

1 概述
Step-Back Prompting是Google DeepMind团队在论文Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models中提出的一种Prompt技术。
跟CoT要解决的问题类似,本质上都是In-Context Learning,区别在于CoT是让LLM将求解步骤分开,不要一次输出所有结果,但对于一些复杂的数理问题,如果不知道要用什么理论、公式去解决,即使一步步求解也依然无法获得正确的答案,这就是Take a Step Back这篇论文提出的动机,它通过Prompt让LLM“退后一步”,不要直接尝试解决问题,而是思考解决这个问题更高层次、更抽象的问题是什么。
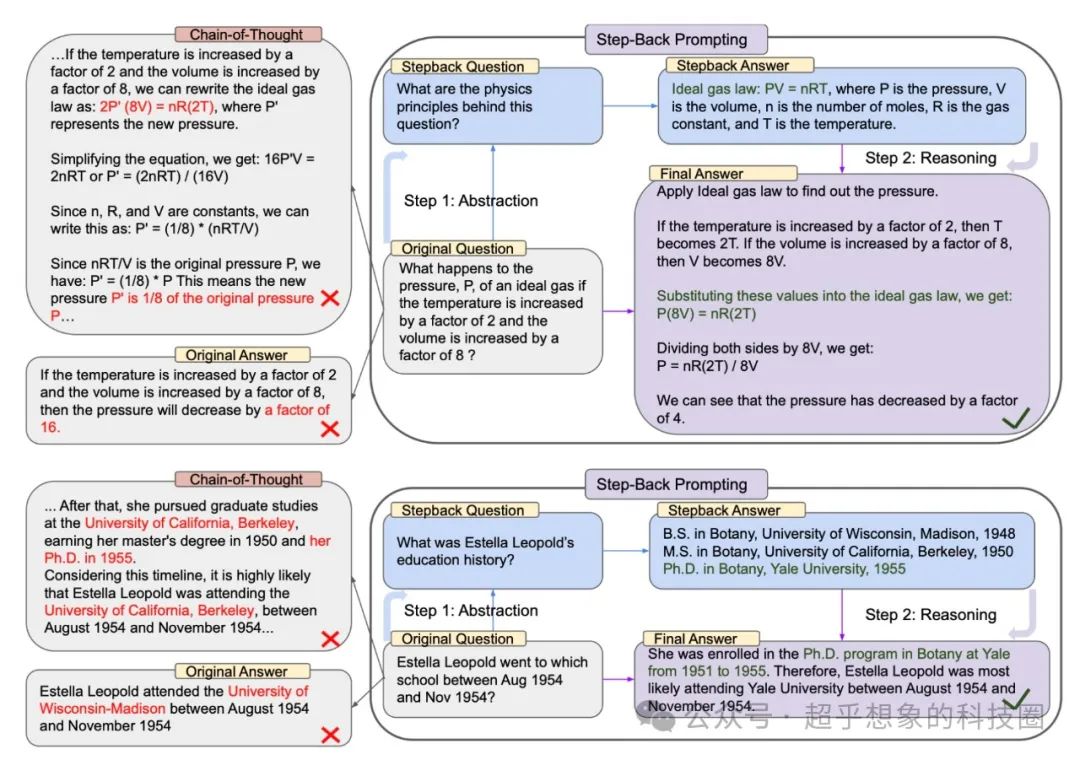
例如论文中所举的例子:“理想气体的压强P,如果温度增加2倍,体积增加8倍会发生什么变化?”,即使使用CoT,LLM也依然无法回答正确,但使用Step-Back Prompting,让LLM先回忆出来理想气体公式,然后让LLM应用这个公式,问题得到顺利解决。又比如“埃斯特拉·利奥波德在1954年8月至1954年11月期间就读于哪所学校?”,这种问题在RAG中直接检索的话,很可能无法检索到正确的知识片段,但如果换成一个更抽象的问题:“埃斯特拉·利奥波德的教育历史是什么”则很有可能检索到正确片段从而正确回答问题。
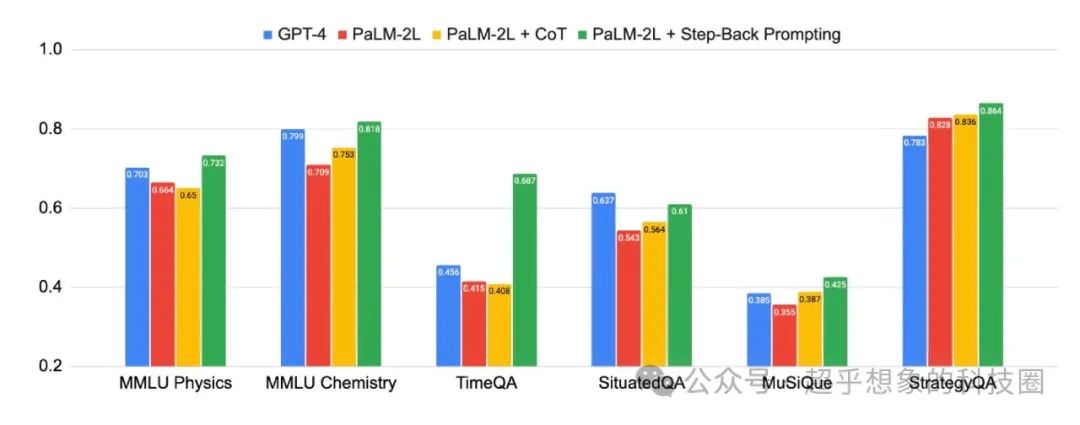
作者在SituatedQA这样的文档问答QA数据集上也进行了测试,效果领先于未使用Step-Back Prompting的同类模型。
2 效果对比
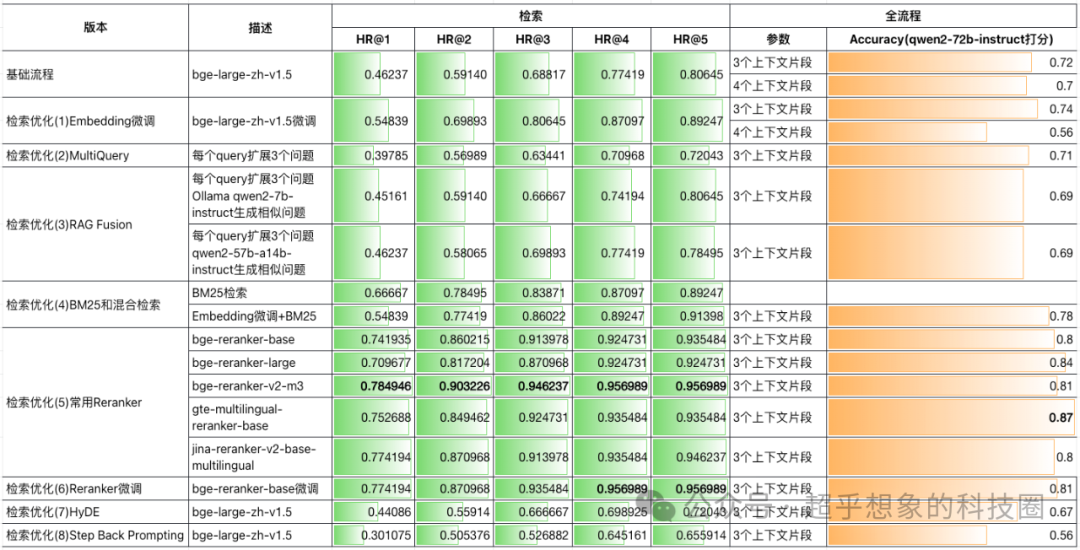
虽然从理论上讲,Step-Back Prompting有其合理性,但在不同场景中效果可能未必有论文中那么好,下面是在本系列文章所构建的测试集中测试的结果,基本上是各种方法中最差的,当然这也并不能说明这个方法无效,只能说明在当前场景下它不是一个有效的优化方法。
3 核心代码
完整代码已开源,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/retrieval/08_step_back_prompting.ipynb
下面核心讲解借助Step Back Prompting进行检索的chain,大致可以分为三个部分:Prompt构建、生成更抽象的问题、检索。
用于生成更抽象问题的Prompt构建:
生成更抽象问题的Chain:
试用一下:
结果:
完整的检索chain:
