
面对这些 RAG 问题,本文根据 text2vec 模型原理做假设,并用 HuixiangDou 真实数据进行验证,最终给出 chunksize 上下界。 本文认为关键是让 tokenize 后的长度和模型输入(如 512)对齐,以发挥出模型完整编码能力。而 chunksize 只是 splitter 的附属选项。 相对于默认参数,精细调参可以改善约 2% 的 F1 指标;而用错 chunksize 可能导致 10% 下降。 相关测试数据、代码和说明文档已开源,如果对你有帮助,欢迎 star! https://github.com/internlm/huixiangdou
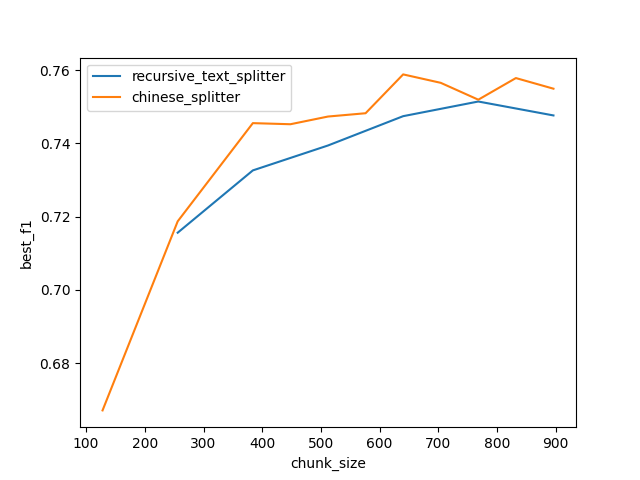
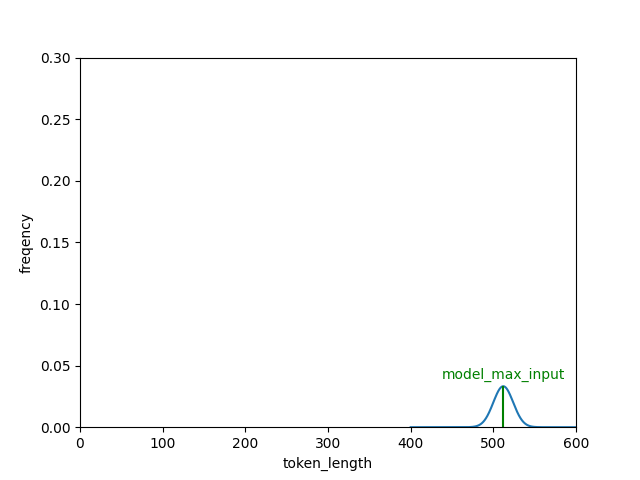
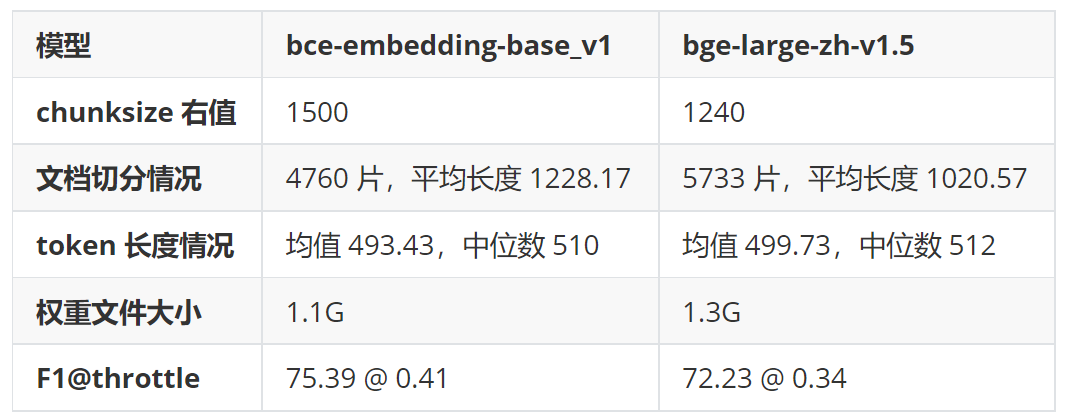
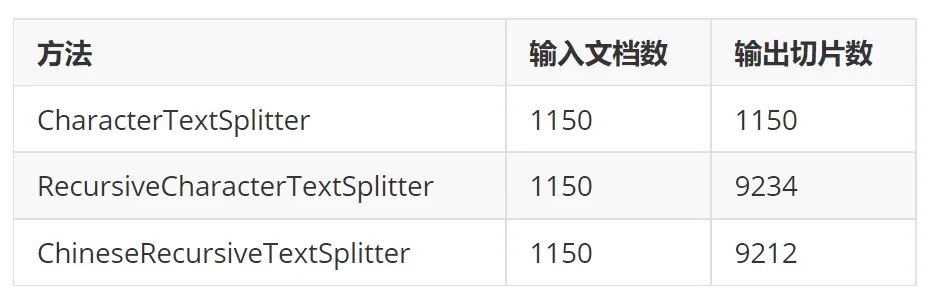
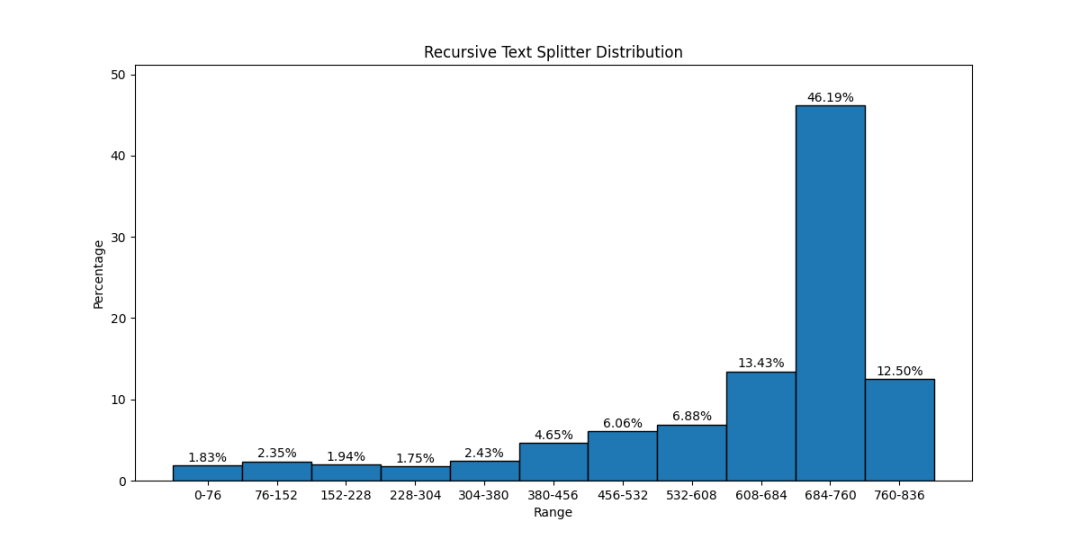
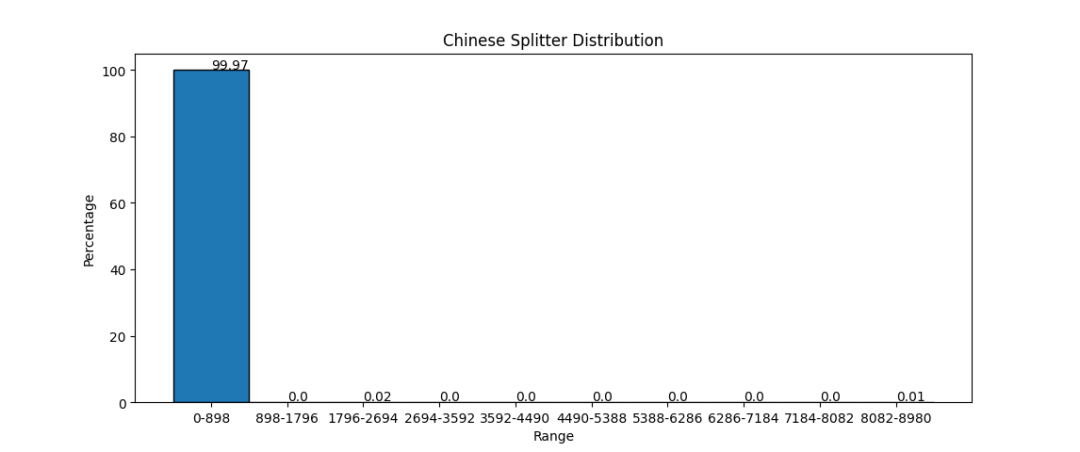
text2vec 和 autoencoder 现实世界中,很多数据是未标注、甚至无法标注的。我们希望神经网络同样能够理解这些数据,然后通过微调或调整结构“赋能”到下游任务。自编码器(autoencoder)就是这类无监督学习的一种范式。 上图是 autoencoder 的基本结构 [1],它由两部分组成: 编码器。负责提取无监督数据 Input 的表征 h 解码器。尝试把 h 恢复为原始输入,得到 Output 显然 Loss 来自 Input 和 Output 的差异,最终 h 的信息量应和 Input 相同。 在 text2vec 模型的训练中(如 RetroMAE [2]),编码器可能使用 BERT [3],解码器使用 Transformer 的单层 decoder。最终在下游业务中丢弃解码器、只保留编码器提取特征。 以 BCEmbedding [4] 为例,输入经 tokenize,填充或截断到 512 长度后执行模型推理。 然而用户输入的词元(token)并非刚好 512 个,这造成模型编码能力的浪费(填充)或原始信息缺失(截断)。 因此 text2vec 调参目标是:分词后的长度和模型输入对齐。 测试数据 HuixiangDou(豆哥)是运行在群聊场景中的领域知识助手。 在运行前,用领域知识文档(如 word/pdf/markdown 等) 创建知识库 base、配置先验阈值 throttle 运行期间,针对用户的每句话 query,都要计算和知识库的得分 score = text2vec(base, query),把低于 throttle 的问题充作 LLM chat 中的 history 或指代消歧的背景知识,并不触发 RAG 这个拒答过程和面部识别类似,都是通过计算特征距离提取最近/最远的底库。 本文使用的知识库是 OpenMMLab 相关的 9 个 repo 中的所有 markdown、txt 和 pdf 文档,累计 1150 个。文档长度均值 5063;长度中位数 2925。 本文的 query 来自 OpenMMLab 用户群和 ncnn 开发者群,累计 2302 条问题。通过人工标注,判定问题与知识库是否相关。 测试脚本和数据已开源到 GitHub。 测试结果 1. 对 text2vec 来说,chunksize 选多大合适? 对 BCE,本文推荐范围是 (512, 1500);对 BGE 推荐 (423, 1240)。豆哥目前使用 832。 左值 如下图所示。x 轴是 chunksize;y 轴是不同 throttle 取到的最优 F1 score。两条曲线代表不同 splitter 方法。 可以看到低于 512 的 chunksize 都达不到最优 F1。 右值 豆哥创建知识库时,要先把 1150 份文档切分成片段、编码成 tokens。假设这些 tokens 长度符合正态分布。 如果分布的均值和模型一样是 512,那么处于分布右侧的片段,会出现截断导致信息缺失;而分布左侧的要填充到 512。 通过使用 embedding.tokenizer 和 ChineseTextSplitter,本文调试出了对应 chunksize 数值。 考虑到输入缺失更影响精度,因此选取更小的 chunksize 让分布左移、能缓解信息缺失,从而得到更好的 F1 score;左移多少取决于数据的真实分布。 通过在 BCE 上暴搜验证,当 chunksize=640,throttle=0.44 时,F1 上涨 0.5,达到更好的 75.88。 2. 应该选择哪种 splitter ? 前面的左值测试已经展现出 ChineseTextSplitter 的优势。 更严谨地,本文固定 chunk_size=768,从统计的角度,对比以下三种 splitter 切分结果的差异。 可以看出基于 nn 的 CharacterTextSplitter 实际上没实现切分。 然后对比 RecursiveCharacterTextSplitter 和 ChineseTextSplitter 长度分布: 相对于依次尝试 ["nn", "n", " ", ""] 的 RecursiveCharacterTextSplitter,ChineseTextSplitter 对中文场景特定优化,遇到无中文语义的文档(如 CMakeLists.txt)会放弃切分,返回原始输入。 简单来说,中文场景优选 ChineseRecursiveTextSplitter,英文场景推荐 RecursiveCharacterTextSplitter,避免直接使用 CharacterTextSplitter。 3. BCE 还是 BGE ? 前面验证右值时,已给出 HuixiangDou 在 BCE 和 BGE [5] 上的精度结果(75.39 vs 72.23)。本文并未观察到二者在结构上有显著差异,考虑到 BGE 模型更大,因此推测 BCE 的训练数据和豆哥更匹配。 由于 BGE 提供了完整的复现过程、论文和源码,对于注重数据隐私的业务,BGE 更适合微调和难例挖掘。 总结 本文基于 HuixiangDou 真实数据,给出 text2vec 模型的 chunksize 的上下界,同时提供选择 splitter 和 text2vec 模型的依据。当然本次验证并不全面,仍需覆盖更多领域(如电力)和任务类型(如图文混合检索),我们将进一步探索。 需要额外说明的是,为了让机器人“有问必答”、避免太高冷,豆哥源码关注的是 recall 而非 F1,实际阈值会偏低。


暂无讨论,说说你的看法吧
