

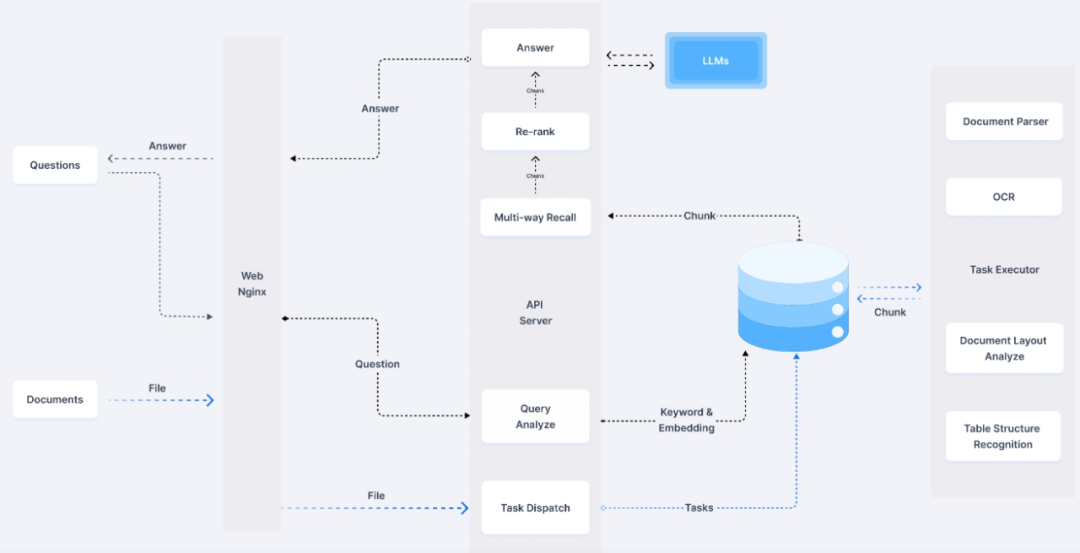
–文档解析器:这是 RAGFlow 系统的“大脑”,负责将各种格式的文档进行解析,从中提取出文本、图像和表格等关键内容。无论是PDF、Word文档还是Excel表格,文档解析器都能够准确捕捉信息,为后续的处理打下基础。
– 查询分析器:这个组件是 RAGFlow 系统的“神经系统”,它对用户的查询进行深入分析,识别并提取出查询中的关键信息。通过这种分析,系统能够更准确地理解用户的需求,为检索工作提供精确的指导。
– 检索:这是 RAGFlow 系统的“搜索引擎”,它使用查询分析器提供的关键信息,从海量文档中快速检索出与之相关的信息。检索组件的强大能力保证了用户能够及时获得所需的数据。
– 重排:这个组件是 RAGFlow 系统的“过滤器”,它对检索到的信息进行排序和过滤,确保最终呈现给用户的信息是最相关、最有价值的。通过这种方式,系统能够去除冗余和不相关的数据,提高信息的准确性和可用性。
– LLM:作为 RAGFlow 系统的“语言生成器”,LLM(大型语言模型)负责将排序后的信息整合并生成最终的答案或输出。LLM的强大生成能力不仅能够确保答案的准确性,还能够使答案表达得更加自然和流畅。
1. "Quality in, quality out"
-
基于对知识文档的深度理解,能够从各类格式复杂的非结构化数据中提取真实有效的内容。
-
真正在无限上下文(token)的场景下快速完成大海捞针测试。
-
强调文档的精细化解析,并且在文档解析上做了不少优化。
2. 基于模板的文本切片
-
不仅仅是智能,更重要的是可控可解释。
-
多种文本模板可供选择
-
有理有据、最大程度降低幻觉(hallucination)
-
文本切片过程可视化,支持手动调整。
-
有理有据:答案提供关键引用的快照并支持追根溯源。
3. 兼容各类异构数据源
-
支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。
4. 全程无忧、自动化的 RAG 工作流
-
全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。
-
大语言模型 LLM 以及向量模型均支持配置。
-
基于多路召回、融合重排序。
-
提供易用的 API,可以轻松集成到各类企业系统。

 –THE END–
–THE END– 
