

HybridRAG: 融合知识图谱和向量检索的新型信息提取方法
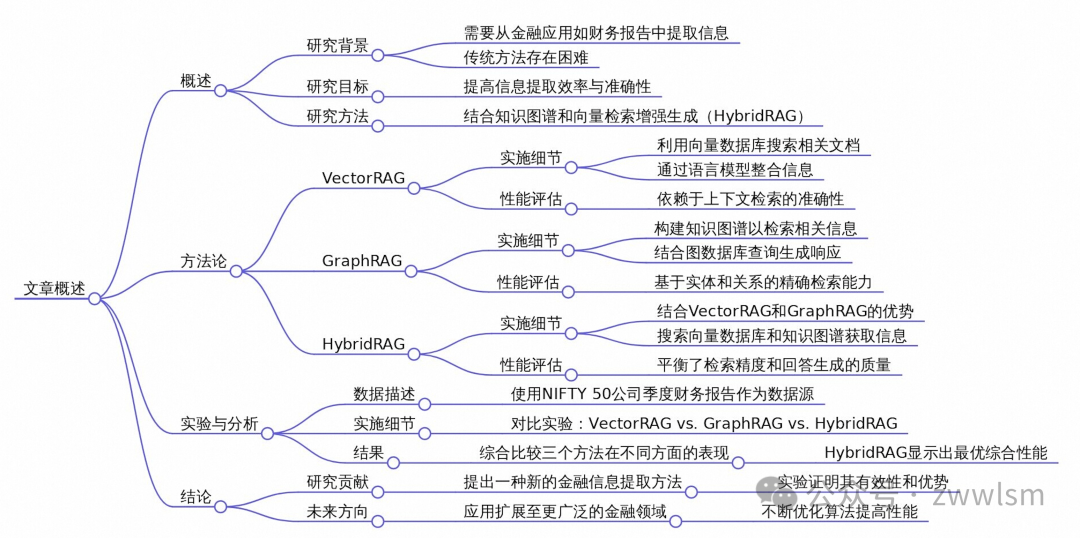
今天我要为大家分享一篇非常有趣的论文,题目是《HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction》。这篇论文提出了一种新颖的方法,将知识图谱和向量检索相结合,来提高大语言模型在金融领域的信息提取能力。
1. 研究背景
在当今的金融世界中,快速准确地从大量非结构化文本(如新闻文章、财报等)中提取有价值的信息变得越来越重要。然而,传统的信息提取方法在处理金融领域特有的专业术语和复杂文档格式时往往力不从心。
为了解决这个问题,研究人员提出了一种名为检索增强生成(Retrieval Augmented Generation, RAG)的技术。RAG通过在外部知识库中检索相关信息来增强语言模型的生成能力。但是,现有的RAG方法在处理金融文档时仍然面临着一些挑战。
2. HybridRAG: 创新的解决方案
论文提出了一种名为HybridRAG的新方法,它巧妙地结合了两种不同的RAG技术:
-
VectorRAG: 基于向量数据库的传统RAG方法 -
GraphRAG: 基于知识图谱的RAG方法
通过融合这两种方法的优点,HybridRAG能够更有效地处理金融文档中的复杂信息。让我们来看看它是如何工作的:
2.1 VectorRAG
VectorRAG的工作流程如下:
-
将文档分割成小块 -
使用嵌入模型(如OpenAI的text-embedding-ada-002)将文本块转换为向量 -
将向量存储在向量数据库中(如Pinecone) -
对于给定的查询,在向量数据库中搜索最相关的文本块 -
将检索到的文本块作为上下文提供给语言模型 -
语言模型根据查询和上下文生成回答
这种方法的优点是可以快速检索到相似的文本内容,但可能难以捕捉复杂的语义关系。
2.2 GraphRAG
GraphRAG的工作流程如下:
-
从文档中提取实体和关系,构建知识图谱 -
将查询转换为图查询 -
在知识图谱中搜索相关的节点和边 -
提取子图作为上下文 -
将子图信息编码后提供给语言模型 -
语言模型根据查询和图结构生成回答
这种方法的优点是可以捕捉实体间的复杂关系,但可能在处理抽象概念时存在困难。
2.3 HybridRAG
HybridRAG结合了上述两种方法的优点:
-
对同一查询,同时在向量数据库和知识图谱中进行检索 -
将两种检索结果合并,形成更丰富的上下文 -
将合并后的上下文提供给语言模型 -
语言模型生成最终的回答
通过这种方式,HybridRAG可以同时利用向量检索的广泛相关性和知识图谱的结构化信息,从而生成更准确、更全面的回答。
3. 实验设计与结果
为了验证HybridRAG的有效性,研究人员使用了来自印度股市Nifty 50指数成分股公司的财报电话会议记录作为数据集。他们设计了一系列问答任务,并使用以下四个指标来评估不同RAG方法的性能:
-
忠实度(Faithfulness): 生成的答案是否可以从给定的上下文中推断出来 -
答案相关性(Answer Relevance): 生成的答案与原始问题的相关程度 -
上下文精度(Context Precision): 检索到的上下文与问题的相关程度 -
上下文召回率(Context Recall): 检索到的上下文是否包含了回答问题所需的所有信息
实验结果如下表所示:
| 方法 | 忠实度(F) | 答案相关性(AR) | 上下文精度(CP) | 上下文召回率(CR) |
|---|---|---|---|---|
| VectorRAG | 0.94 | 0.91 | 0.84 | 1.00 |
| GraphRAG | 0.96 | 0.89 | 0.96 | 0.85 |
| HybridRAG | 0.96 | 0.96 | 0.79 | 1.00 |
从结果中我们可以看到:
-
HybridRAG在忠实度和答案相关性方面表现最好 -
GraphRAG在上下文精度方面表现最佳 -
VectorRAG和HybridRAG在上下文召回率方面达到了满分
这些结果表明,HybridRAG通过结合VectorRAG和GraphRAG的优点,实现了更平衡和有效的性能。
4. 案例分析
为了更好地理解HybridRAG的优势,让我们来看一个具体的例子:
假设我们有一个关于某公司财务状况的问题:"公司2023年第二季度的净利润是多少?"
-
VectorRAG可能会检索到包含"2023年第二季度"和"净利润"这些关键词的文本段落。 -
GraphRAG可能会在知识图谱中找到"公司-财务指标-净利润"这样的路径,并提取相关数据。 -
HybridRAG则会同时利用这两种信息:
-
从向量检索中获取更广泛的上下文,如公司整体财务状况的描述 -
从知识图谱中获取精确的数值信息和相关实体间的关系
最终,HybridRAG生成的答案可能会是:"根据公司2023年第二季度财报,净利润为1000万美元,较上年同期增长15%。这一增长主要得益于公司在新兴市场的扩张和成本控制措施的实施。"
这个答案不仅提供了准确的数字信息,还包含了相关的背景和解释,展示了HybridRAG融合不同来源信息的能力。
5. 代码示例
虽然论文中没有提供完整的代码实现,但我们可以根据其描述,给出一个简化的HybridRAG实现示例:
import pinecone
from langchain import OpenAI, VectorDBQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.graphs import NetworkxEntityGraph
from langchain.chains import GraphQAChain
class HybridRAG:
def __init__(self):
# 初始化向量数据库
pinecone.init(api_key="your-api-key")
self.vector_db = pinecone.Index("your-index-name")
# 初始化知识图谱
self.kg = NetworkxEntityGraph()
# 初始化语言模型
self.llm = OpenAI(temperature=0)
# 初始化嵌入模型
self.embeddings = OpenAIEmbeddings()
def vector_search(self, query):
# 在向量数据库中搜索相关文本
vector = self.embeddings.embed_query(query)
results = self.vector_db.query(vector, top_k=5)
return [result.metadata['text'] for result in results]
def graph_search(self, query):
# 在知识图谱中搜索相关信息
graph_qa = GraphQAChain(graph=self.kg, llm=self.llm)
return graph_qa.run(query)
def generate_answer(self, query):
# 结合向量搜索和图搜索的结果
vector_context = self.vector_search(query)
graph_context = self.graph_search(query)
combined_context = "n".join(vector_context) + "n" + graph_context
# 使用语言模型生成最终答案
prompt = f"Question: {query}nContext: {combined_context}nAnswer:"
return self.llm.generate(prompt)
# 使用示例
hybrid_rag = HybridRAG()
question = "公司2023年第二季度的净利润是多少?"
answer = hybrid_rag.generate_answer(question)
print(answer)
这个简化的实现展示了HybridRAG的基本工作流程。在实际应用中,还需要更多的细节处理和优化。
6. 总结与展望
HybridRAG通过结合向量检索和知识图谱的优点,为金融领域的信息提取提供了一种新的解决方案。它不仅能够提高答案的准确性和相关性,还能够处理更复杂的查询和上下文关系。
未来的研究方向可能包括:
-
扩展到多模态输入,如图像和表格数据的处理 -
改进数值分析能力,以更好地处理财务报表中的数字信息 -
探索与实时金融数据流的集成,以提供更及时的分析
