

大多数现有方法仅从检索语料库中检索短的连续块,限制了对整个文档上下文的整体理解。RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)引入了一种新方法,即递归嵌入、聚类和总结文本块,从下往上构建具有不同总结级别的树。在推理时,RAPTOR 模型从这棵树中检索,整合不同抽象级别的长文档中的信息。RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)比传统的检索增强型 LM 性能与绝对准确度上提高 20%。
一、RAPTOR 检索树的构建过程
-
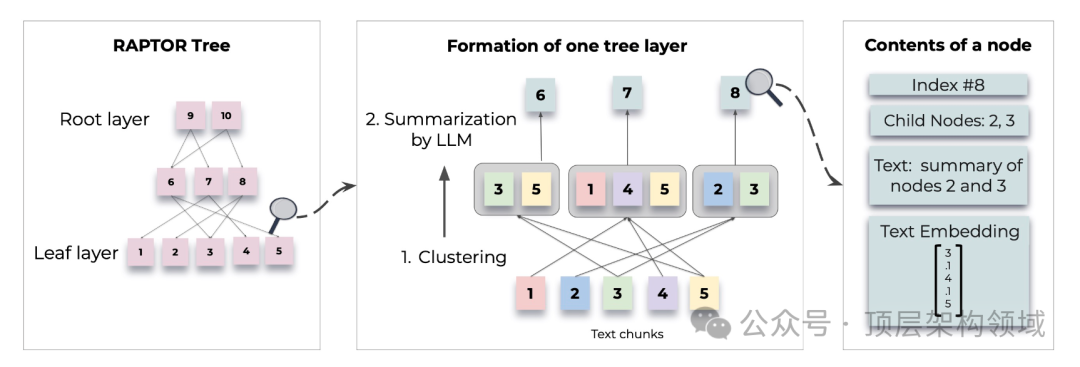
首先,需要对文本进行合理的切片处理。这里需要注意选择合适的切片算法很重要,建议参考主流框架的实现方案。 -
然后,RAPTOR 根据其语义embedding递归地对文本块chunk进行聚类,并生成这些聚类的文本摘要。 -
RAPTOR采用软聚类方法,允许文本块跨多个聚类,基于高斯混合模型(GMMs)和UMAP技术进行降维,以捕捉文本数据的复杂结构和关系,从而优化文本聚类效果。 -
RAPTOR通过递归的向量分析,精准地对文本块进行聚类,并提炼出这些聚类的核心摘要,自下而上地构建出一个结构化的树形模型。在此树中,相近的节点自然聚集形成兄弟关系,而它们的父节点则承载着整个集群的概要性文本信息。这种设计确保了文本信息的层次化和结构化表达,便于理解和检索。
二、RAPTOR 的检索过程
-
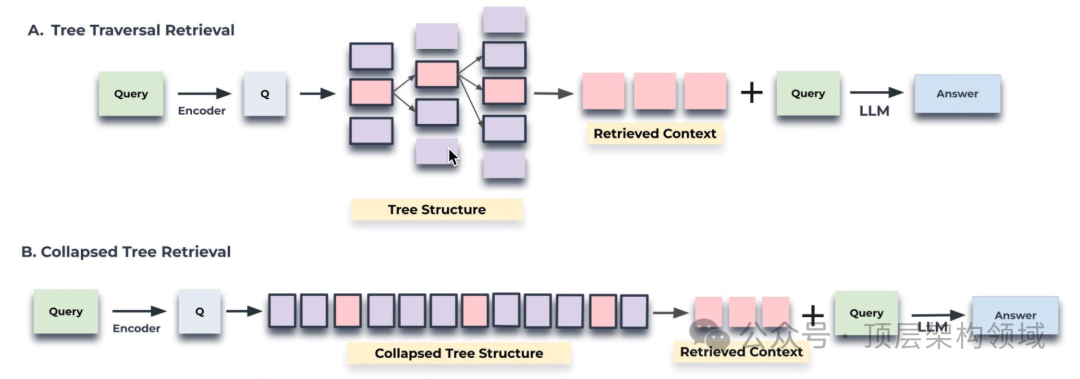
深度检索树从树的根级别开始,根据与查询向量的余弦相似度检索顶层的 top-k (这里为 top-1) 节点。在每一层,它根据与查询向量的余弦相似度从上一层的 top-k 节点的子节点中检索 top-k 节点。这个过程一直重复,直到达到叶节点。最后,将所有选定节点的文本连接起来形成检索到的上下文。 -
广度检索树方法将整个树压缩成单一层,然后根据与查询向量的余弦相似度评估所有层的节点,直到达到设定阈值。
三、开源项目案例应用示例
# 安装,在使用 RAPTOR 之前,请确保已安装 Python 3.8+。克隆 RAPTOR 存储库并安装必要的依赖项:git clone https://github.com/parthsarthi03/raptor.gitcd raptorpip install -r requirements.txt# 开始使用 RAPTOR,请按照以下步骤操作:# 首先,设置您的 OpenAI API 密钥并初始化 RAPTOR 配置:import osos.environ["OPENAI_API_KEY"] = "your-openai-api-key"from raptor import RetrievalAugmentation# Initialize with default configuration. For advanced configurations, check the documentation. [WIP]RA = RetrievalAugmentation()# 将您的文本文档添加到 RAPTOR 进行索引:with open('sample.txt', 'r') as file:text = file.read()RA.add_documents(text)# 现在可以使用 RAPTOR 根据索引文档回答问题:question = "How did Cinderella reach her happy ending?"answer = RA.answer_question(question=question)print("Answer: ", answer)# 将构造好的树保存到指定路径:SAVE_PATH = "demo/cinderella"RA.save(SAVE_PATH)# 将保存的树重新加载到 RAPTOR 中:RA = RetrievalAugmentation(tree=SAVE_PATH)answer = RA.answer_question(question=question)
