

我们在日常的工作中除了非结构化数据外,总会有一些表格数据感到很棘手不好拆分,做问答准确率也不高;例外还有一些结构化的数据需要处理,这个时候如果大模型能输出结构化的查询语句,那就很妙了。今天介绍一款在GitHub上面10.1k star的项目,感觉用起来很简单。
这个仓库名为Vanna,是一个开源项目,它是一个基于Python的RAG(Retrieval-Augmented Generation,检索增强型生成)框架,专门用于SQL生成和相关功能。以下是该项目的主要特点和功能:
项目介绍
-
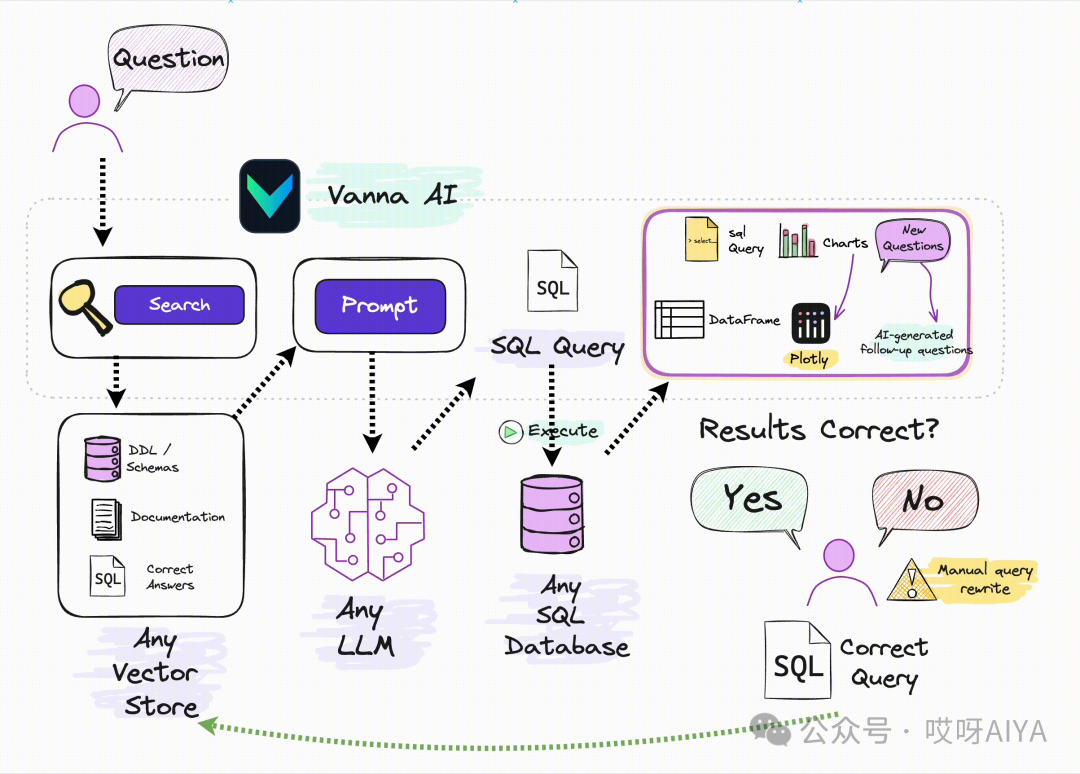
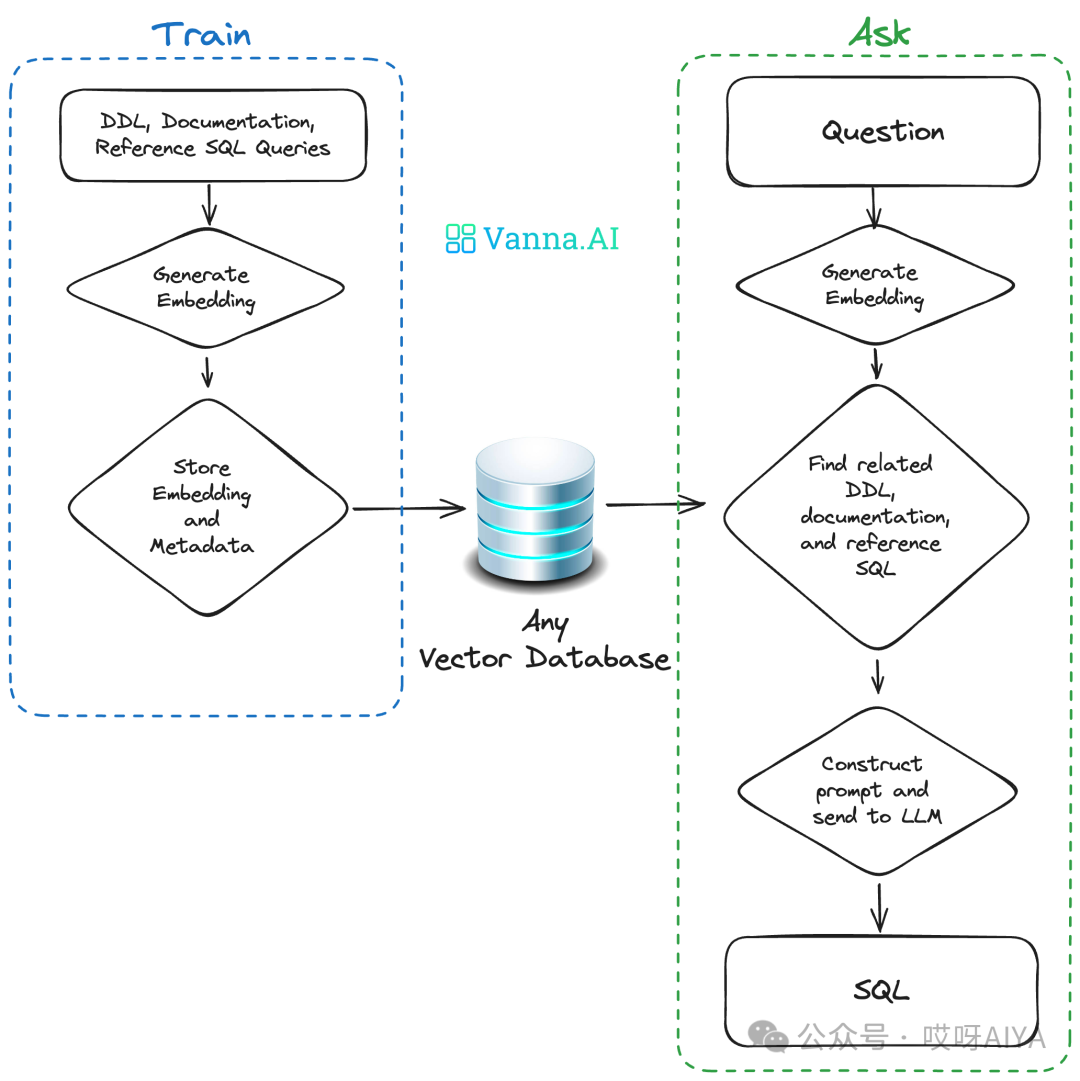
训练训练一个RAG模型到你的数据上。 -
提出问题,这些问题将返回可以设置为自动运行在你的数据库上的SQL查询。
环境搭建
运行所需要的依赖环境:
pip install vanna
模型加载
配置模型也非常简单:
# The import statement will vary depending on your LLM and vector database. This is an example for OpenAI + ChromaDBfrom vanna.openai.openai_chat import OpenAI_Chatfrom vanna.chromadb.chromadb_vector import ChromaDB_VectorStoreclass MyVanna(ChromaDB_VectorStore, OpenAI_Chat):def __init__(self, config=None):ChromaDB_VectorStore.__init__(self, config=config)OpenAI_Chat.__init__(self, config=config)vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})# 使用自己的模型# vn = MyVanna(config={'path': '/path/to/chromadb'})
模型训练
vn.train(ddl="""CREATE TABLE IF NOT EXISTS my-table (id INT PRIMARY KEY,name VARCHAR(100),age INT)""")
vn.train(documentation="Our business defines XYZ as ...")
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")
vn.ask("What are the top 10 customers by sales?")
为什么选择Vanna
-
在复杂数据集上具有高精度。
-
Vanna 的能力与您提供给它的训练数据相关联
-
更多的训练数据意味着对于大型和复杂的数据集,准确性更高
-
安全且私密。
-
您的数据库内容永远不会发送到 LLM 或向量数据库
-
SQL 执行在本地环境中进行
-
自学习。
-
如果通过 Jupyter 使用,您可以选择在成功执行的查询上“自动训练”它
-
如果通过其他接口使用,您可以让接口提示用户提供有关结果的反馈
-
将存储对 SQL 的正确问题以供将来参考,并使未来的结果更加准确
-
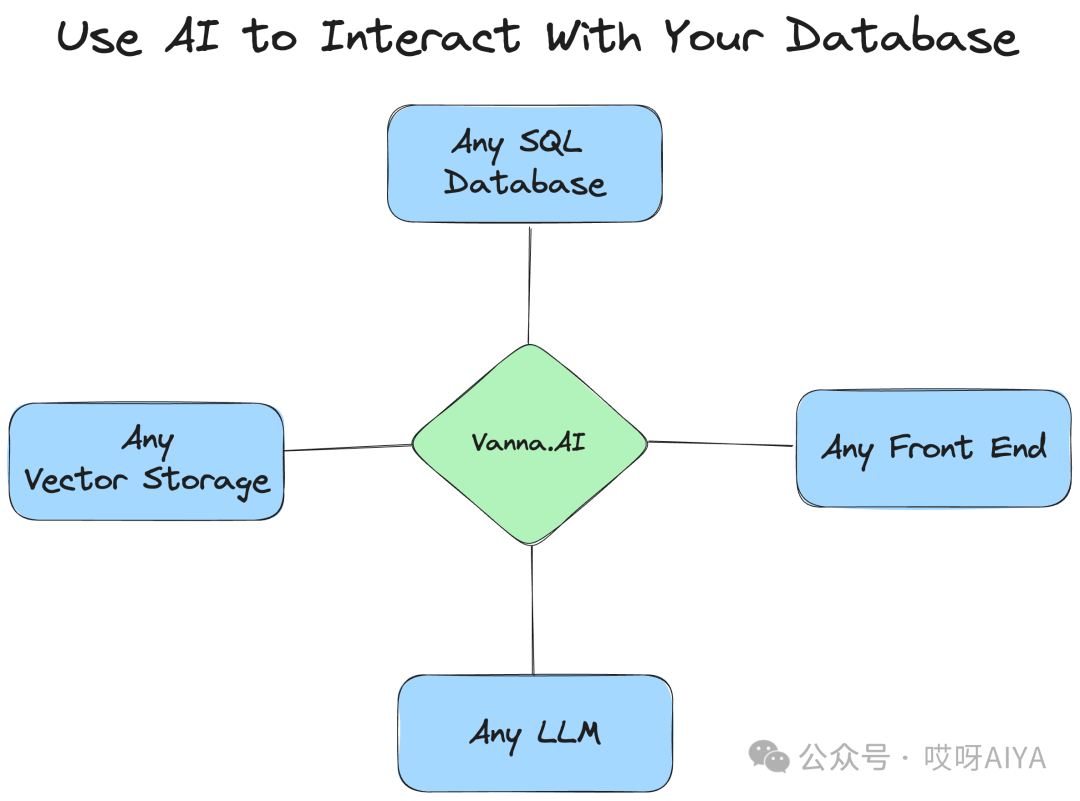
支持任何 SQL 数据库。
-
该包允许您连接到任何 SQL 数据库,否则您可以使用 Python 连接到这些数据库
-
随意选择前端。
-
大多数人从 Jupyter Notebook 开始。
-
通过 Slackbot、Web 应用、Streamlit 应用或自定义前端向最终用户展示。
-
Vanna设计用于连接任何数据库、LLM和向量数据库,项目提供了OpenAI和ChromaDB的实现,并且可以轻松扩展以使用自定义的LLM或向量数据库。
6. 扩展性:
# 项目地址https://hub.yzuu.cf/vanna-ai/vanna# 仓库文档https://vanna.ai/docs/postgres-openai-standard-other-vectordb/
