

原理
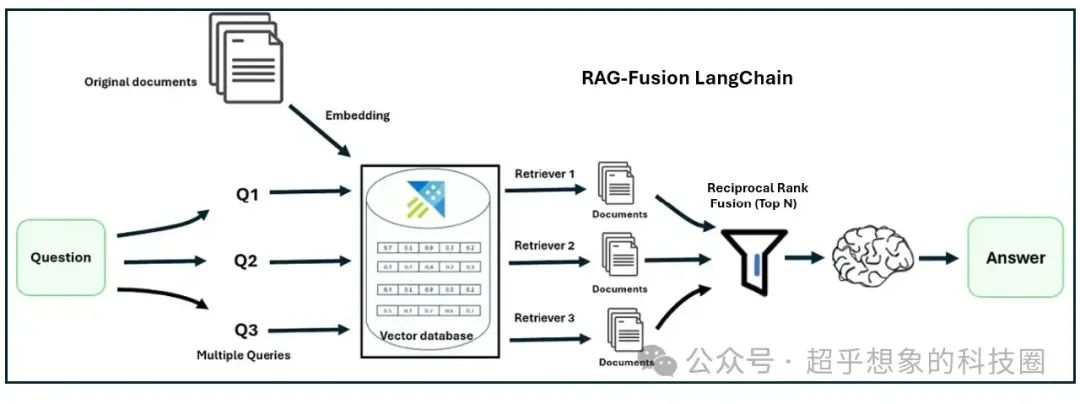
在使用RAG技术构建企业级文档问答系统:检索优化(2)Multi Query中介绍了如何借助大语言模型生成相似问,从而避免query中由于措辞原因导致检索失败,熟悉搜索推荐的小伙伴应该能看出来,这其实是做了扩召回,通常情况下,只要后续的粗排、精排、重排性能扛得住,扩召回总是能提高搜推效果的,但我们在上次的实验中却发现,在RAG中,使用MultiQuery却并没有带来检索性能的提升,我们在文末也分析了原因,主要是在当前Langchain实现中,只是把结果做了去重,其实并没有排序,当然也与问题、文档有关,也可以调节每个相似问召回的数量,和最终总的召回数量,在部分项目中,是可以超过baseline的,但不进行排序只去重终究是一种浪费。本文介绍一种新的检索优化技术,RAG Fusion,这种技术会对多路召回的结果通过一个称为RRF(Reciprocal Rank Fusion)的简单公式进行排序,RRF排序计算简单,并不会大幅增加线上开销,却在不少场景中可以取得很好的效果,原理如下图:
 来源:https://medium.com/@kbdhunga/advanced-rag-rag-fusion-using-langchain-772733da00b7
来源:https://medium.com/@kbdhunga/advanced-rag-rag-fusion-using-langchain-772733da00b7
总体流程如下:
-
首先使用原始问题,生成多个相似问题:这一步,在我们的示例中使用LLM生成相似问,但在有些企业中,可能会结合业务,通过对query进行改写、纠错等生成其他问题
-
然后拿多个(图中是3个)相似问题分别检索文档,这一步其实相当于扩召回
-
然后拿这多个相似问题检索到的文档片段,统一使用RRF排序,最后根据RRF的得分截断知识片段
-
基于问题和知识片段生成最终答案
RRF的应用,不止本文所介绍的对相似问检索的文档进行排序,还可以对混合检索结果进行排序,下一篇文章会介绍到
公式
RRF的计算通常使用以下公式:
其中:
-
表示文档的最终评分
-
表示文档 在第 个检索系统中的排名,一共个检索系统
-
是一个常数,用于平滑排名,防止排名过高的文档过于主导结果,文献中常见的值为60,某些情况下也常设置为1,用于强调排名较高的文档
举例说明
假如原始问题是“报告的发布机构是什么?”,生成的3个相似问分别是:
-
报告是由哪个组织发布的?
-
谁能找到报告的来源?
-
什么实体负责公布这份报告?
为方便计算,假设RRF公式中的设置为1,设置每个相似问题检索5个文档片段,最终进入LLM生成时截断为3个文档片段,他们三个相似问召回的文档片段分别如下:
-
报告是由哪个组织发布的?→ [A, B, C, D, E]
-
谁能找到报告的来源?→ [A, D, C, E, B]
-
什么实体负责公布这份报告?→ [A, B, D, E, C]
分别计算这5篇文档的RRF分:
RRF(A)=1/(1+1)+1/(1+1)+1/(1+1)=1.5
RRF(B)=1/(2+1)+1/(5+1)+1/(2+1)=0.833
RRF(C)=1/(3+1)+1/(3+1)+1/(5+1)=0.666
RRF(D)=1/(4+1)+1/(2+1)+1/(3+1)=0.783
RRF(E)=1/(5+1)+1/(4+1)+1/(4+1)=0.566
根据RRF的得分,最终进入LLM的知识片段为A, B, D
效果对比
与前几次实验的综合效果对比如下图所示: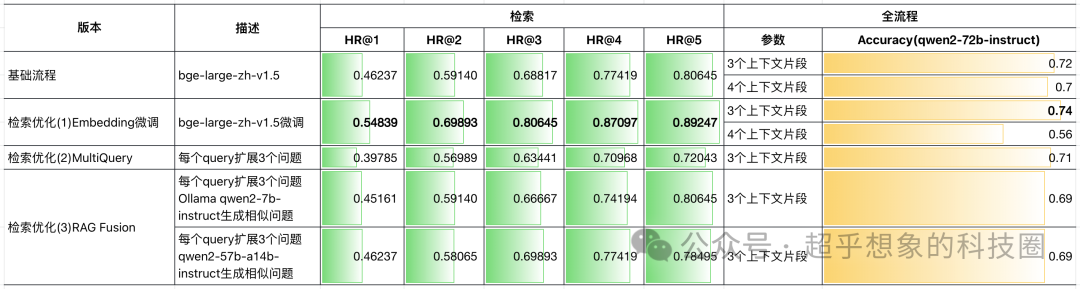
分别对应如下几篇文章:使用RAG技术构建企业级文档问答系统之基础流程
使用RAG技术构建企业级文档问答系统:检索优化(1)Embedding微调
使用RAG技术构建企业级文档问答系统:检索优化(2)Multi Query
从图中可以看出,相比MultiQuery,不同检索数量的结果都有提升,但却没有超过基础流程,但这并不意味着RAG Fusion这个方法无效,由于场景不同,涉及到的参数不同,文中只是对典型参数进行了实验,代码中将相关的参数都留了出来,感兴趣的小伙伴可以自行尝试
核心代码
本文代码已开源,完整流程和性能评估请查看源代码,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/retrieval/03_rag_fusion.ipynb
RRF计算公式
RAG Fusion检索器
使用:
结果
为了方便调参,也可以使用下面这个函数:
