目前,市面上有各种不同的大模型部署工具,比如ollama、vllm、sglang等,但是很多人还并不了解大模型文件格式之间的区别,本次我们来聊一下ollama专用的GGUF格式。
GGUF 格式的全名为(GPT-Generated Unified Format),由llama.cpp创始人Georgi Gerganov设计的二进制文件格式,专为高效存储和加载大模型优化。
简单来说就是,模型在训练完成之后需要对架构、参数等进行存储,用的格式是GGUF。
在传统的大模型开发中多数使用 PyTorch 进行开发,但在部署时会面临依赖包太多、版本管理等问题,因此才有了GGUF格式(GGUF是长时间优化后的产物)。
GGUF文件主要是因为它针对大模型的存储、加载和部署场景进行了多项优化,解决了传统格式的痛点。包含了所有的模型信息(如元数据、张量数据),同时支持跨平台使用,无需依赖外部文件或复杂配置。
GGUF作为一种二进制格式,相较于文本格式的文件,可以更快地被读取和解析。二进制文件通常更紧凑,减少了读取和解析时所需的I/O操作和处理时间。
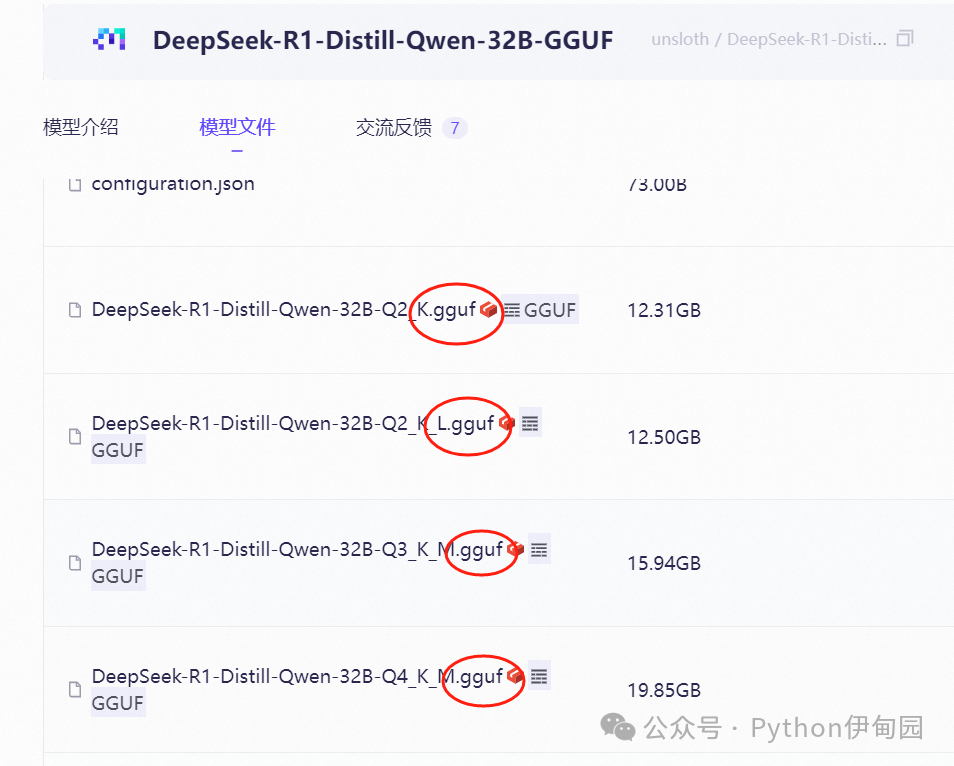
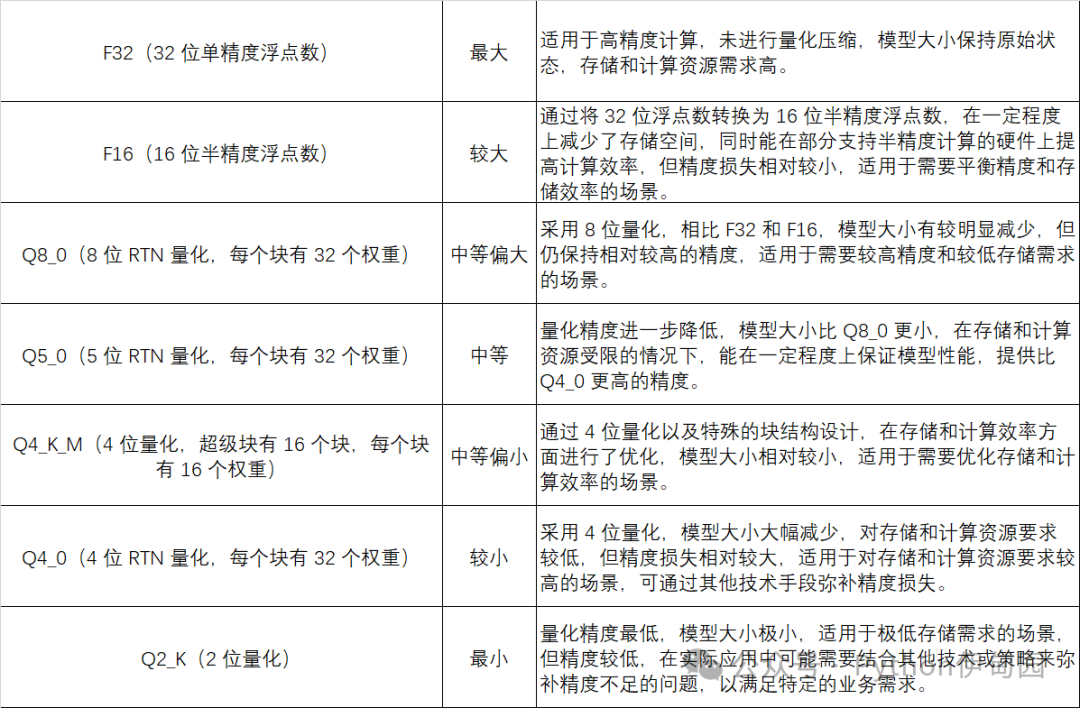
GGUF支持多种量化类型(如Q8_K、Q6_K等),通过降低模型精度减少文件大小,适用于不同硬件资源场景。
GGUF支持多种量化类型,每种类型都有其特定的位宽和量化方法,以满足不同的性能和精度需求。以下是一些常见的量化类型:
主要用于llama.cpp项目,支持GPU、CPU推理。
常见的llama.cpp项目有ollama、LMStudio、LocalAI等。
以ollama平台为例,其默认下载的模型通常是 4-bit 量化,也就是 Q4_0 的压缩方式。
以DeepSeek-R1:32B模型为例。B指参数量为10亿,那么32B就是存在320亿模型参数。
模型有 32×10**9个参数。
原始精度为 FP16,每个参数占用 16 位或 2 字节
总字节数=32×10**9×2=64×10**9字节=64GB
总位数(量化后)=32×10**9×4=128×10**9位
总字节数(量化后)=128×10**9/8=16×10**9字节=16GB
但是,通过实际加载模型可以看到,其占用的显存近22G。
量化过程中,每个参数组的权重需要存储额外的元数据(如缩放因子和零点),用于反量化计算。
例如,若采用分组量化(Group-wise Quantization),每64个参数为一组,每组需存储1个FP16缩放因子(2字节)和1个零点(1字节)。
对于32B参数(320亿个参数),分组数 = 32B / 64 = 5亿组 → 元数据总大小 = 5亿组 × (2+1)字节 ≈ 1.5GB
推理过程中,每层输出的中间结果(激活值)需暂存在显存中。
以32B模型为例,处理2048 tokens的序列时,激活值占用约3-5GB显存(具体与模型架构和序列长度强相关)。
硬件(如GPU)要求内存地址按特定字节对齐(如128位对齐),导致实际分配的显存可能略大于理论值。
某些框架会预分配缓存空间以加速计算(如KV Cache),进一步增加显存占用。
总之,对于ollama拉取的32B模型来说,24G显存是刚刚好。
我们以“DeepSeek-R1-Distill-Qwen-7B-Q8_0.gguf”部署为例:
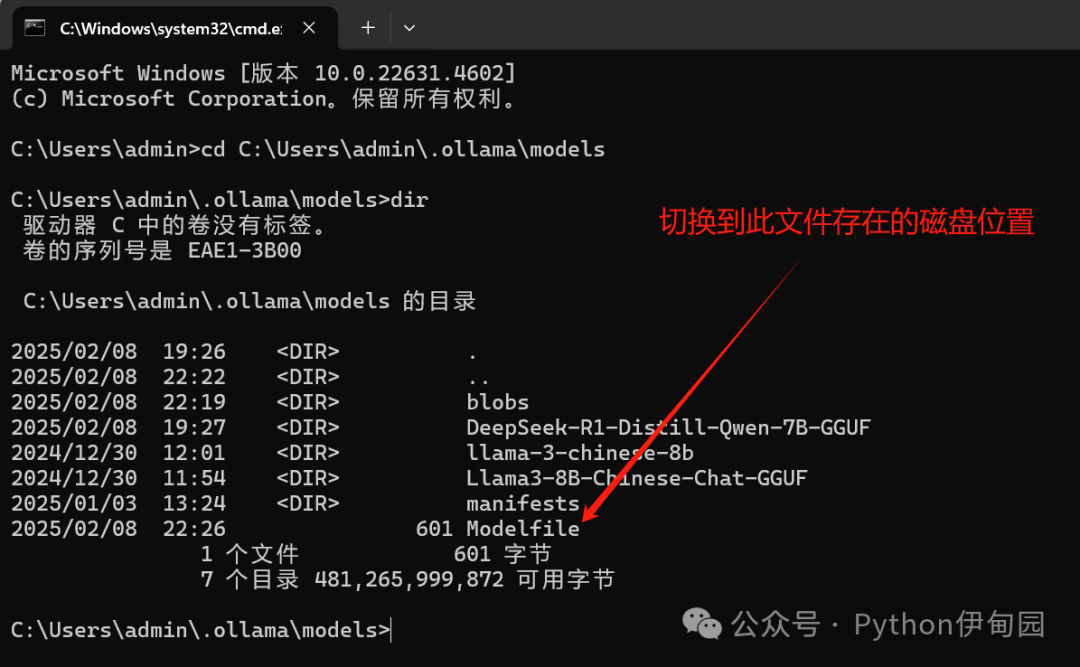
1、创建一个Modelfile文件,文件内容如下。
FROM C:/Users/admin/.ollama/models/DeepSeek-R1-Distill-Qwen-7B-GGUF/DeepSeek-R1-Distill-Qwen-7B-Q8_0.gguf
PARAMETER temperature 0.6SYSTEM """你是乐于助人的帮手,擅长中文多轮对话,回答需严谨且符合事实。>"""
其中FROM为量化的gguf模型,根据自己电脑上模型位置进行修改。
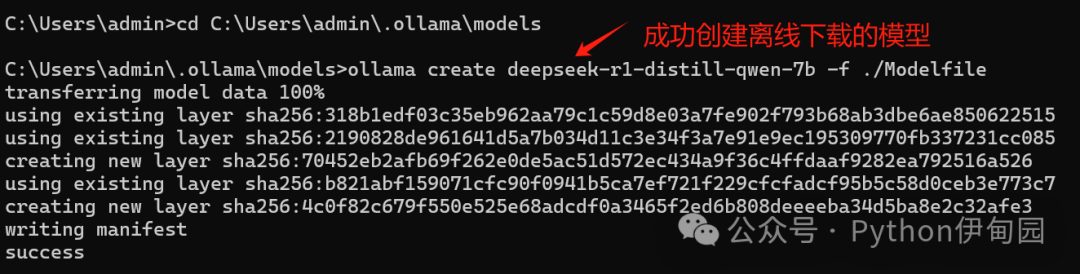
ollama create model-name -f Modelfile
其中model-name为自己命名,以下为命名示例:
ollama create deepseek-r1-distill-qwen-7b -f ./Modelfile