对于大语言模型(Large Language Model,LLM)而言,提出新的想法并不难,真正难的是,提出那些新颖且有价值的想法。如同 Wolfram 所说:“实际上,做出原创性的工作是非常简单的,你只需选择一堆随机数。那些随机数序列非常出人意料、有创意、也很有独创性,但这对我们来说,并没有太大意义,我们真正感兴趣的是那些有原创性而‘有趣’的东西。”毕竟,让用户吃胶水和石头的想法不也是很新颖的吗?
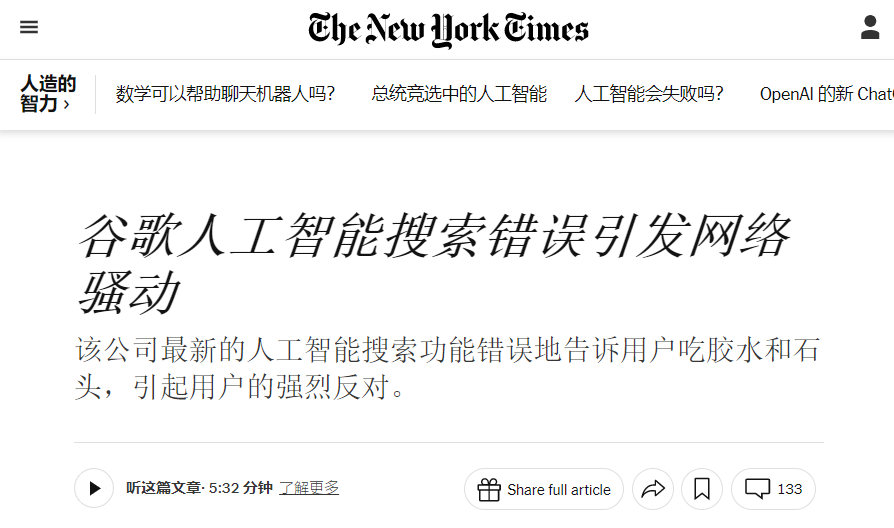
图丨此前谷歌发布的 AI 搜索曾产生一系列的谎言和错误信息,包括建议在披萨食谱中使用胶水以及摄入石头来补充营养等,引起轩然大波(来源:New York Times)因此,要评估 AI 想法的新颖性,必须要附带一个额外条件:它们至少要与人类专家提出的想法水平相当。但目前,还没有相关研究证明 LLM 系统能够生成达到专家水平的新颖想法。 于是,为了弥补这方面研究的缺失,探明 AI 在科学研究中的创新潜力,来自斯坦福大学的研究团队展开了一项研究,对当前 LLM 是否能够生成人类专家级的创新性研究想法进行了探究。
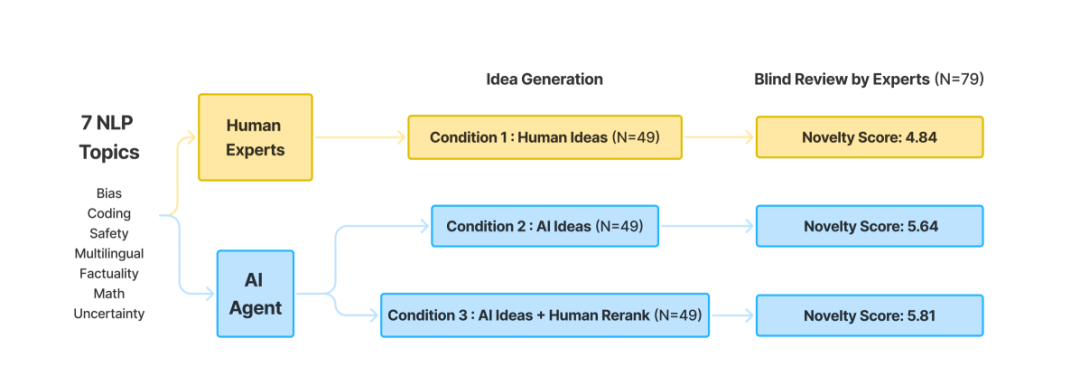
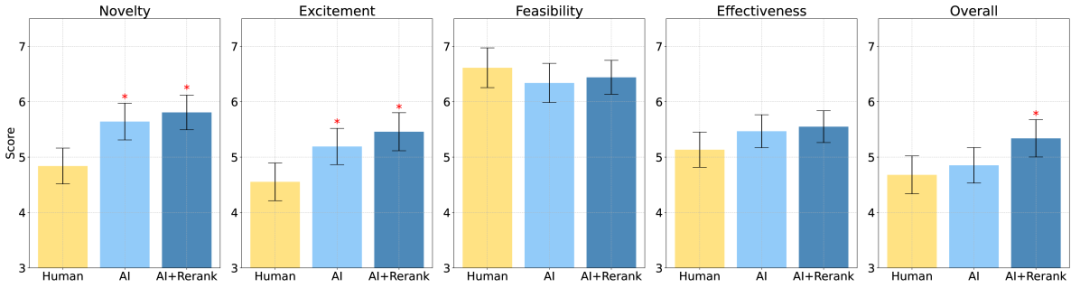
图丨风格标准化工具(来源:arXiv)另一方面,对研究思路的审查也同样不可避免地具有主观性。因此,研究团队参考一些 AI 顶会的评审,设计了一份详细的审查表,明确了所有评估标准,力求使评估过程更加标准化。除了给出总体评分外,还设定了四个具体的评估指标:新颖性、吸引力、可行性和预期效果。评审员需要根据指标给出 1-10 的分数,并附上理由说明。除了人类专家提出的与 AI 自动筛选出(AI Ideas)的想法,研究者还从 AI 生成的想法中手动筛选出了一些最为优秀的(AI Ideas + Human Rerank),以评估 AI 创意的最大潜力。图丨实验流程图(来源:arXiv)最终的结果如上所述,无论是 AI Ideas 还是 AI Ideas + Human Rerank,都在新颖性方面显著优于人类专家的想法(p < 0.01)。在可行性方面,则稍有逊色。而在激动人心(excitement)评分上,AI 生成的思路的优势更为明显(p < 0.05)。