

01
—
RAG的产品形态
随着RAG技术的发展和演变,RAG产生了Naive RAG、Advanced RAG、Modular RAG。
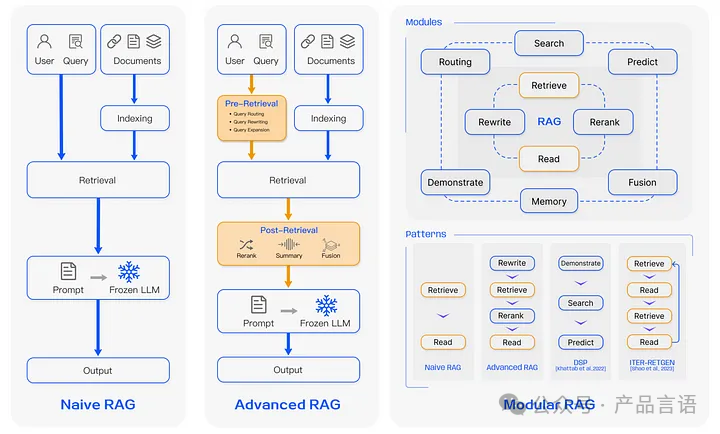
Naive RAG
Advanced RAG
Modular RAG
02
—
RAG产品建设路径
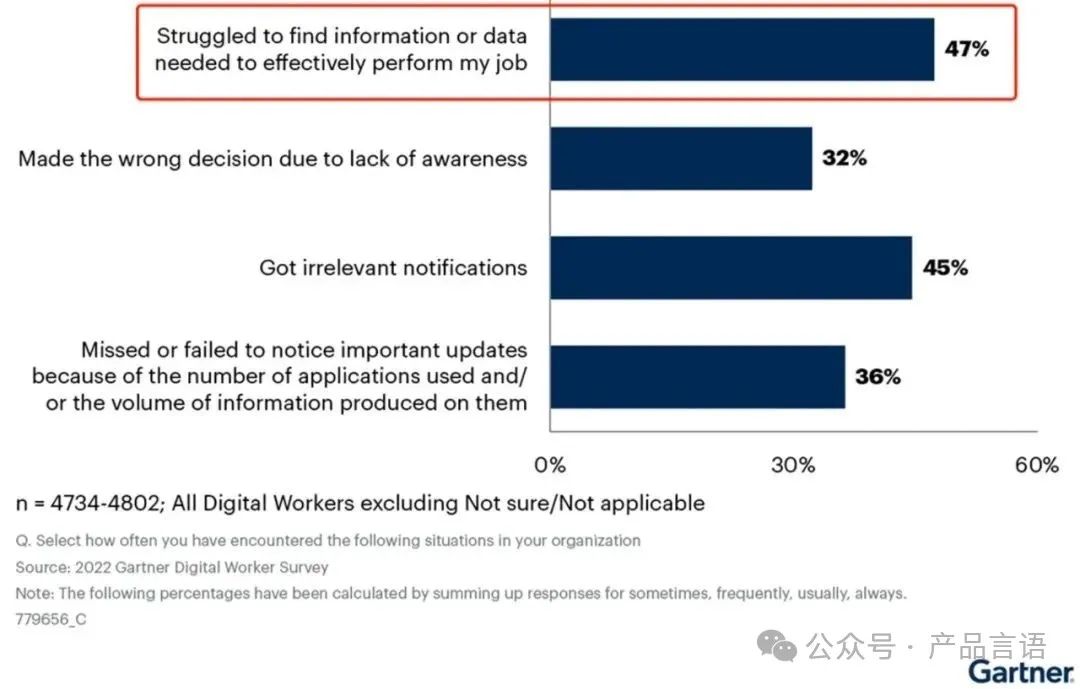
RAG整理业务链路划分为5个步骤:知识生产加工、query改写、数据召回、后置处理以及大模型生产;
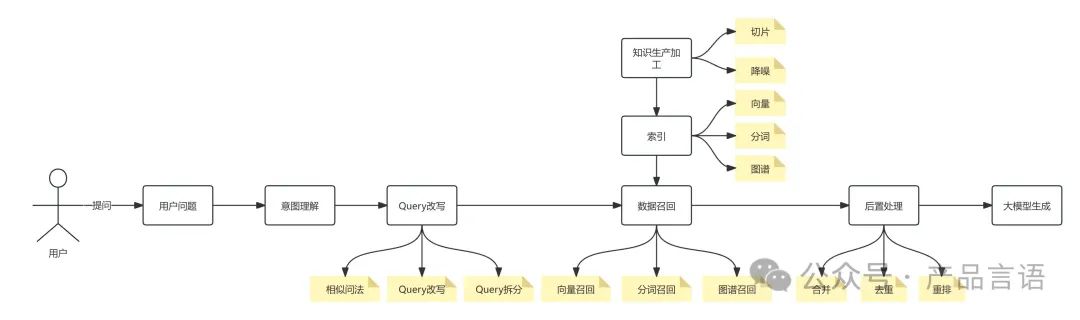
第一阶段:可运行
-
知识生产与加工:
-
支持问答对类型; -
支持长文本类型:先按照固定字符切分,预留冗余字段保证语义不被截断;
-
query改写:结合上下文,使用大模型理解能力,更好回答用户问题; -
数据召回:实现向量召回,找到契合的embedding模型和向量数据库。 -
数据后置处理:设置符合业务预期的阈值筛选数据,主要是文本匹配度和召回数;
第二阶段:提效果
-
知识生产与加工:
-
按照语义进行切分,将上下文联系紧密的句子切分成一个片段; -
根据数据索引情况,分析索引噪音,制定降噪策略;
-
query改写:
-
根据用户query生成多相似query检索数据; -
多任务query抽取,将用户的query拆解为多个任务query;
-
数据召回:
-
根据业务场景探索向量、分词、图谱召回的能力;
-
数据后置处理:
-
数据去重合并; -
多路召回结果重排能力;
第三阶段:高扩展
-
功能模块化建设:
-
建设通用模块能力,方便业务接入组合不同的RAG检索系统,满足业务效果。
-
回答能力建设:
-
问答的调试预览; -
回答过程白盒化; -
基于问题和回答的问题推荐;
-
数据质量差导致检索效果差:检索阶段的输出影响生成阶段的输入和最终的输出质量。RAG数据库中存在大量的错误信息并检索到,可能导致模型生成的错误,即使在检索阶段做大量工作,可能对结果的影响也微乎其微。 -
数据向量化的信息缺失:数据向量化缺失可能会导致一定程度的信息损失,文本数据的复杂性和多样性很难用有限的向量来完全表达,导致向量化后可能会缺失一些文本数据的细节和特征,从而影响文档检索的准确率。 -
语义搜索的不准确:语义检索利用向量空间中的距离和相似度来进行检索,准确率无法100%保障。
03
—
结语
RAG问答系统搭建做出来比较容易,但想做好比较难的,流程中的每一个步骤都有可能对最终效果产生影响。在RAG中需要做大量的探索如不同文档的切分方式、query改写策略、数据如何找回等等。面向企业的知识更有很多难点需要解决,企业中有不同的部门,同一个部门有不同的角色,对应的知识的权限不同,以及还涉及到外部合作伙伴的权限,在不同的权限交互下,处理起来非常复杂。因此做好一个企业内部的RAG智能问答任重而道远。
