


论文链接: https://arxiv.org/pdf/2408.00798
背景
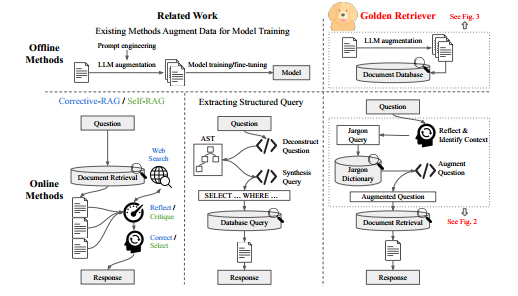
方法
1. 离线部分:文档增强

2. 在线部分:交互流程
-
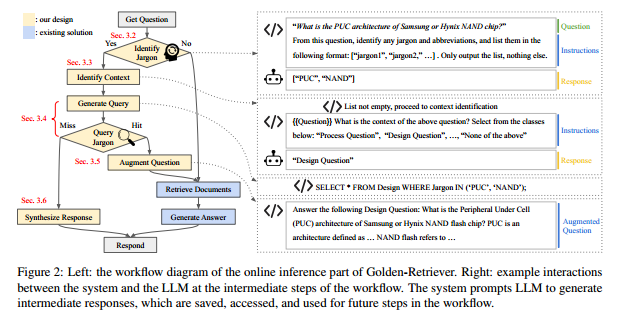
识别术语(Identify Jargons):首先,系统会识别问题中的术语和缩写,这一任务由 LLM 处理,因为传统的字符串匹配方法难以应对术语的拼写错误或未包含在词典中的新术语。识别出的术语将以结构化的格式保存,以便在后续的处理流程中使用。 -
识别上下文(Identify Jargons):由于术语的意义在不同上下文中可能不同,Golden-Retriever接着识别问题的上下文。例如,"RAG"在不同领域有不同的含义(如LLM领域中的“检索增强生成”与遗传学中的“重组激活基因”)。通过设计包含预定义上下文名称及描述的提示模板,LLM能够识别出问题所处的语境。通过这种方式,Golden-Retriever在检索文档之前准确澄清了术语的上下文,确保检索更为精准。 -
查询术语(Query Jargons):一旦术语和上下文被识别出来,系统会查询术语词典以获取扩展定义、详细描述及相关备注。查询的SQL代码通过安全可靠的代码生成,而非使用LLM生成,以确保查询的质量和安全性。 -
增强问题(Augment Question):通过将术语定义和上下文信息与原始问题整合,系统生成增强后的问题。这一过程确保RAG在检索时能够准确理解问题的背景和术语,从而提升检索文档的相关性。 -
查询未命中响应(Query Miss Response):如果系统无法找到某些术语的相关信息,Golden-Retriever会生成一个响应,提示用户检查术语拼写或联系知识库管理员添加新术语。这样可以避免误导性回答,并保持系统的高准确性。
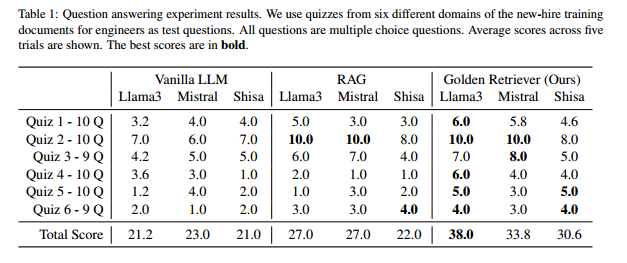
实验
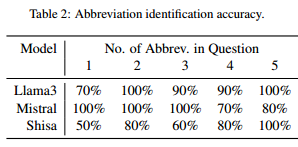
总结
