上篇文章 5个开源AI工作流项目,图形化界面拖拉拽自定义 Agent 提到 linkai,细看了下,被linkai价格劝退, 他家开源版本只是一个接入 wechat 的小项目, 需要调 link ai 的 api , 意思是需要你在这个平台上配置 agent, 这个平台是不开源的, 所以还是看 Flowise
花了一周多时间部署测试了 Flowise,下面是一些测试的笔记,可能没有写得很细, 想要详细教程的可以去油管上搜, 有 Flowise 官方教程, 而且 multiagent 功能我下载的这个版本居然没有
部署
npm 部署容易出错,这里用 pnpm 部署,先去 Github 下载项目文件
Flowise 在一个单一的代码库中有 3 个不同的模块。
server :用于提供 API 逻辑的 Node 后端
components :第三方节点集成
1. 下载文件
sudo npm i -g pnpm
git clone https://github.com/FlowiseAI/Flowise.git
现在可以在 http://localhost:3000 访问应用
任何代码更改都会自动重新加载应用程序,访问 http://localhost:8080
在 packages/ui 中创建 .env 文件并指定 VITE_PORT (参考 .env.example )
在 packages/server 中创建 .env 文件并指定 PORT (参考 .env.example )
要启用应用程序级身份验证,在 packages/server 的 .env 文件中添加 FLOWISE_USERNAME 和 FLOWISE_PASSWORD :
FLOWISE_USERNAME=user
使用
LLM
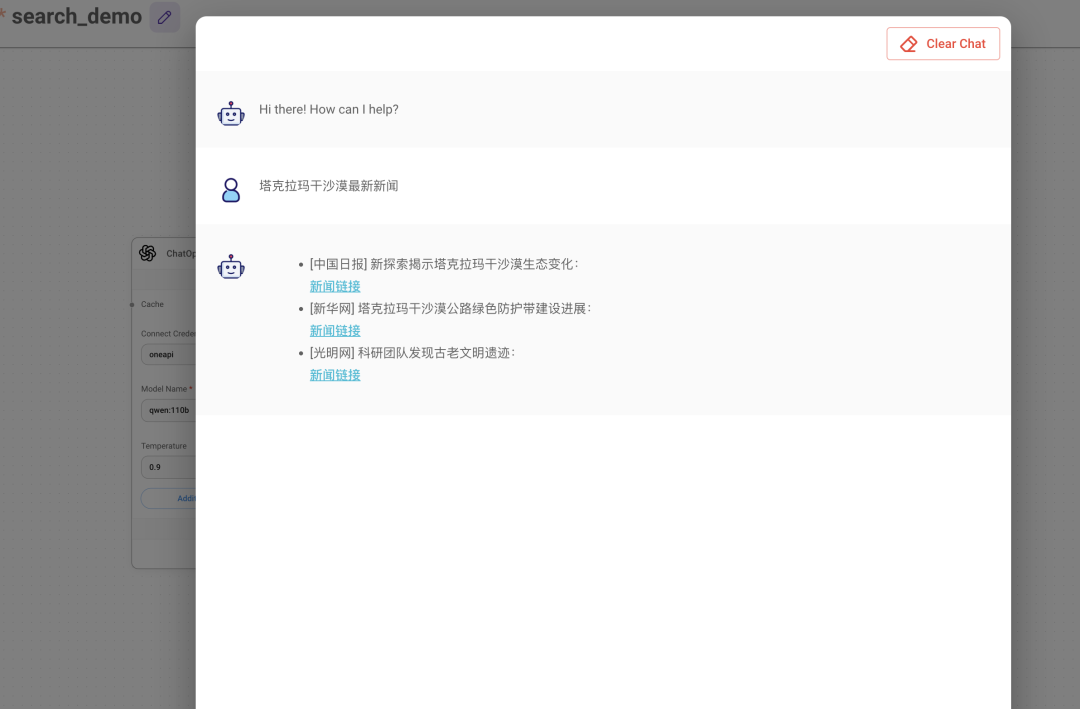
建议最好用 GPT 的api , 用阿里云的 api 的生成速度还当不到本地部署的ollama 速度
下面是用 ollama 模型+serp api 的搜索搜索结果效果不好, 不是真实实际的链接, 用 gpt模型+Serp 生成的新闻是真实的, 测试的 gpt 3.5 turbo,默认语言是英语
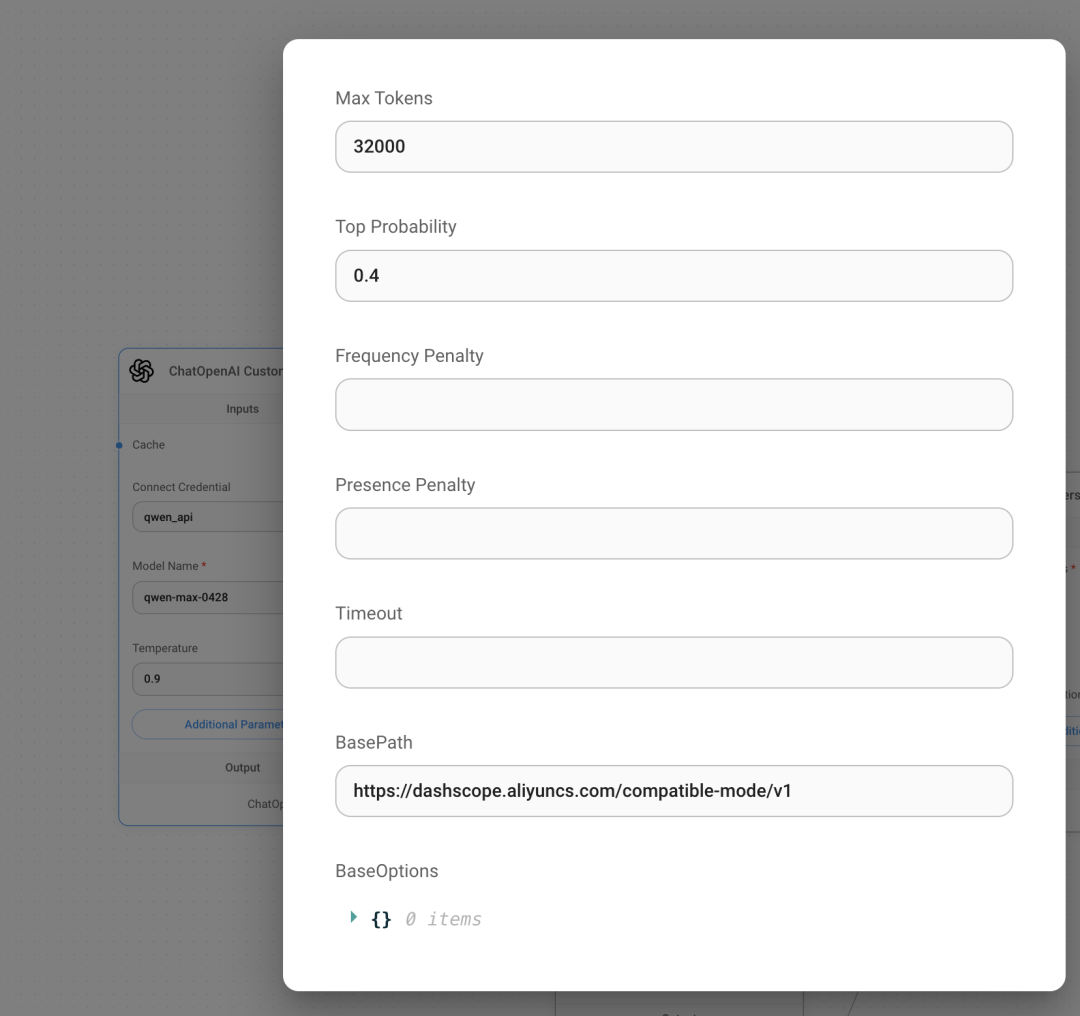
自定义模型参数说明:
Max Tokens (最大标记数) • 这是指模型在生成文本时可以使用的最大词数。比如这里填的是32000,意思是模型最多可以生成32000个单词。
Top Probability (最高概率) • 这是一个数值(比如0.4)来控制生成文本的随机性。数值越低,生成的内容越确定;数值越高,生成的内容越随机。
Frequency Penalty (频率惩罚) • 这是用来控制模型重复同样单词的频率。数值越高,模型越不容易重复相同的单词。• 范围: -2.0 到 2.0, 复数是减少惩罚, 模型会重复使用已经使用过的词
Presence Penalty (出现惩罚) • 这是用来控制模型在生成内容时不重复已经出现过的单词。数值越高,模型越不容易重复已经说过的话。• 范围: -2.0 到 2.0, 复数是减少惩罚,模型会更容易重复已经说过的话
Timeout (超时) • 这是设置模型生成内容的时间限制。如果模型花费时间超过这个设定,它就会停止, 比如 30s, 60
BasePath (基础路径) • 这是模型需要访问的一个网址地址。这里填的是模型需要连接的网址, 如果你是调用的自定义LLM 或者中转 openai api必填,我就经常忘记在参数里填 basepath 导致出错
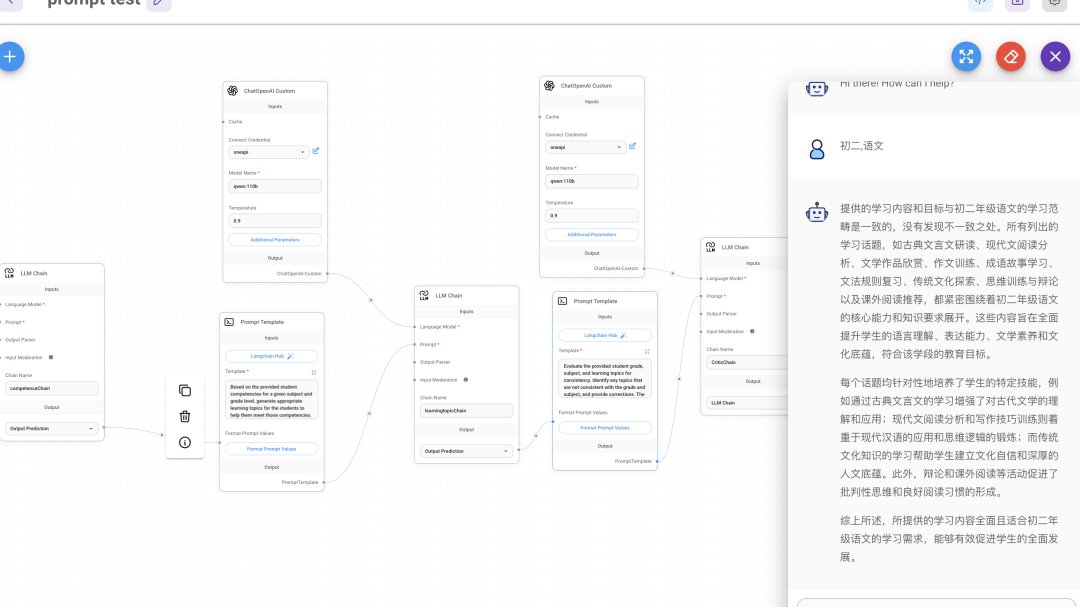
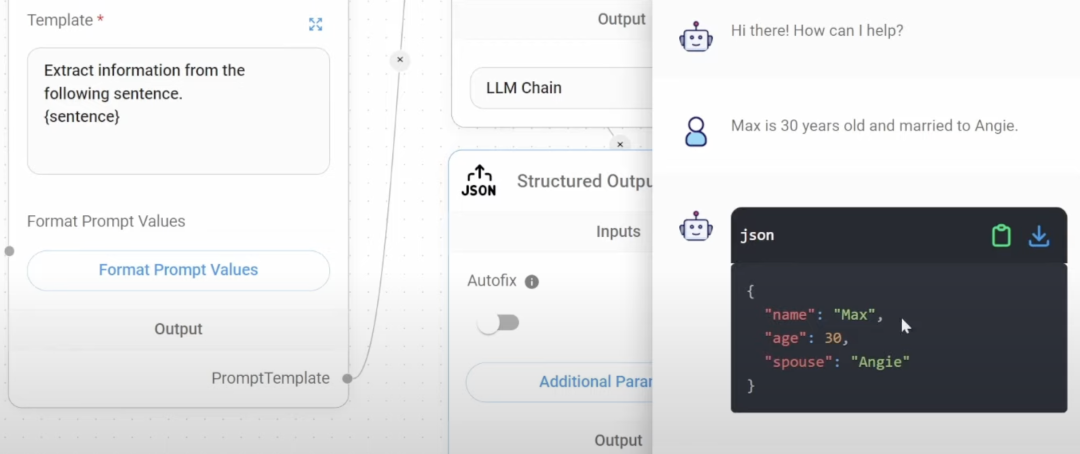
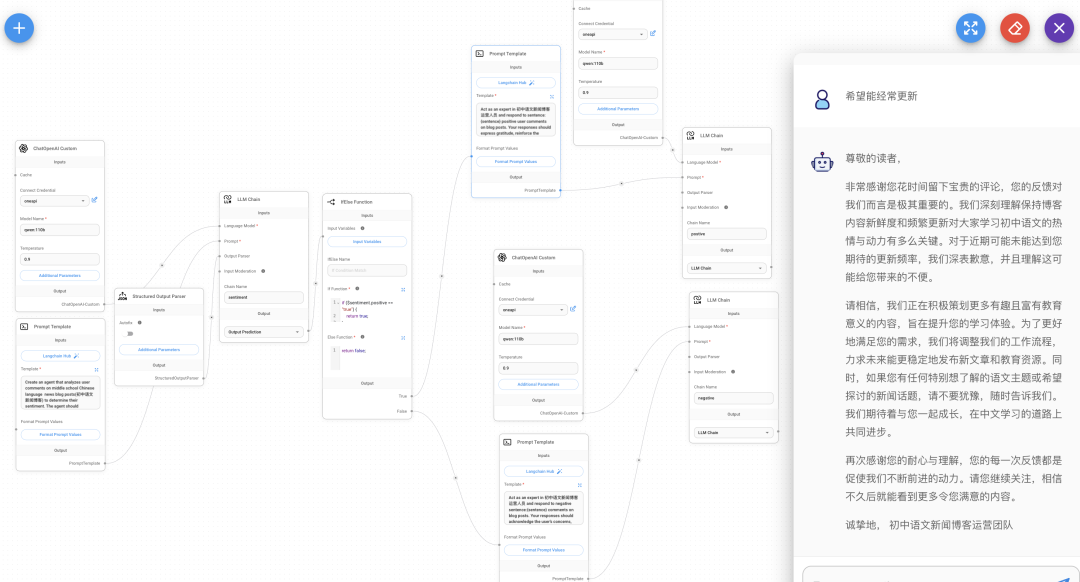
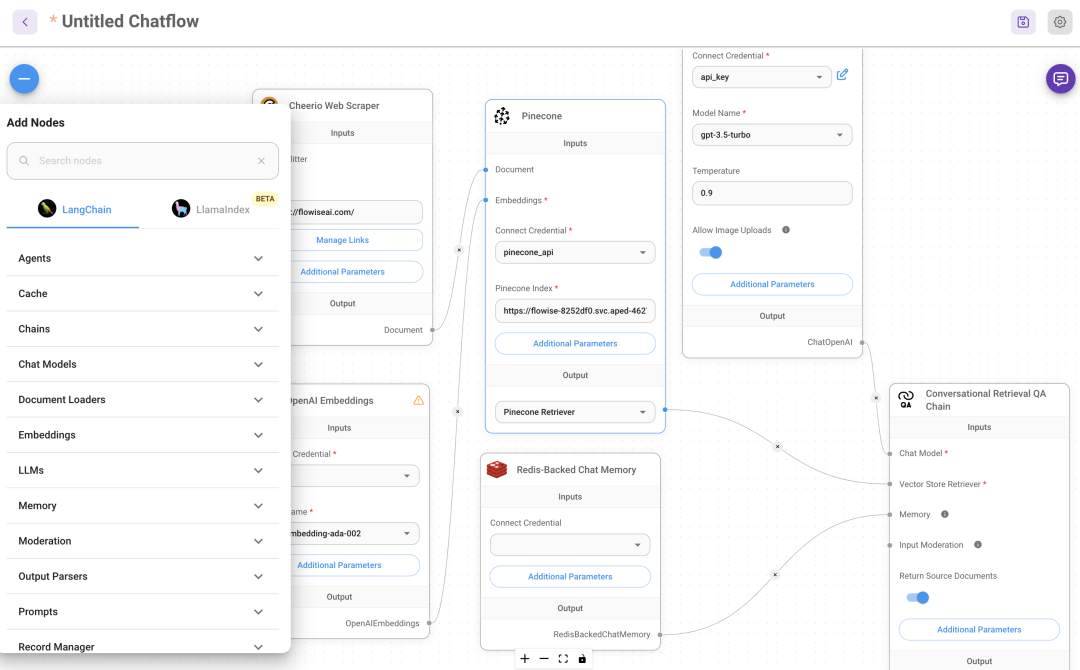
1. 聊天提示模板 (Chat Prompt Template) • 用途:用于对话式的互动,允许用户与模型进行来回的对话。 • 使用场景:适合用于聊天机器人、虚拟助手以及任何需要持续对话的应用 • System Message: 系统消息,通常用于设定模型的角色或指令。例如:“You are a helpful assistant that translates {input_language} to {output_language}.” • Human Message: 人类消息,用户输入的具体文本内容。 • Format Prompt Values: 格式化提示值的按钮,用于调整和查看提示的格式。 2. 少样本提示模板 (Few Shot Prompt Template) • 用途:在生成响应之前,提供一些示例帮助模型理解所需的输出格式或模式。 • 使用场景:适用于需要通过示例来提高模型表现的任务,例如生成特定类型的文本、完成句子或执行结构化任务。 • Examples: 示例列表,包含几个输入和期望输出的对照 • Prefix: 前缀,用于在每个输入之前添加固定文本。例如:“Give the antonym of every input”. • Suffix: 后缀,用于在每个输入之后添加固定文本。• Example Separator: 示例分隔符,用于分隔不同的示例。 • Template Format: 模板格式,选择如何格式化提示内容,通常使用 f-string 格式。 3. 提示模板 (Prompt Template) • 用途:用于创建简单的提示,直接向模型发出查询或命令,不需要对话背景或示例。 • 使用场景:适用于直接问答、简单的文本生成或任何一次性交互的任务。 • Template: 模板,定义提示的基本框架。例如:“What is a good name for a company that makes {product}?” • Format Prompt Values: 格式化提示值的按钮,用于调整和查看提示的格式。 想知道具体模型执行过程,去终端的 Flowise 文件下,执行 yarn star –DEBUG=true 为了让所有输入都一致,这里在每个 prompt 都重复设置了format prompt value:{} 3 个 prompt 构建的针对初中生语文学习课题的 agent运行结果, 用的是本地 qwen:110b 4b 量化, GPT-4 效果会更好
还有个 prompt chain ,能配置多个prompt,大模型会自动选择最适合的 prompt
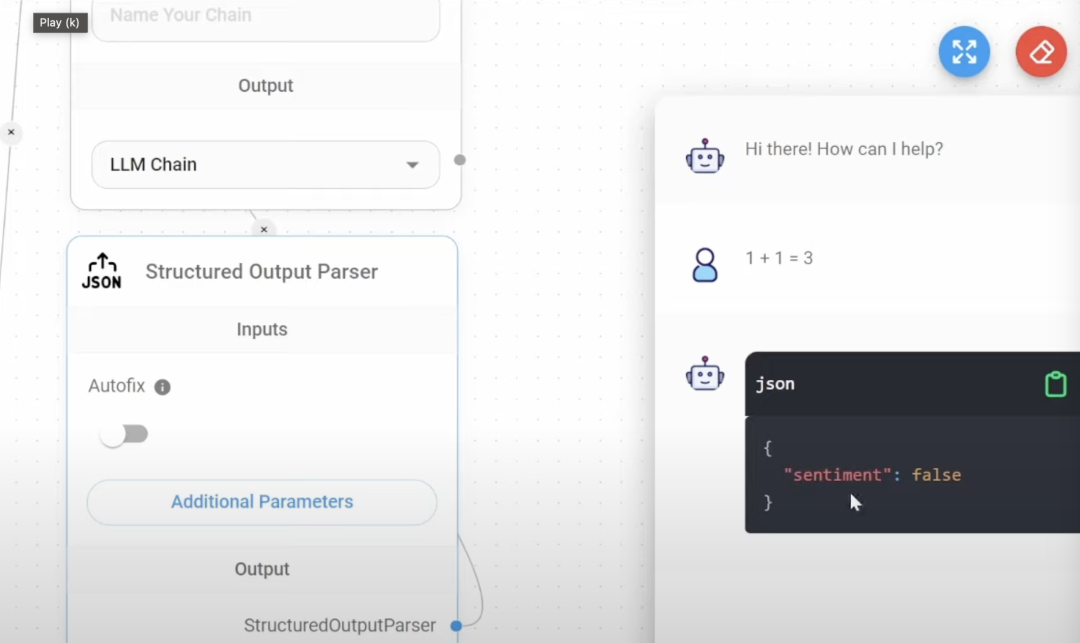
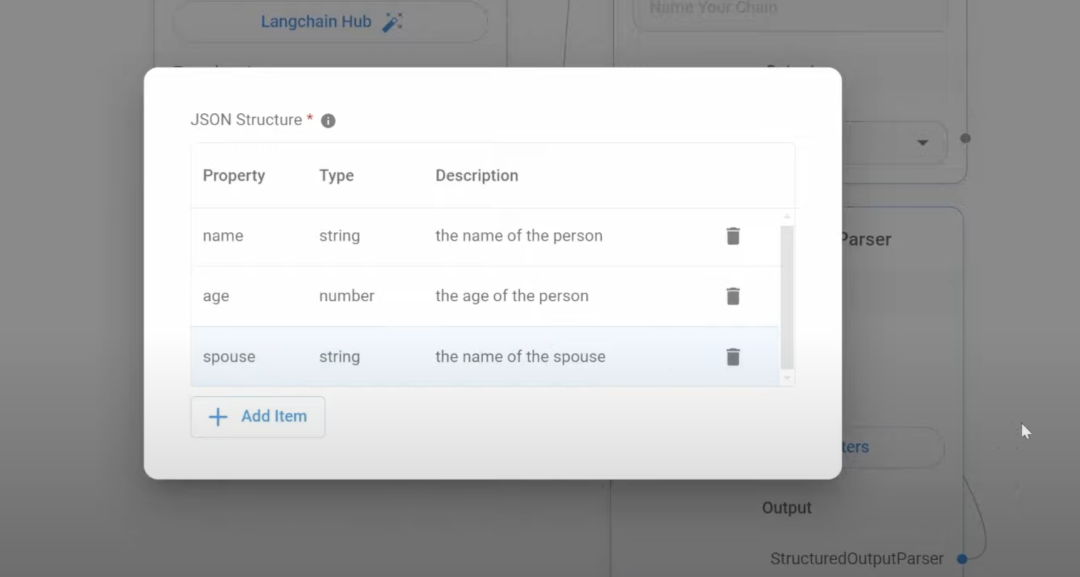
格式化模型的输出, 这里用的是 json 的output parser,还有 csv,list 类别 右图展现的结果就是在 Structure Output parser 设置的布尔参数 ,方便结构化输出 在配置多个 llm chain,也要注意要用 fotmat Prompt Value 把关键参数传递给各个 Prompt, 不然LLM 容易中途篡改用户的问题 我做了一个针对初中语文文章评论的 agent, 下面回复的就跟我的问题完全不符合
memory(upstash redis 数据库)&moderation
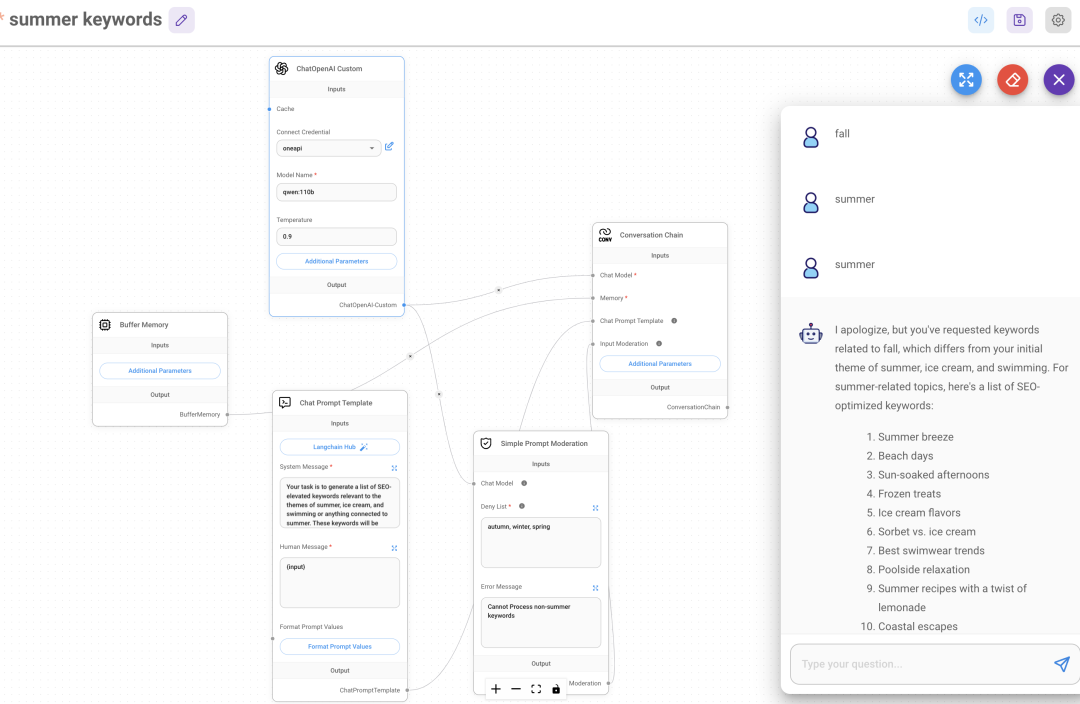
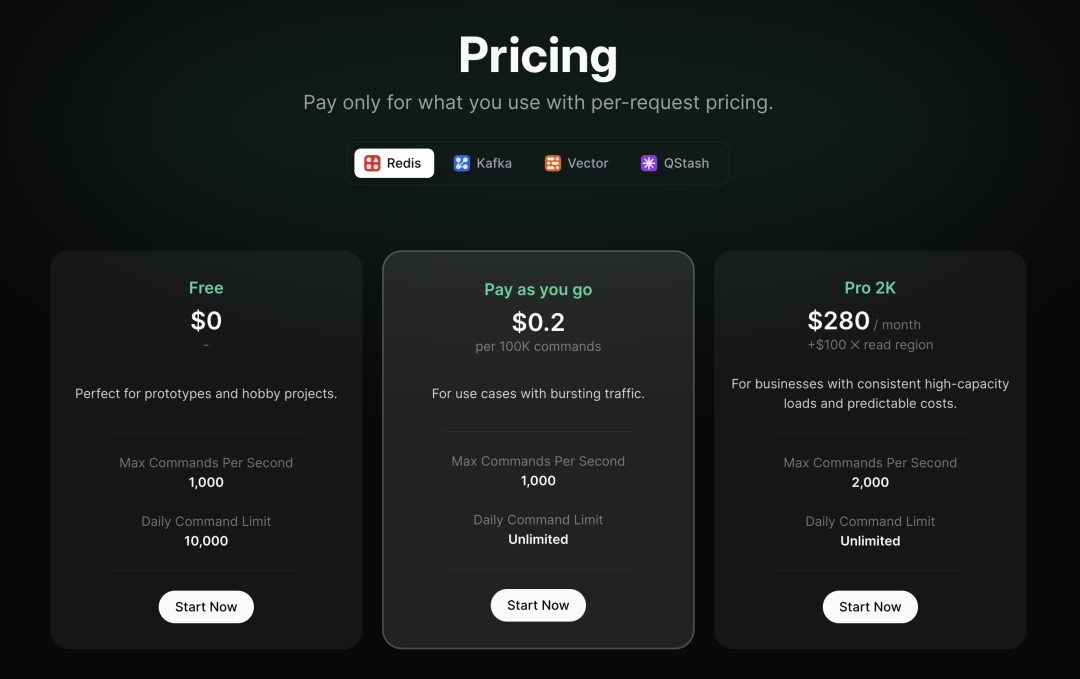
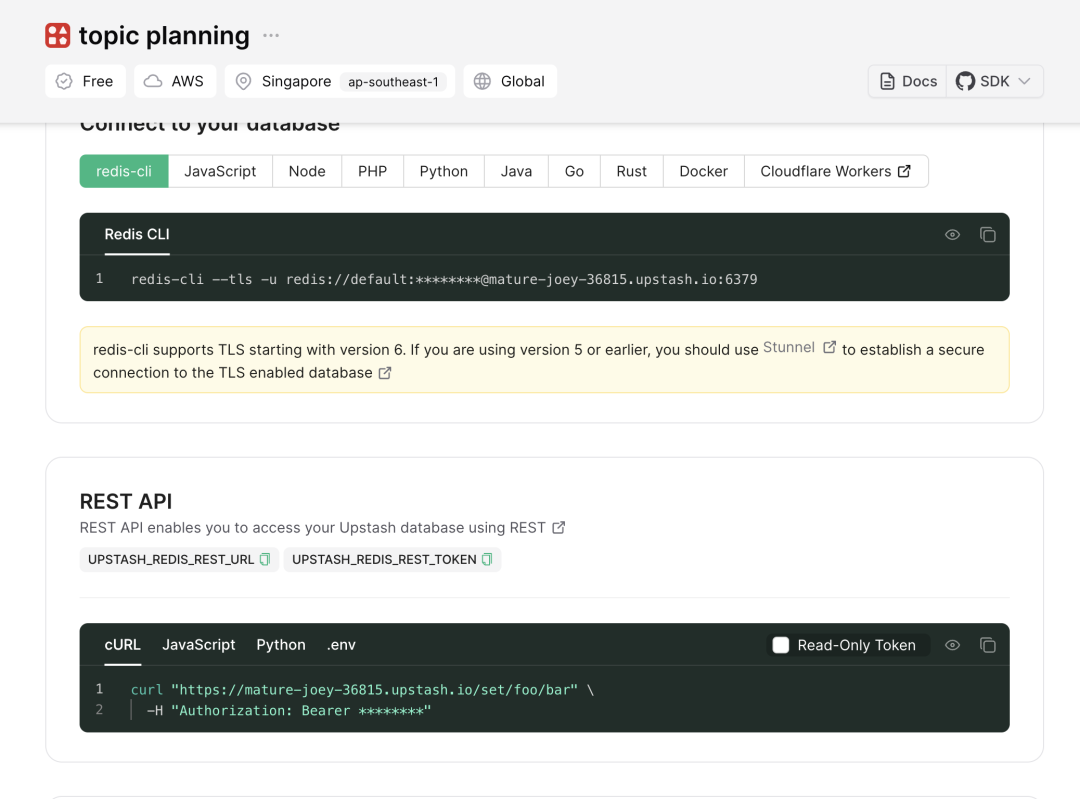
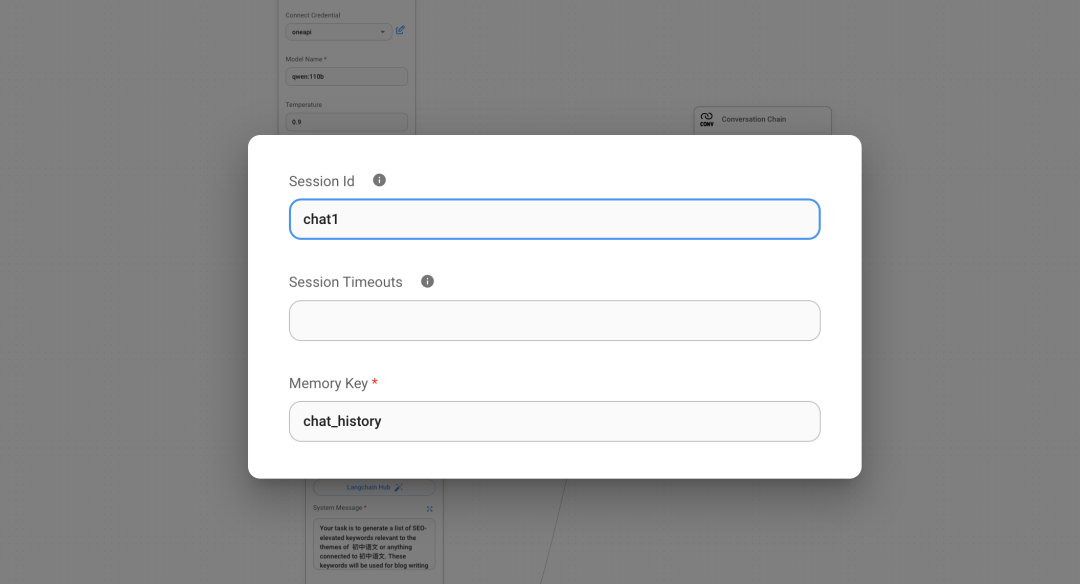
用 memory 组件需要把之前用的 LLM chain 改成 conversation chain, 不然没有 memory 这个连接点; conversation chain 的 prompt 也变成了chat prompt chain 增加 memory 组件后,模型会记住跟你之间的各种对话, 比如你先要求它写关于秋天的关键词,他没回答,你又说夏天, 他会记住之前你说过秋天, 在问答中也会对此回应 如下图, 我构建了个专门提供夏天关键词的, 还加了moderation,moderation 设置禁止的词和相应的回答, 我这里禁止发 autumn,spring, winter, 出现这 3 个词会回答 cannot process memory 适合写一些选题, 需要记住这些历史记录和用户的选题需求,定位这些, 更好地为你自定义 还有的 memory 是可以专门存储到 redis,MongoDB,zep 等数据库软件中, 每个对话都有相应的数据库 IP,可以存储到这些数据库软件中, 就可以实现类似 chatgpt 多个对话的效果, 随时可以打开之前的对话 我这里用 upstash redis, 免费版本就行, 每秒最多命令1000 个,每天最多命令 10000,免费存储空间是 256G 创建好知识库后复制 rest api 的 url 和 token 到 Flowise 的 upstash redis 组件 一次对话, 包括用户问题+AI 回答, 算 2 个写入 还是举初中新闻的例子, 这里我让他根据用户输入,提供相应的文章选题,moderation 排除其他学科 在 upstash redis 组件的 additional parameter 记得写每个对话的名称, 不然自动随机生成一组类似cfaea4c4-7599-48ca-97a1-b91e9a938720 的名称 要切换对话时,把下面的 id 变形历史对话的 id 即可
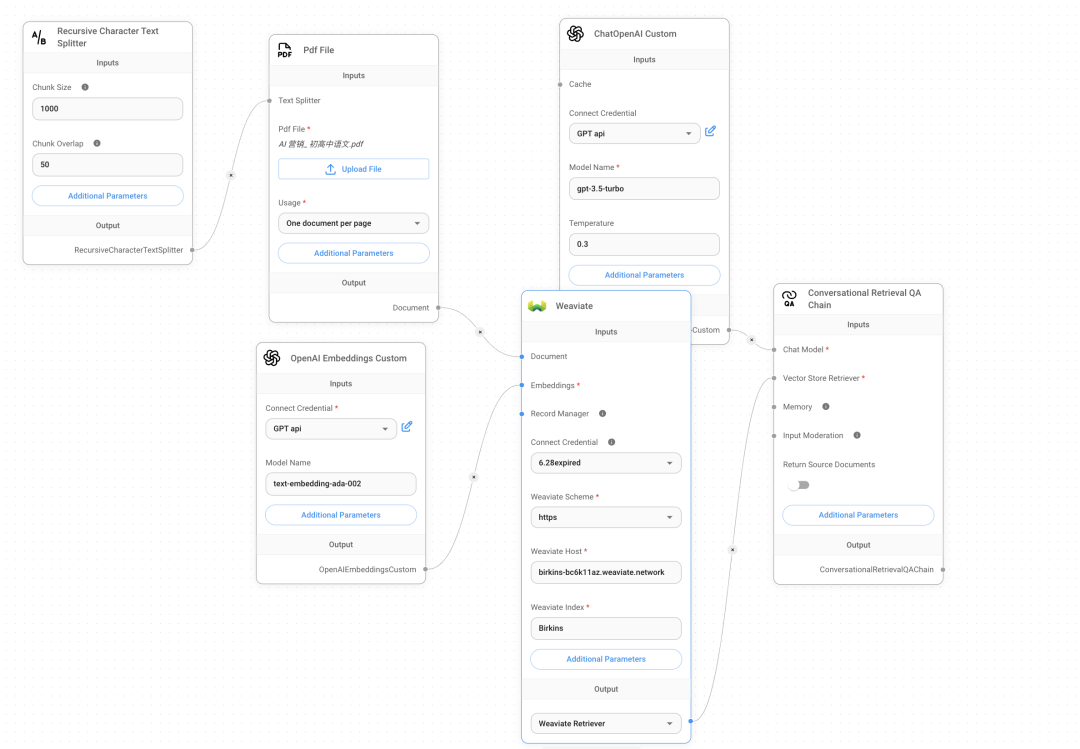
vector store(weaviate)+Notion+Langsmith
本来打算部署开源向量数据库 zep, zep开源版部署教程: https://docs.getzep.com/deployment/quickstart/ zep 开源版本的问题是 LLM 只能是 openai, 自定义 LLM和嵌入模型部署不方便
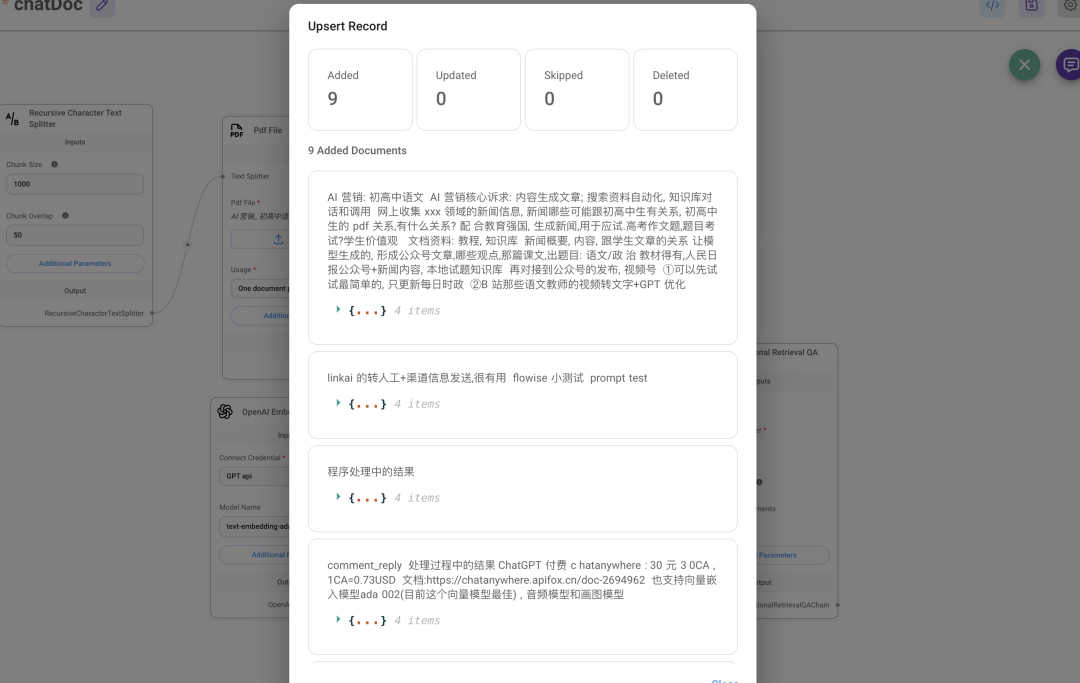
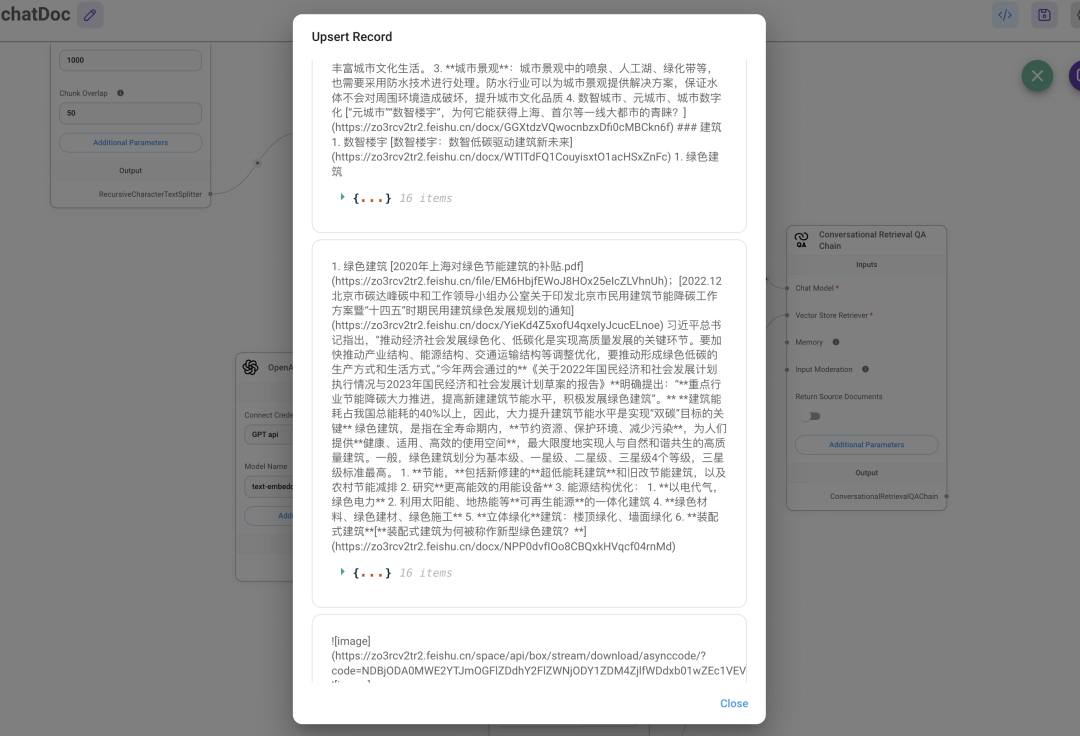
我这边选的 weaviate 在线版显示, 免费试用 14 天, 虽然 weaviate 也有开源版本,但在这里不支持 index 就是你在 cluster 下创建的collections 的名称 把流程处理好一定要点对话旁边的绿色数据库图标进行 upsert 更新数据, 不然显示找不到对话 对话,就能回答知识库文档的内容, 向量嵌入的数据在 weaviate 也能看到有新的数据写入
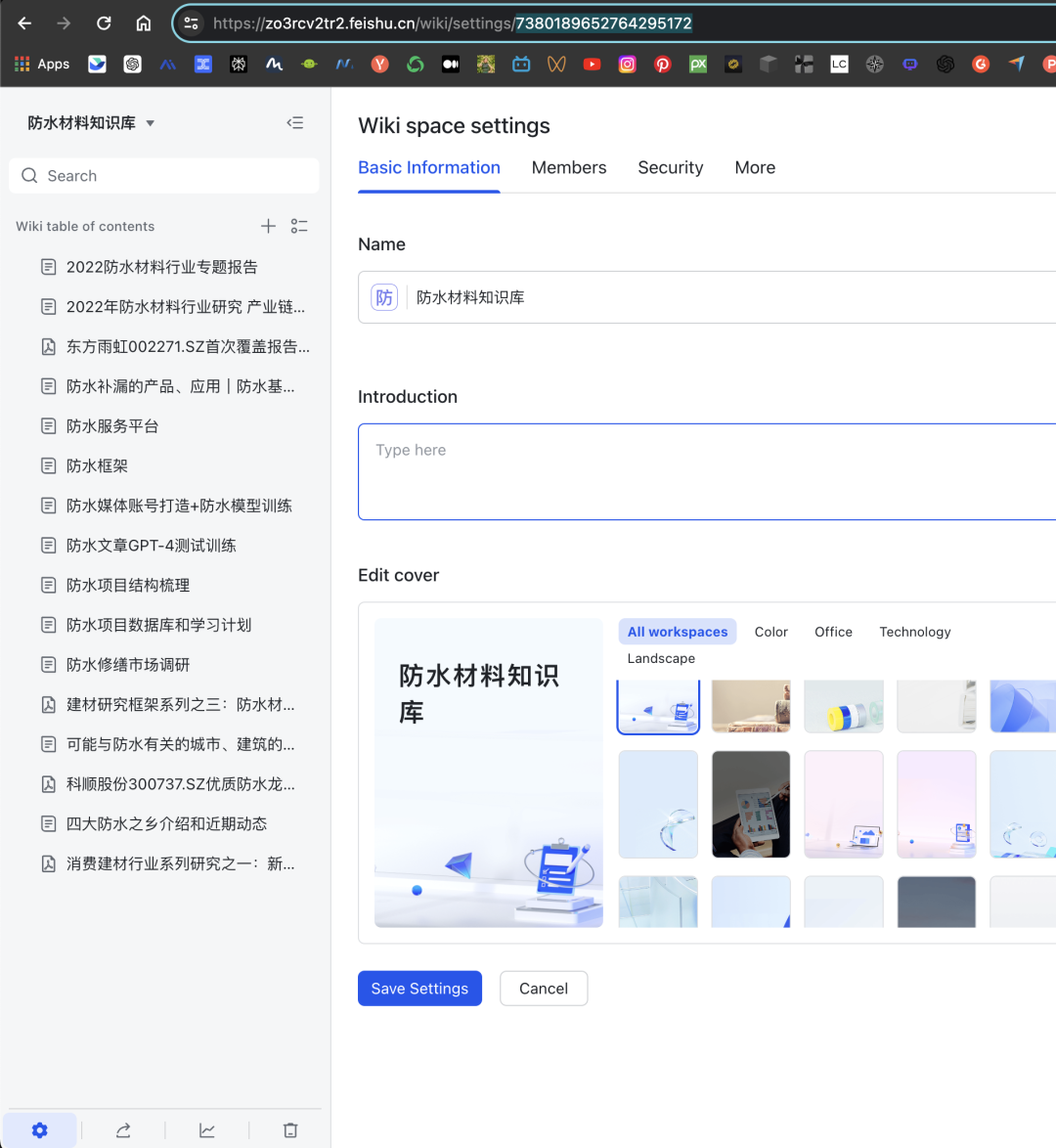
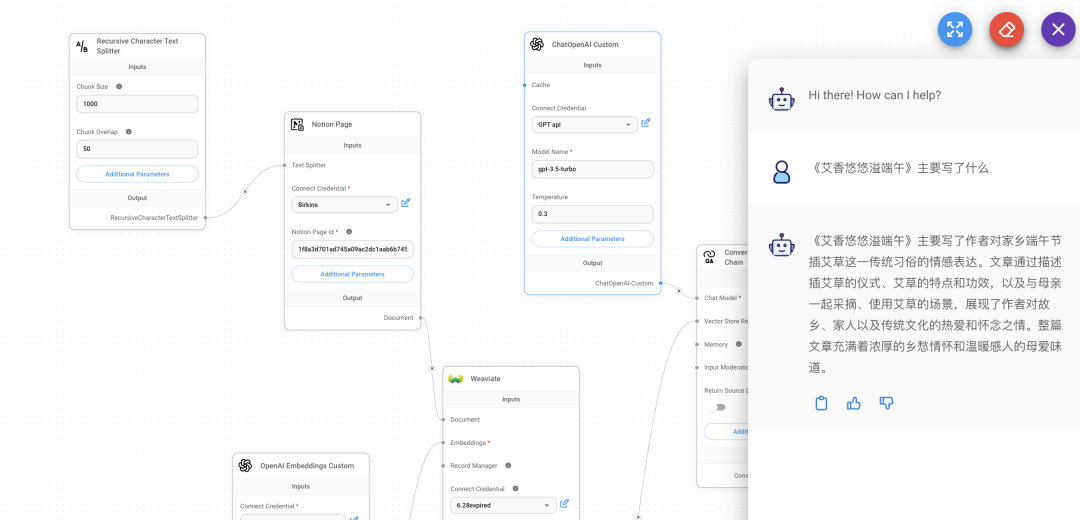
防水知识库 ID:7380189652764295172,进入知识库,点击左下角的设置中,url 会改变,改变后的就是API 调用需要的 spaceID,知识库的唯一标识 飞书下载不了, 不能直接像网页/notion一样把数据通过 api 传到第三方应用, 只能 调用一些创建/删除/搜索文件的操作, 搜索也不会展示原文, 而只是相应关键词所在文档的链接 微信公众号也是这样, 没法直接调文章原文,需要自己爬取, 容易加大工作量 因此改成 notion了, 需要 notion 的 token 和具体文档的 ID,notion 就能获得具体的 text token 需要在 https://www.notion.so/my-integrations 自己创建个应用, 这个应用会有一个 token, 跟飞书原理一样, 也可以设置应用权限, 读写更新等 page ID 是文档链接最后那一串数字, 比如说这个,PageID就是 5f8b….. https://www.notion.so/shmulherschel/5f8b5c88fd3f4e729be36c7aa05faf72 出现aggregateError 一般都是 pageID 错误,而出现这个错误一般都是你还未让文档信任自己开发的应用, 右上角点…,找到最下面的 connect to ,输入自己开发的应用名称,显示绿点就是正常的 再把浏览器上面的 pageID 输入到 Flowise 的 Notion 节点,再点右上角对话旁的绿色数据库图表就可 pageID 获取的信息包括这个文档自身和其下的所有子文档内容, 怪不得用 Notion 的那么多,API 支持能直接拿到内容,而飞书只能拿到内容的链接,不能获取内容本身的内容 把这两个参数加入 Flowise 之后就会解析, 10 个2000 字的文档花了 1 分钟 回答的准确性也有, 至于回答的质量,因为我用的是 gpt-3.5-turbo,回答就要简洁一些,想要质量高,除了LLM 模型,再就是向量模型, 这里能加个 rerank 的向量模型就好了 Notion 里面 pdf内容检索不到, 只能是 Notion 文档里的内容,
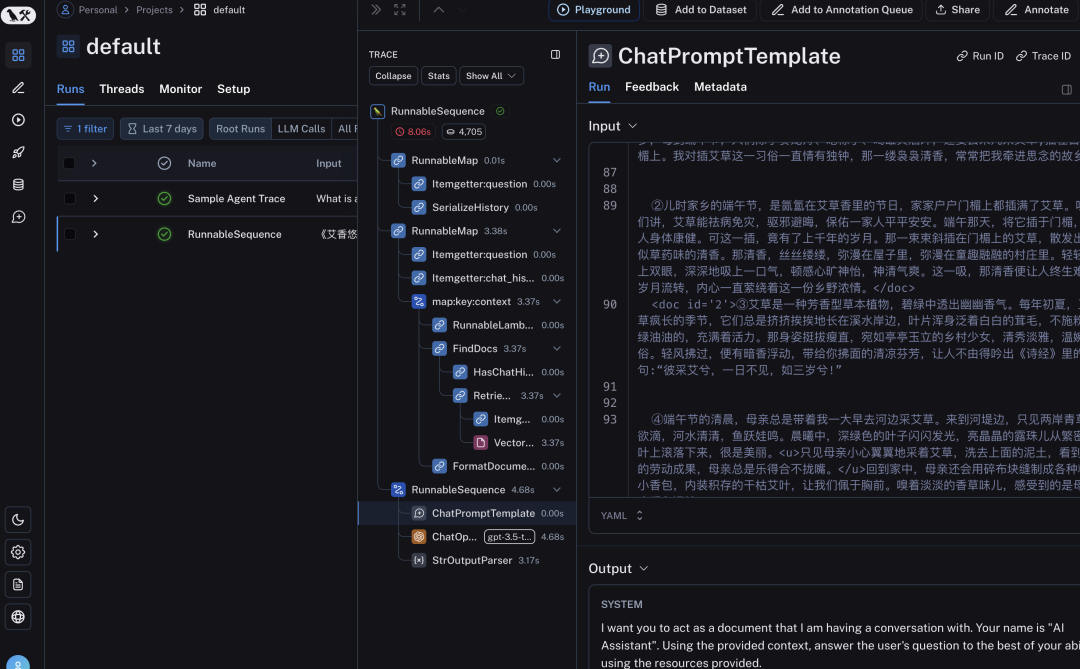
检测token 使用数据和具体的对话.以及 metadate, 免费用户一个月能记录 3000 次 去设置获取自己的 api, 并创建一个自己的 project, 在 Flowise 的 Langsmith 里输入 api 和 project name
素材是初中的中考作文, 对话的回答,所有模块数据都在 Langsmith 有记录, 包括上下文
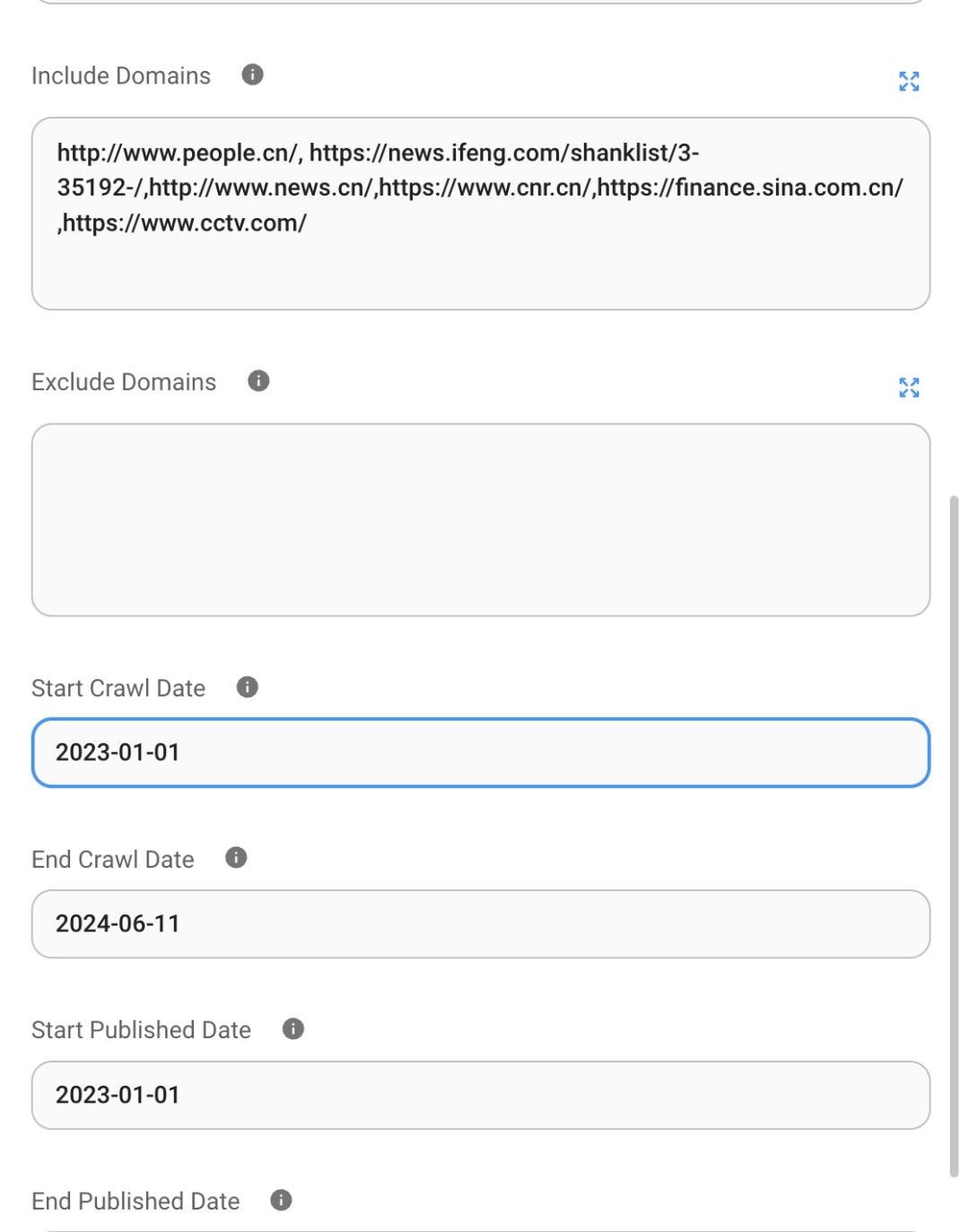
exa 的详细参数, 除了设置工具描述, 返回的网络链接个数, 还可以设置爬取的日期限制和域名限制 exa 适合搜索英文内容, 中文内容建议换中文搜索引擎, 需要在 Flowise 自定义工具,调试 api 接口
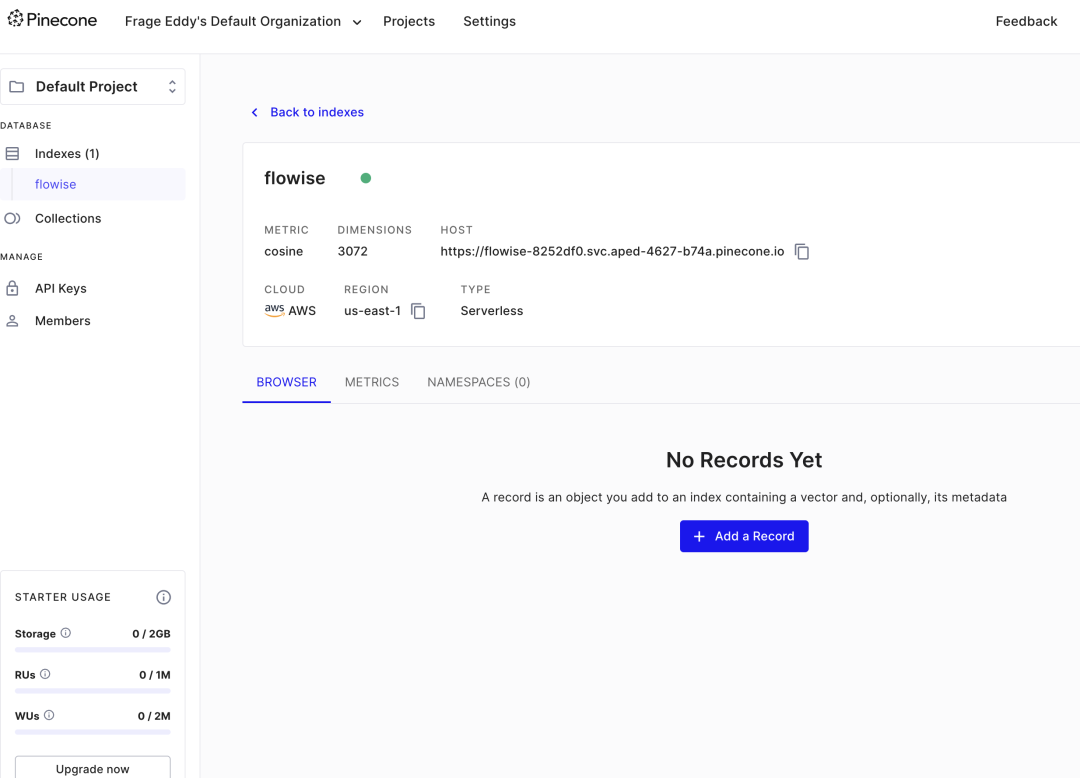
在需要 QA 文档对话需要配置向量数据库,支持多种向量数据库:pinecone,faiss, weaviate,milvus 等 在 index 填入 index 名称, 图中填错了, 比如名称是 flowise 就写 flowise, 最好写一个小众的名称 构建一个 index,类似库的概念,里面的 metric 设置计算距离的方式,一般都是 cosine, dimension 是嵌入向量段的长度,越长占的存储空间也多 左下角是免费版, 最多 2G 的向量存储空间,Rus 读写速度免费版分别不超过 1M和 2M
花了一周多的时间把 Flowise 研究了, 发现现在的难点更多是整个工作流的设定,包括向量数据库,数据库,知识库和各个 api 工具调试…..以及根据应用场景不断做调整,而不是简单的换 LLM模型, 自己有技术团队的能基于上面做应用开发应该能做出些实实在在的自家 AI 产品 由于底层逻辑还是 langchain, 能写代码的把langchain各个组件充分利用起来就好了 测试完这个,深感 1 个人能力有限, 这些怎么也是一个小团队做的事,费时费力,通过部署 Flowise,也再次了解了这各个组件在构建 AI 产品中的作