


"WeKnow-RAG: An Adaptive Approach for Retrieval-Augmented Generation Integrating Web Search and Knowledge Graphs"的论文提出了一种新颖的检索增强生成(RAG)方法,结合了网络搜索和知识图谱。
WeKnow-RAG:结合网络搜索和知识图谱的自适应检索增强生成方法
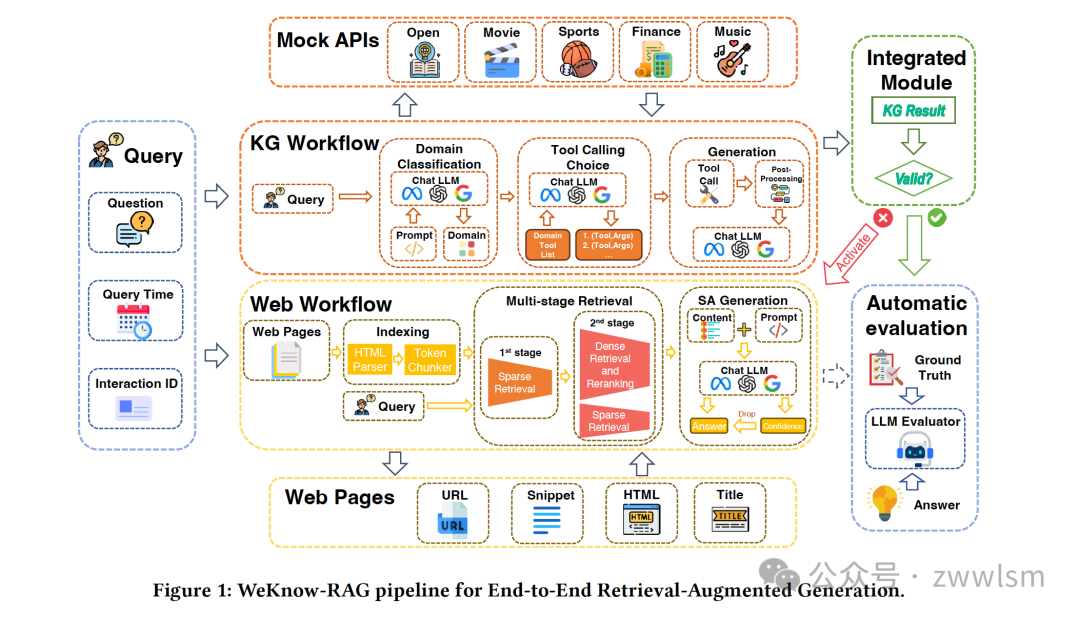
1. 引言
大型语言模型(LLMs)在近年来取得了巨大的进展,展现出了成为通用人工智能(AGI)重要途径的潜力。然而,LLMs也面临着一些挑战,最突出的是它们容易产生事实不正确的信息,甚至生成"幻觉"内容,这严重影响了它们在实际场景中的可靠性。
为了解决这些问题,研究人员提出了检索增强生成(RAG)方法。RAG通过结合外部数据库和信息检索机制来增强LLMs的能力。本文提出的WeKnow-RAG方法更进一步,将网络搜索和知识图谱整合到RAG系统中,旨在提高LLM响应的准确性和可靠性。
2. WeKnow-RAG方法概述
WeKnow-RAG的核心思想是结合知识图谱的结构化表示和密集向量检索的灵活性。该方法主要包含以下几个关键组件:
-
基于网络的RAG -
基于知识图谱的RAG -
集成方法
让我们逐一深入了解这些组件。
2.1 基于网络的RAG
基于网络的RAG是WeKnow-RAG的重要组成部分,它包括以下几个步骤:
2.1.1 网页内容解析
首先,我们需要对网页内容进行解析,以便后续处理。这里使用了BeautifulSoup库来解析HTML源代码:
from bs4 import BeautifulSoup
def parse_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
# 提取需要的内容
text = soup.get_text()
return text
2.1.2 分块
分块是将文档分割成多个段落的过程。WeKnow-RAG采用了基于token的分块方法。以下是一个简单的分块示例:
def chunk_text(text, chunk_size=500):
tokens = text.split()
chunks = []
for i in range(0, len(tokens), chunk_size):
chunk = ' '.join(tokens[i:i+chunk_size])
chunks.append(chunk)
return chunks
2.1.3 多阶段检索
WeKnow-RAG采用了多阶段检索方法,包括稀疏检索和密集检索:
-
第一阶段:使用BM25算法进行稀疏检索 -
第二阶段:结合稀疏检索(BM25)和密集检索(embedding similarity)
BM25算法的评分函数如下:
Score(query, C_i) = ∑(q_j ∈ query) IDF(q_j) · (f(q_j, C_i) · (k_1 + 1)) / (f(q_j, C_i) + k_1 · (1 - b + b · |C_i| / avg_dl))
其中:
-
q_j 是查询中的一个词 -
IDF(q_j) 是词 q_j 的逆文档频率 -
f(q_j, C_i) 是词 q_j 在文档 C_i 中的词频 -
k_1 和 b 是参数(通常 k_1 = 1.5, b = 0.75) -
|C_i| 是文档 C_i 的长度 -
avg_dl 是语料库中的平均文档长度
2.1.4 答案生成与自评估
为了减少幻觉,WeKnow-RAG引入了一个自评估机制。LLM会对生成的答案进行置信度评估:
def generate_answer_with_confidence(query, context):
prompt = f"""
Question: {query}
Context: {context}
Answer the question and provide your confidence level (high, medium, low).
"""
response = llm.generate(prompt)
# 解析响应,提取答案和置信度
return answer, confidence
2.2 基于知识图谱的RAG
知识图谱(KG)在WeKnow-RAG中扮演着重要角色,主要包括以下步骤:
2.2.1 领域分类
首先,系统会对问题进行领域分类:
def classify_domain(query):
prompt = f"Classify the domain of this query: {query}"
domain = llm.generate(prompt)
return domain
2.2.2 查询生成
根据领域分类结果,系统会生成相应的知识图谱查询:
def generate_kg_query(query, domain):
if domain == "music":
prompt = f"""
Generate a KG query for this music-related question: {query}
Available functions:
- get_artist_info(artist_name, info_type)
- get_song_info(song_name, info_type)
...
"""
# 其他领域的处理逻辑
kg_query = llm.generate(prompt)
return kg_query
2.2.3 答案检索与后处理
系统通过API调用知识图谱获取候选答案,然后进行后处理:
def retrieve_and_postprocess(kg_query):
raw_result = kg_api.call(kg_query)
processed_result = postprocess(raw_result)
return processed_result
2.3 集成方法
WeKnow-RAG采用了一种自适应框架,根据不同领域的特点和信息变化速度,智能地结合基于KG的RAG方法和基于Web的RAG方法:
def adaptive_rag(query):
domain = classify_domain(query)
if domain in ["encyclopedia", "open_domain"]:
return kg_based_rag(query)
elif domain in ["music", "movies"]:
kg_result = kg_based_rag(query)
web_result = web_based_rag(query)
return integrate_results(kg_result, web_result)
else:
return web_based_rag(query)
3. 实验结果
WeKnow-RAG在CRAG(Comprehensive RAG Benchmark)数据集上进行了评估。以下是一些关键的实验结果:
| 模型版本 | 准确率 | 幻觉率 | 缺失率 | 得分 |
|---|---|---|---|---|
| 版本1 | 0.393 | 0.319 | 0.288 | 0.0743 |
| 版本2 | 0.409 | 0.316 | 0.276 | 0.0929 |
从表格中我们可以看到,WeKnow-RAG的版本2相比版本1有了显著的提升,特别是在准确率和得分方面。
4. 结论与未来展望
WeKnow-RAG通过结合网络搜索和知识图谱,提出了一种新颖的检索增强生成方法。该方法在提高LLM响应的准确性和可靠性方面取得了显著成效。主要贡献包括:
-
开发了一个适应不同查询类型和领域的特定领域KG增强RAG系统 -
引入了结合稀疏检索和密集检索的多阶段网页检索方法 -
实现了LLM的自评估机制,减少了幻觉现象 -
提出了一个自适应框架,智能地结合基于KG和基于Web的RAG方法
未来的研究方向可能包括:
-
进一步优化知识图谱的构建和更新策略 -
探索更高效的多模态检索方法 -
研究如何将WeKnow-RAG应用于更广泛的领域和任务
