-
用于提交知识(文本)的接口,该接口用于把网站或客户端的知识集中到后端服务中向量化存储
-
用于提问/查询的接口,该接口用于从知识库中获得结果
-
用于列出所有提问的接口
-
用于对单一提问进行人工回答的接口
什么是RAG知识库?
RAG知识库通用技术架构

基于LangChain在NodeJS中实现RAG
import { ChatOllama } from "@langchain/ollama";export function initOllamaChatModel() {const llm = new ChatOllama({model: "llama3",temperature: 0,maxRetries: 2,// other params...});return llm;}当然,这里,你需要先用ollama把llama3跑起来。 Embedding Model
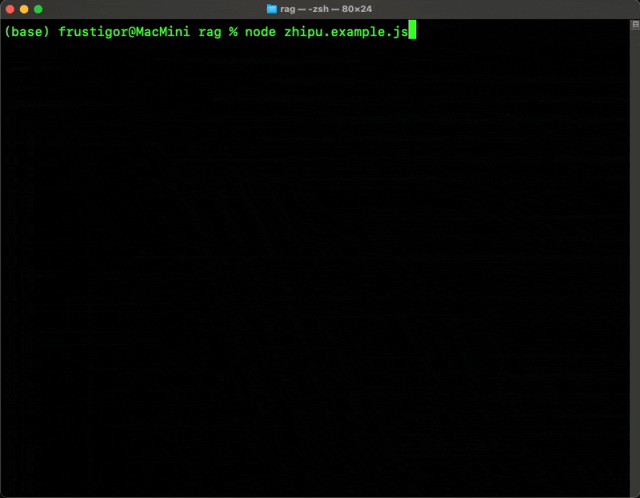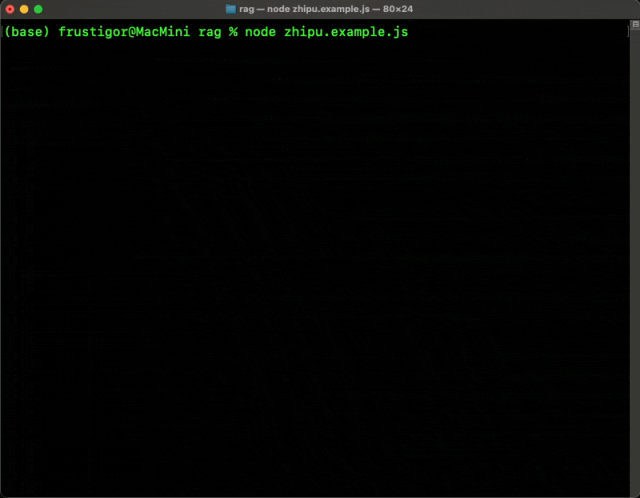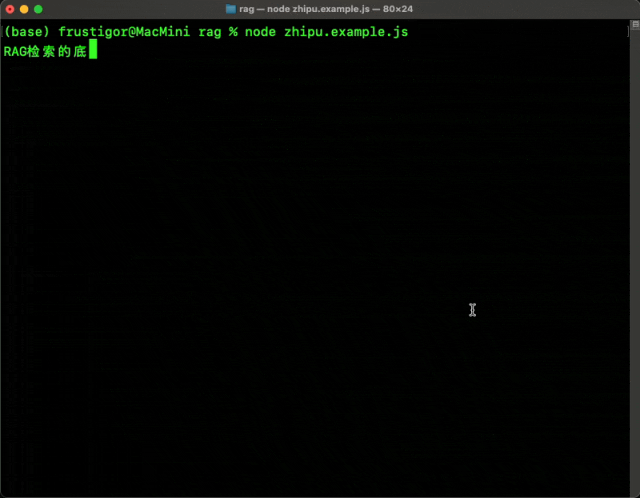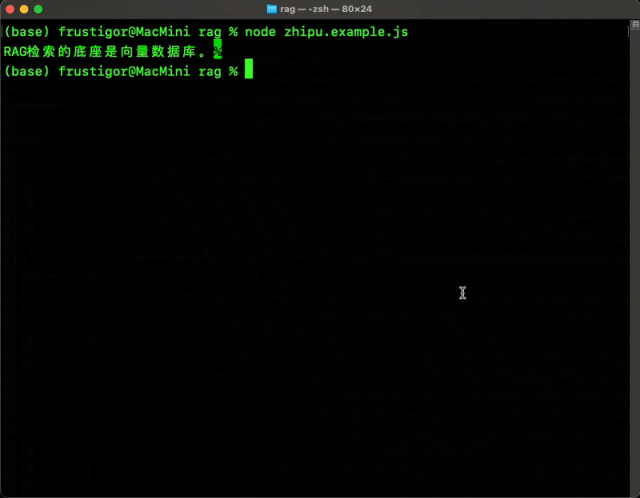
import { OllamaEmbeddings } from "@langchain/ollama";epxort function initOllamaEmbeddings() {const embeddings = new OllamaEmbeddings({model: "mxbai-embed-large", // Default valuebaseUrl: "http://localhost:11434", // Default value});return embeddings;}TextLoader 我打算把所有的内容,都以纯文本的形式进行载入。你也可以使用其他的loader载入如txt、pdf、docx等文件或网页。 import { Document } from "@langchain/core/documents";export async function loadPureText(text, metadata) {const docs = [new Document({pageContent: text,metadata,}),];return docs;}TextSplitter 对大文本进行分片。 import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';export async function splitTextDocuments(docs) {const textSplitter = new RecursiveCharacterTextSplitter({chunkSize: 1000,chunkOverlap: 200,});return await textSplitter.splitDocuments(docs);}Vector Store 使用faiss作为向量数据库,节省成本,可本地存储,方便部署和迁移。 import { FaissStore } from "@langchain/community/vectorstores/faiss";export function createFaissVectorStore(embeddings) {return new FaissStore(embeddings, {});}export async function searchFromFaissVectorStore(vectorStore, searchText, count) {const results = await vectorStore.similaritySearch(searchText, count);return results;}export async function addDocumentsToFaissVectorStore(vectorStore, docs, ids) {return await vectorStore.addDocuments(docs, { ids });}export async function deleteFromFaissVectorStore(vectorStore, ids) {return await vectorStore.delete({ ids });}/** 备份 */export async function saveFaissVectorStoreToDir(vectorStore, dir) {await vectorStore.save(dir);}/** 恢复 */export async function loadFaissVectorStoreFromDir(dir, embeddings) {const vectorStore = await FaissStore.load(dir, embeddings);return vectorStore;}Prompt 构建常用的RAG prompt模板。 import { ChatPromptTemplate } from "@langchain/core/prompts";export function createRagPromptTemplate() {const promptTemplate = ChatPromptTemplate.fromTemplate(`You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: {question}Context: {context}Answer:`);return promptTemplate;}RAGApplication 最后,是把上面的这些部分组合起来。 import { createStuffDocumentsChain } from "langchain/chains/combine_documents";import { StringOutputParser } from "@langchain/core/output_parsers";import path from 'path';import fs from 'fs';export async function createRagApplication() {const llm = initOllamaChatModel();const embeddings = initOllamaEmbeddings();const faissStoragePath = path.join(__dirname, 'faiss');const isFaissExist = fs.existsSync(faissStoragePath);const vectorStore = isFaissExist ? await loadFaissVectorStoreFromDir(faissStoragePath, embeddings) : createFaissVectorStore(embeddings);const saveTo = () => {if (!isFaissExist) {fs.mkdirSync(faissStoragePath, { recursive: true });}return saveFaissVectorStoreToDir(vectorStore, faissStoragePath);};const retriever = vectorStore.asRetriever(options.retriever);const prompt = createRagPromptTemplate();const chain = await createStuffDocumentsChain({llm,prompt,outputParser: new StringOutputParser(),});/**** @param {string} text* @param {{* type: string; // 类型* id: string | number; // 标识* }} meta*/const addText = async (text, meta) => {const docs = await loadPureText(text, meta);const docsToAdd = await splitTextDocuments(docs);const { type, id } = meta;const ids = docsToAdd.map((_, i) => `${type}_${id}_${i}`);await addDocumentsToFaissVectorStore(vectorStore, docsToAdd, ids);await saveTo(); // 每次新增向量之后,自动保存到目录中return ids;};/*** @param {string[]} ids*/const remove = async (ids) => {await deleteFromFaissVectorStore(vectorStore, ids);await saveTo();};const query = async (question) => {const context = await retriever.invoke(question);const results = await chain.invoke({question,context,})return results;};const stream = async (question) => {const context = await retriever.invoke(question);const results = await chain.stream({question,context,})return results;};return {addText,remove,query,stream,};}当然,这里你需要把前面的所有函数都引入进来。 Example 最后,我们来写一个例子,用以测试它是否正常工作: const rag = await createRagApplication();await rag.addText(`RAG 检索的底座:向量数据库,我的博客 www.tangshuang.net 中有专门的内容对向量数据库做介绍。在业界实践中,RAG 检索通常与向量数据库密切结合,也催生了基于 ChatGPT + Vector Database + Prompt 的 RAG 解决方案,简称为 CVP 技术栈。这一解决方案依赖于向量数据库高效检索相关信息以增强大型语言模型(LLMs),通过将 LLMs 生成的查询转换为向量,使得 RAG 系统能在向量数据库中迅速定位到相应的知识条目。这种检索机制使 LLMs 在面对具体问题时,能够利用存储在向量数据库中的最新信息,有效解决 LLMs 固有的知识更新延迟和幻觉的问题。尽管信息检索领域也存在选择众多的存储与检索技术,包括搜索引擎、关系型数据库和文档数据库等,向量数据库在 RAG 场景下却成为了业界首选。这一选择的背后,是向量数据库在高效地存储和检索大量嵌入向量方面的出色能力。这些嵌入向量由机器学习模型生成,不仅能够表征文本和图像等多种数据类型,还能够捕获它们深层的语义信息。在 RAG 系统中,检索的任务是快速且精确地找出与输入查询语义上最匹配的信息,而向量数据库正因其在处理高维向量数据和进行快速相似性搜索方面的显著优势而脱颖而出。以下是对以向量检索为代表的向量数据库与其他技术选项的横向比较,以及它在 RAG 场景中成为主流选择的关键因素分析:`, { type: 'text', id: 0 });const results = await rag.stream('RAG检索的底座是什么?');for await (const chunk of results) {process.stdout.write(chunk);}在命令行中运行上面这个js,就可以看到效果。如果运行正常,说明我们的编码没有问题。
需要注意的点 上面实现中,只提供了addText纯文本写到向量库中,你可以根据你自己的实际需求,利用langchain提供的loader,实现各种形式的载入。 另外,上面的实现中,只从RAG的通用架构角度进行了技术实现,而没有从应用出发,去进行缓存、去重等一系列的应用层设计。它相当于是一个通用的代码,任何nodejs项目都可以拿去用,再在它的上层进行更深度的业务封装。我自己就是在这样的基础上,封装了FAQ系统,当用户发起提问的时候,从知识库中捞取知识进行回答,同时,在业务上,我又增加了运营人员手工回答来覆盖AI回答,同时,又把人工回答再载入到知识库中,从而使得将来类似问题可以被更好的回答。 结语
虽然我在去年就在腾讯内网发布了如何用nodejs来实现RAG的文章,但是随着langchain的进步,以及市场上各类底层服务的完善,现在构建RAG已经变得轻而易举。本文算是我闲暇时,保持博客更新的一篇总结吧,毕竟对于不少朋友来说,还是需要有一篇类似的文章引导的。我在翻看langchain文档时,发现不少工具是nodejs独享的,python没有,这说明js社区的强大。而随着AI技术的不断普及化,以及LLM上下文长度的提升,在不考虑tokens的费用的情况下,或许我们真的可以做到不需要向量化来实现RAG知识库。对了,文章开头说的FAQ接口服务,我会在近期放出,你只需要持续关注我,适当的时候,它就会出现。