RAG 系统通常用于增强 AI 模型的特定领域知识。传统 RAG 方法在编码信息时会丢失上下文,导致检索失败率较高。
"上下文检索" (Contextual Retrieval) 用于改进 RAG 系统中的检索步骤,通过结合语义嵌入和精确匹配技术,显著提高了 RAG 系统的检索准确性,从而提升了 AI 模型在特定领域任务中的表现。
1
传统 RAG 系统工作流程
-
将知识库分割成小块文本 -
使用嵌入模型将文本块转换为向量 -
将向量存储在向量数据库中 -
运行时,根据用户查询检索相关文本块 -
将检索到的文本块添加到提示中
BM25
-
BM25作为补充检索技术。BM25 基于词频-逆文档频率 (TF-IDF) 概念,能够进行精确的词语匹配,特别适用于包含唯一标识符或技术术语的查询。 -
BM25通过考虑文档长度并将饱和函数应用于术语频率来改进这一点,这有助于防止常用词在结果中占主导地位。
结合嵌入和 BM25 的改进 RAG 系统: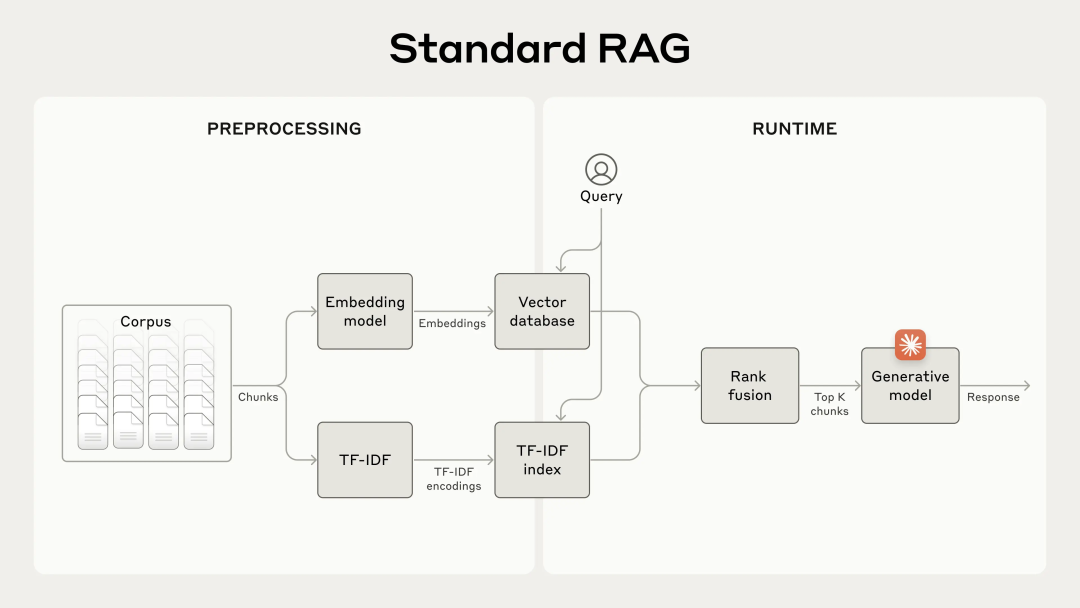
-
分割知识库为小块文本 -
为文本块创建 TF-IDF 编码和语义嵌入 -
使用 BM25 查找基于精确匹配的顶级块 -
使用嵌入查找基于语义相似性的顶级块 -
合并并去重(c)和(d)的结果 -
将顶级 K 个块添加到提示中
2
上下文检索
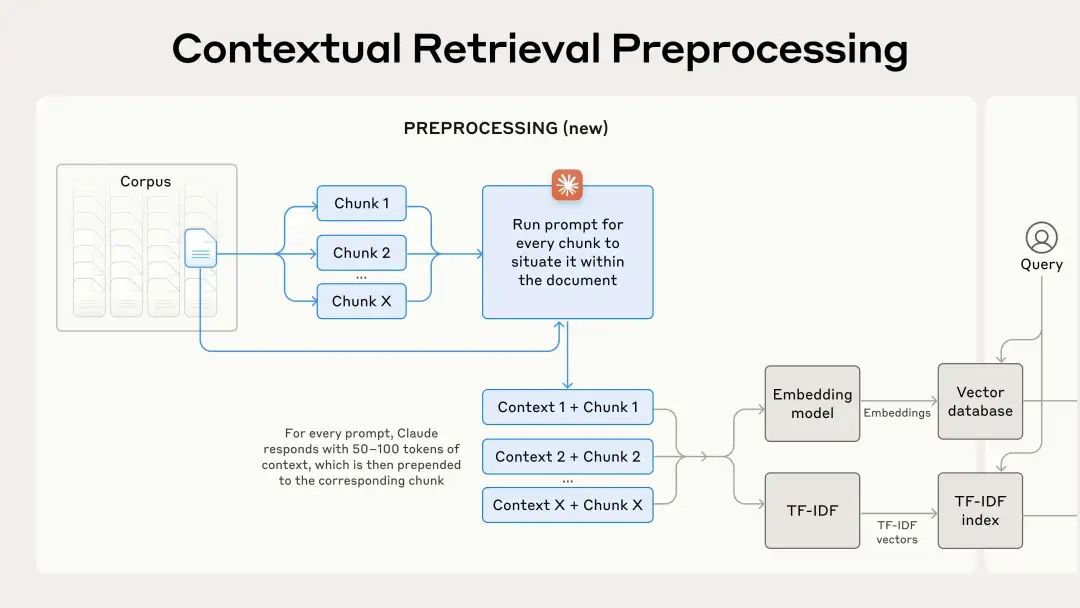
上下文检索通过在嵌入之前为每个块预置特定于块的解释上下文(“上下文嵌入”)并创建 BM25 索引(“上下文 BM25”)来解决这个问题。
文章使用 Claude 3 Haiku 来获取特定于块的上下文,prompt如下:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
实验结果
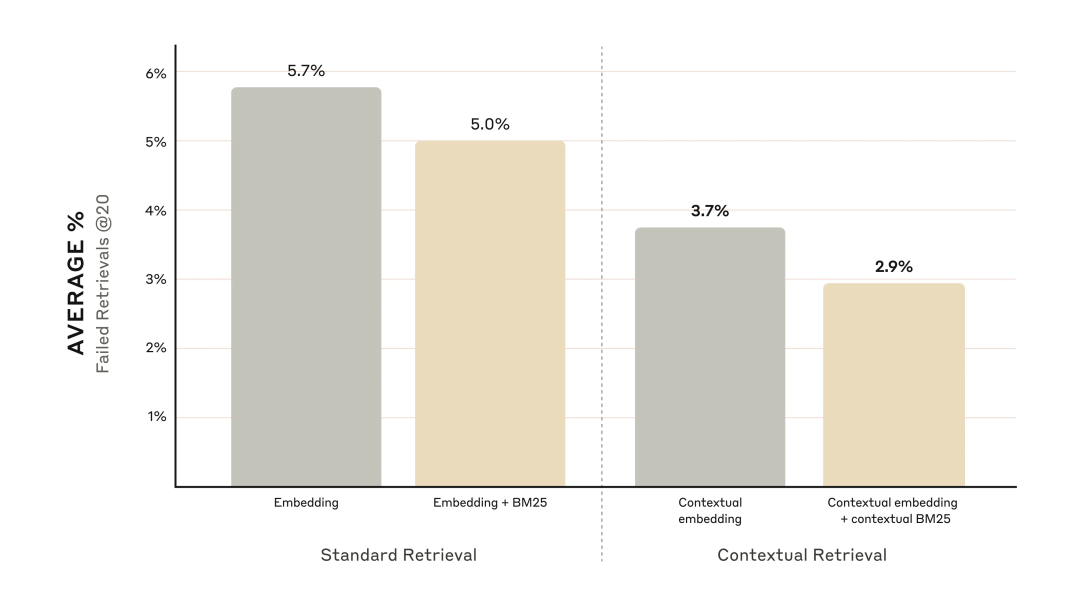
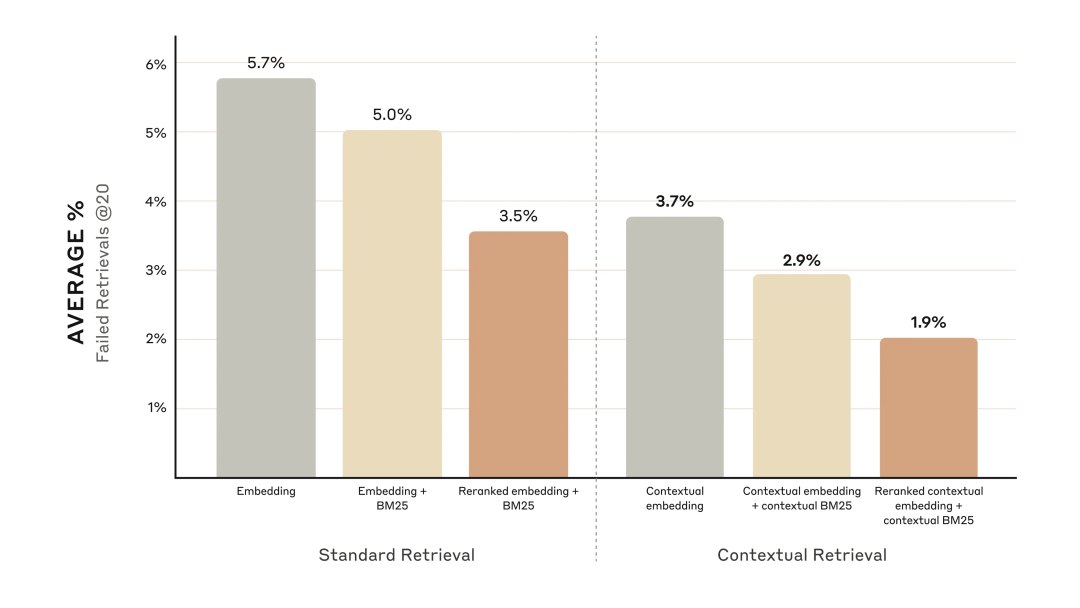
-
上下文嵌入将前 20 个块的检索失败率降低了 35% -
结合上下文嵌入和上下文 BM25 将前 20 个块的检索失败率降低了 49%
通过重排可以进一步提高性能。
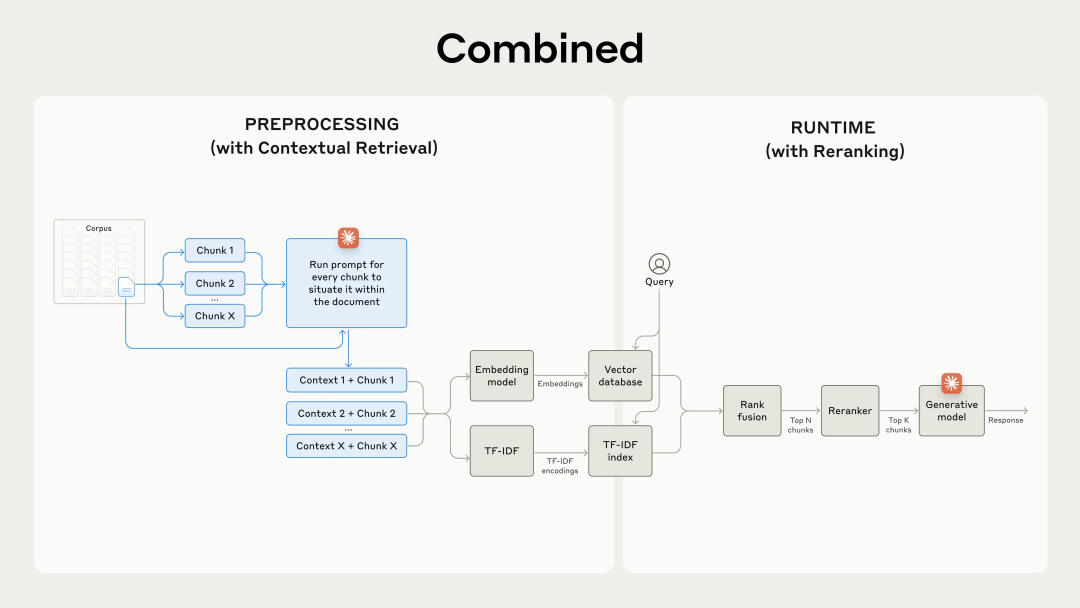 Reranked 上下文嵌入和上下文 BM25 将前 20 个块的检索失败率降低了 67% (5.7% → 1.9%)。
Reranked 上下文嵌入和上下文 BM25 将前 20 个块的检索失败率降低了 67% (5.7% → 1.9%)。