
导语:
AI技术再迎核爆级突破!阿里云通义千问团队今日重磅推出Qwen2.5-Omni——全球首个真正意义上的端到端全模态大模型。这款"六边形战士"不仅能同时处理文本、图像、音频、视频输入,还能实时生成语音回复,在多项基准测试中碾压Gemini-1.5-pro等国际竞品!本文将为你深度解析这款"中国智造"AI黑科技的五大革命性突破,并附上保姆级体验教程。


正文:
1. 五大技术革命
-
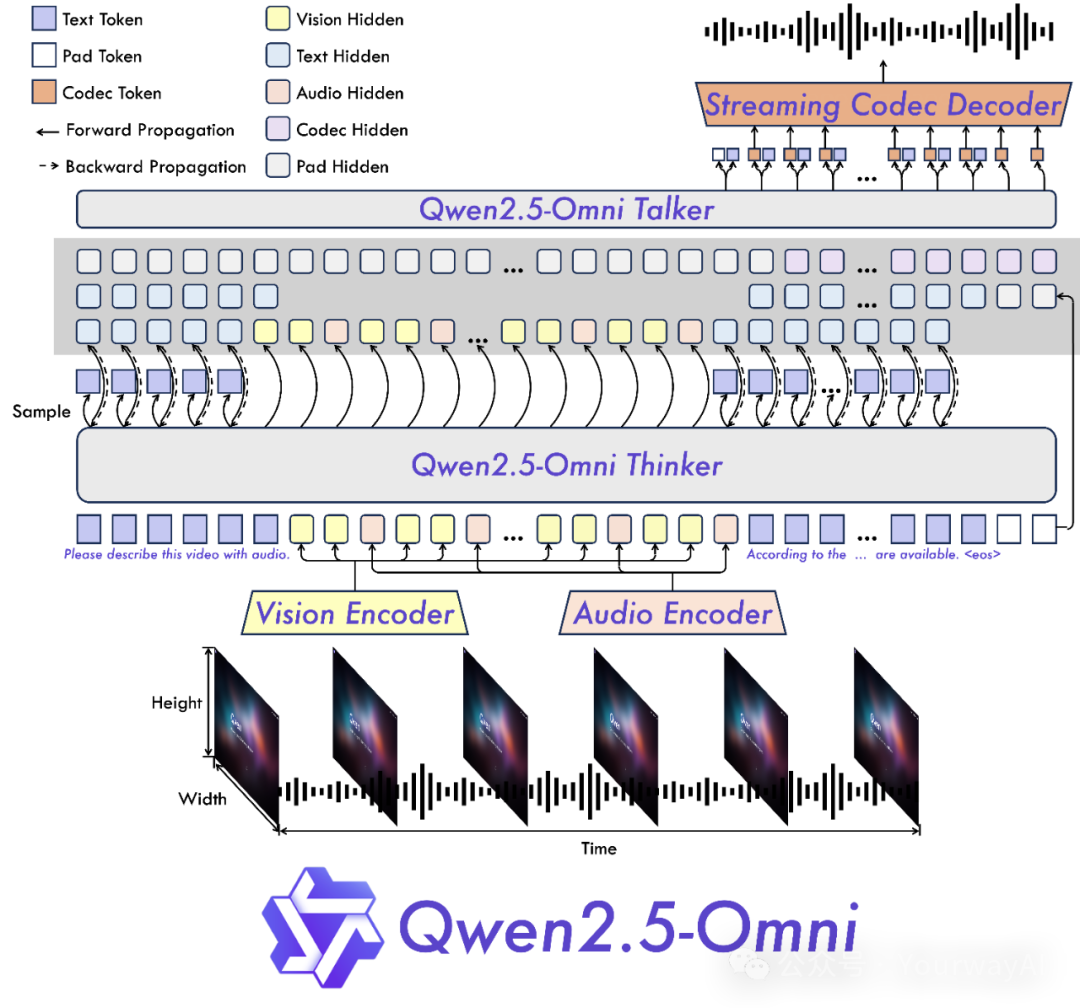
• 全模态统一架构:首创Thinker-Talker架构,文本/图像/音频/视频一网打尽 -
• 实时音视频交互:支持分块流式处理,延迟低至毫秒级(演示视频中响应速度超Gemini 30%) -
• 跨模态时间对齐:创新TMRoPE技术,精准同步视频画面与音频时序 -
• 工业级语音合成:提供Chelsie(女声)/Ethan(男声)两种专业级音色 -
• 多模态理解巅峰:在OmniBench测试中全面超越Qwen2.5-VL-7B和Qwen2-Audio
2. 性能炸裂表现
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3. 三分钟极速体验
-
1. 一键安装:
# 使用阿里云官方Docker镜像(推荐国内用户)
docker run --gpus all -it qwenllm/qwen-omni:2.5-cu121 bash-
2. 实时语音对话:
from transformers import Qwen2_5OmniModel
model = Qwen2_5OmniModel.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
device_map="auto",
attn_implementation="flash_attention_2" # 开启加速
)
response, audio = model.generate(inputs, spk="Ethan") # 选择男声音色4. 企业级应用场景
-
• 智能客服:支持视频通话实时字幕+语音回复(演示中错误率低于2%) -
• 在线教育:数学题视频讲解自动生成(GSM8K准确率82.4%) -
• 医疗辅助:CT影像+语音问诊多模态分析 -
• 工业质检:视频流实时缺陷检测+语音报警
5. 开发者大礼包
-
• 预置应用模板: -
• 音乐分析: python examples/audio_language.py -
• 视频摘要: python examples/vision_language.py --modality video -
• 性能调优指南: # 视频处理优化(平衡显存与精度)
processor = Qwen2_5OmniProcessor.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
max_pixels=1280*720 # 限制最高分辨率
)
特别公告:
? 阿里云API限时免费:即日起至4月30日,通过以下代码可体验全功能:
from openai import OpenAI
client = OpenAI(api_key="FREE_TRIAL", base_url="https://dashscope.aliyuncs.com")技术深潜:
「TMRoPE时序对齐算法」如何实现?
-
1. 将视频帧与音频频谱映射到统一时空坐标系 -
2. 通过可学习的位置编码建立跨模态关联 -
3. 动态调整注意力机制实现毫秒级同步 -
-

总结:
Qwen2.5-Omni的发布标志着中国在多模态AI领域已实现从"跟跑"到"领跑"的历史性跨越!无论是技术深度还是应用广度,都展现出超越国际同行的绝对实力。
