索表现。
-
重新排序与文档打包:在文档检索后,通过 reranking 技术提升结果的相关性,并进行文档重新打包,以优化信息呈现。
-
摘要:生成之前进行文档摘要,有助于去除冗余信息,降低生成成本。
-
微调生成模型:通过对生成模型进行微调,提高模型处理复杂查询和去除无关信息的能力。
-
多模态检索:整合多模态技术处理图像查询,并基于类似内容进行检索,进一步提高系统的响应准确性。
意见
-
Wang 等人的研究被认为是 RAG 系统的“洞察金矿”。 -
查询分类对于确定何时需要检索至关重要。 -
数据的最佳块大小介于 256 到 512 个令牌之间,但可能因数据集而异。 -
元数据和混合搜索是高效检索的首选,而不是 HyDE 等更复杂的方法。 -
建议使用 FlagEmbedding 的 LLM,因为它在性能和大小之间取得了平衡。 -
Monot5 是最受欢迎的重新排名模型,因为它在性能和效率之间取得了平衡。 -
建议以“相反”的顺序重新打包文档,以改进 LLM 的生成过程。 -
像 Recomp 这样的摘要工具对于减少提示长度和成本很有价值。 -
使用相关文档和随机文档的混合来微调生成器有利于处理不相关的信息。 -
多模态检索是处理文本和图像的系统的一个重要考虑因素。 -
该论文承认了未来研究的局限性和领域,例如猎犬和发电机的联合训练。
探索每个组件
大家早上好!我是 Towards AI 的联合创始人兼首席技术官 Louis-Francois,今天,我们正在深入研究可能是最好的检索增强一代 (RAG) 技术栈——这要归功于 Wang 等人在 2024 年的一项出色研究。
这是构建最佳 RAG 系统的见解金矿,我在这里为您分解它。
那么,是什么让 RAG 系统真正成为顶级的系统呢?是组件,对吧?让我们回顾一下最好的组件以及它们的工作原理,这样您也可以使您的 RAG 系统成为顶级系统并获得多模式奖励。
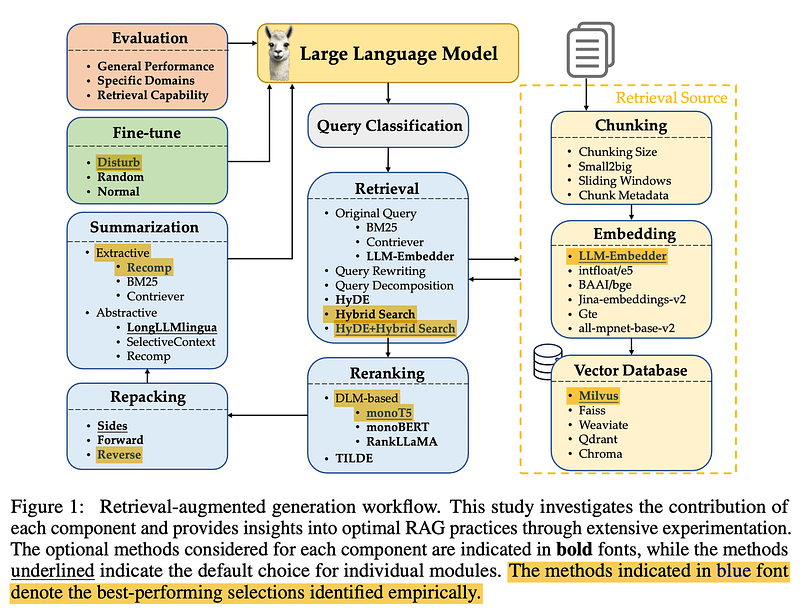
查询分类
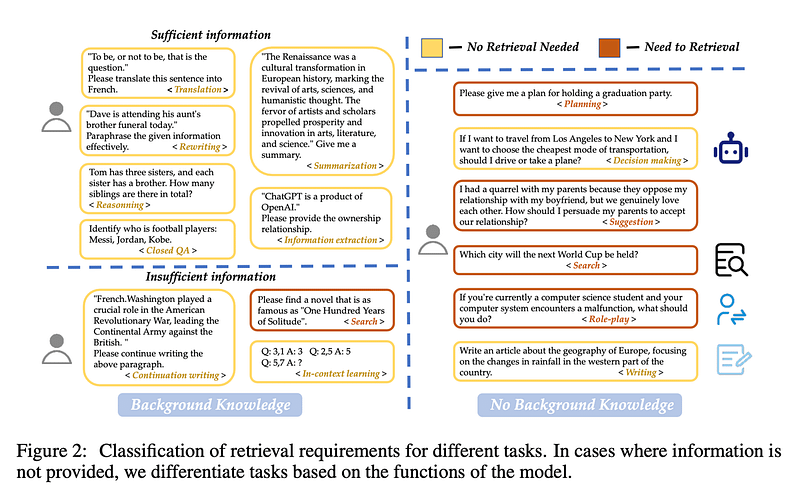
让我们从 Query Classification 开始。并非所有查询都是平等的 — 有些查询甚至不需要检索,因为大型语言模型已经知道答案。例如,如果你问 “谁是梅西?”LLM 可以满足您的需求。无需检索!
Wang 等人创建了 15 个任务类别,确定查询是否提供了足够的信息或是否需要检索。他们训练了一个二元分类器来分隔任务,在不需要检索的地方标记为“sufficient”,在需要检索时标记为“insufficient”。在此图像中,黄色表示不需要,红色表示去获取一些文档!
分块
接下来:分块。这里的挑战是为您的数据找到完美的数据块大小。太长了?您会增加不必要的噪音和成本。太短了?你错过了上下文。

Wang 等人发现 256 到 512 个标记之间的块大小效果最好。但请记住,这因数据而异 – 因此请务必运行您的评估!专业提示:使用 small2big(从小块开始进行搜索,然后移动到较大的块进行生成),或尝试滑动窗口以重叠块之间的标记。
元数据和混合搜索
利用您的元数据!添加标题、关键字甚至假设问题等内容。将其与 Hybrid Search 配对,它结合了向量搜索(用于语义匹配)和用于传统关键字搜索的优秀 BM25,您就是金子。
HyDE(生成伪文档以增强检索)很酷,可以带来更好的结果,但效率非常低。现在,坚持使用 Hybrid Search——它取得了更好的平衡,尤其是在原型设计方面。
嵌入模型
选择正确的 嵌入模型 就像找到一双完美的鞋子。
你不想要打网球的足球鞋。
来自 FlagEmbedding 的 LLM 最适合这项研究——性能和大小的完美平衡。不太大,也不太小——恰到好处。
请注意,他们只测试了开源模型,因此 Cohere 和 OpenAI 被淘汰出局。否则,Cohere 可能是您最好的选择。
矢量数据库
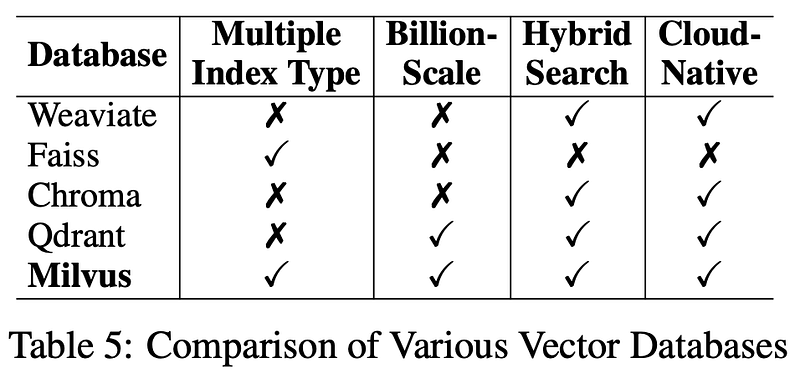
现在是数据库。对于长期使用,Milvus 是他们的首选矢量数据库。它是开源的、可靠的,是保持检索系统平稳运行的绝佳选择。我还在下面的描述中链接了它。
查询转换
在检索之前,您必须 转换 这些用户查询!无论是通过 查询重写 以使其清晰,还是通过查询 分解 将复杂问题分解为更小的问题并检索每个子问题,甚至生成伪文档(如 HyDE 所做的_)并在检索过程中使用它们,此步骤对于提高准确性都至关重要。请记住,更多的转换可能会增加延迟,尤其是 HyDE..
重新排名
现在我们来谈谈 Reranking 。检索文档后,您需要确保最相关的文档位于文档堆的顶部。这就是重新排名的用武之地。
在这项研究中,monoT5 脱颖而出,成为平衡性能和效率的最佳选择。它微调 T5 模型,以根据文档与查询的相关性对文档重新排序,确保最佳匹配优先。 RankLLaMA 总体性能最好,但 TILDEv2 最快。如果您有兴趣,论文中提供了有关每个的更多信息。
文档重新打包
重新排名后,您需要进行一些 Document Repacking 。Wang 等人推荐了“反向”方法,其中文档按相关性升序排列。Liu 等人(2024 年)发现,这种方法(将相关信息放在开头或结尾)可以提高性能。重新打包优化了信息呈现给 LLM 的方式,以便在重新排序过程发生后生成,以帮助 LLM 更好地以更好的顺序理解提供的信息,而不是理论上的相关顺序。
综述
然后,在调用 LLM,您希望使用 Summarization 来减少绒毛。发送到 LLM成本高昂,而且通常是不必要的。摘要将有助于删除冗余或不必要的信息并降低成本。
使用 Recomp 等工具进行抽取压缩以选择有用的句子,并使用抽象压缩来综合来自多个文档的信息。但是,如果速度是您的首要任务,您可以考虑跳过此步骤。
微调生成器
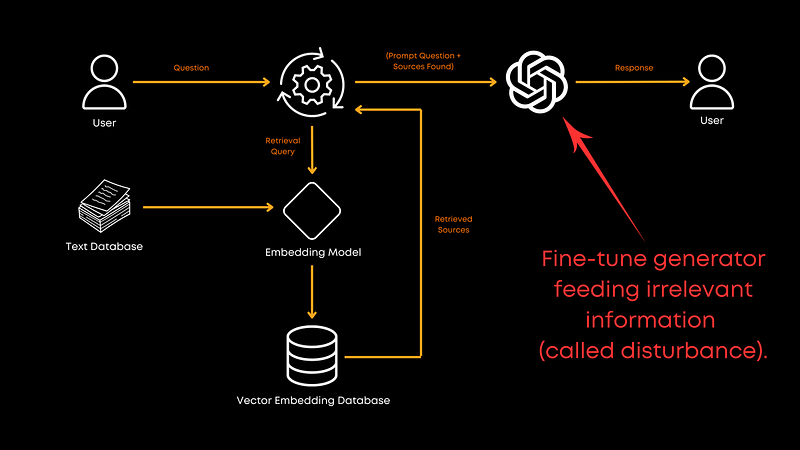
最后,您是否应该微调用于生成的 LLM?绝对!使用相关文档和随机文档的混合进行微调可以提高生成器处理不相关信息的能力。它使模型更加健壮,并有助于它给出更好的整体响应。论文中没有提供确切的比率,但结果很明确:微调是值得的!不过,这显然也取决于您的域。
多模态
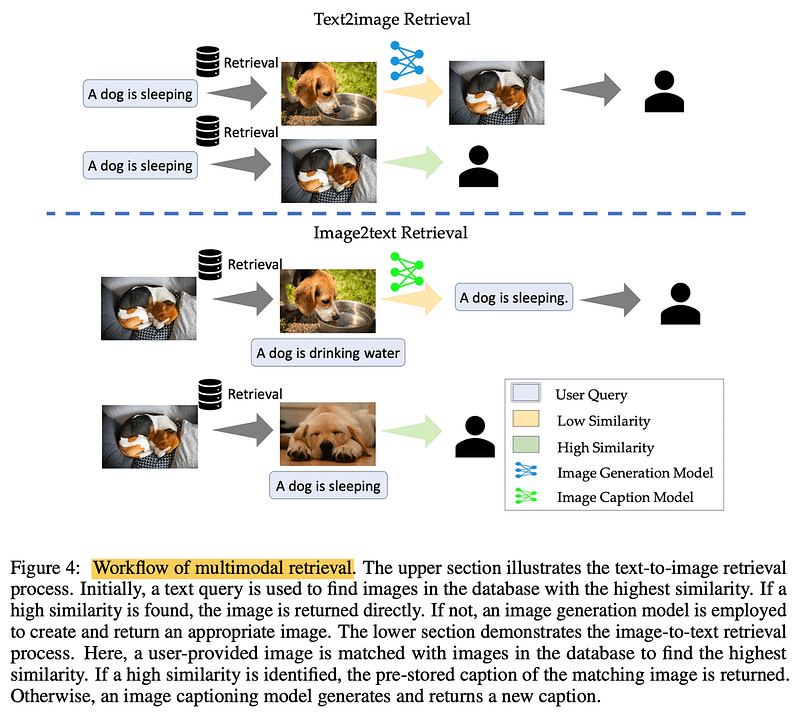
处理图像?实施 多模式 检索。对于文本到图像,在数据库中查询相似图像可以加快该过程。在图像到文本中,匹配相似的图像可检索准确的预存储字幕。这一切都与接地气有关——检索真实的、经过验证的信息。
结论
简而言之,Wang 等人的这篇论文为我们提供了一个构建高效 RAG 系统的坚实蓝图。但请记住,这只是一篇论文,并未涵盖 RAG 管道的各个方面。例如,猎犬和发电机的联合训练没有被探索,这可能会释放更多的潜力。由于成本原因,他们也没有深入研究分块技术,但这是一个值得探索的方向。
