01。
概述
02。
优势
-
为了形成手动研究任务的客观结论可能需要时间,有时需要数周来找到正确的资源和信息。
-
当前的大型语言模型(LLMs)训练于过去和过时的信息,存在产生幻觉的高风险,使它们在研究任务中几乎变得不相关。
-
当前的大型语言模型仅限于短标记输出,这不足以满足长篇详细的研究报告(2000字以上)。
-
提供网络搜索服务的系统(如ChatGPT + Web插件)只考虑有限的来源和内容,有时会导致错误信息和肤浅的结果。
-
仅使用部分网络资源可能会在确定研究任务的正确结论时产生偏见。
03。
Demo
https://private-user-images.githubusercontent.com/13554167/321903110-dd6cf08f-b31e-40c6-9907-1915f52a7110.mp4?jwt=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJnaXRodWIuY29tIiwiYXVkIjoicmF3LmdpdGh1YnVzZXJjb250ZW50LmNvbSIsImtleSI6ImtleTUiLCJleHAiOjE3MjI4NjgyODYsIm5iZiI6MTcyMjg2Nzk4NiwicGF0aCI6Ii8xMzU1NDE2Ny8zMjE5MDMxMTAtZGQ2Y2YwOGYtYjMxZS00MGM2LTk5MDctMTkxNWY1MmE3MTEwLm1wND9YLUFtei1BbGdvcml0aG09QVdTNC1ITUFDLVNIQTI1NiZYLUFtei1DcmVkZW50aWFsPUFLSUFWQ09EWUxTQTUzUFFLNFpBJTJGMjAyNDA4MDUlMkZ1cy1lYXN0LTElMkZzMyUyRmF3czRfcmVxdWVzdCZYLUFtei1EYXRlPTIwMjQwODA1VDE0MjYyNlomWC1BbXotRXhwaXJlcz0zMDAmWC1BbXotU2lnbmF0dXJlPTIwMGVkNDk1MGNkMWE0MDhlNzA4ZDA1YzVhN2I5ZDc4MjIwYzkyNzA0NDQ4NGU5YTU2NmU1NTU5ZjJiMjdmZTImWC1BbXotU2lnbmVkSGVhZGVycz1ob3N0JmFjdG9yX2lkPTAma2V5X2lkPTAmcmVwb19pZD0wIn0.vshdZR7nuSwbB4lbWH_0mvT3_4YdEU_QYZM-Q7O2C5g

04。
架构
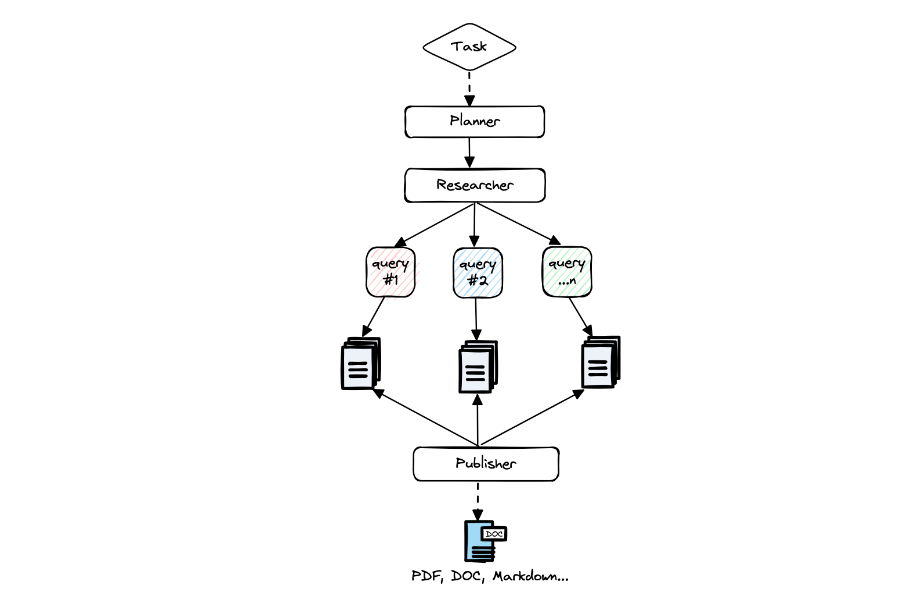
-
根据研究查询或任务,创建一个特定领域的代理。 -
生成一组研究问题,这些问题共同构成对任何给定任务的客观意见。 -
对于每个研究问题,激活一个爬虫代理,该代理在网络上抓取与给定任务相关的信息资源。 -
对于每个抓取的资源,根据相关信息进行总结,并记录其来源。 -
最后,过滤和汇总所有总结过的来源,并生成最终的研究报告。