

1 概述
从本文开始,将开一个大坑,陆续介绍企业级文档问答系统构建的全流程,以及关键环节的优化手段。重点介绍算法流程。
构建一个基础版的RAG是非常简单的,甚至使用扣子、Dify等平台,熟练的情况下都用不了5分钟,即使使用Langchain、LlamaIndex等框架,搭建完整流程,代码也不会超过100行。但基础版的问答效果往往较差。
下面这张图是OpenAI介绍的RAG优化经验,这个准确率当然随不同的数据集会有不同,但基本上优化后的准确率比优化前有显著提升这个基本上是一致的。
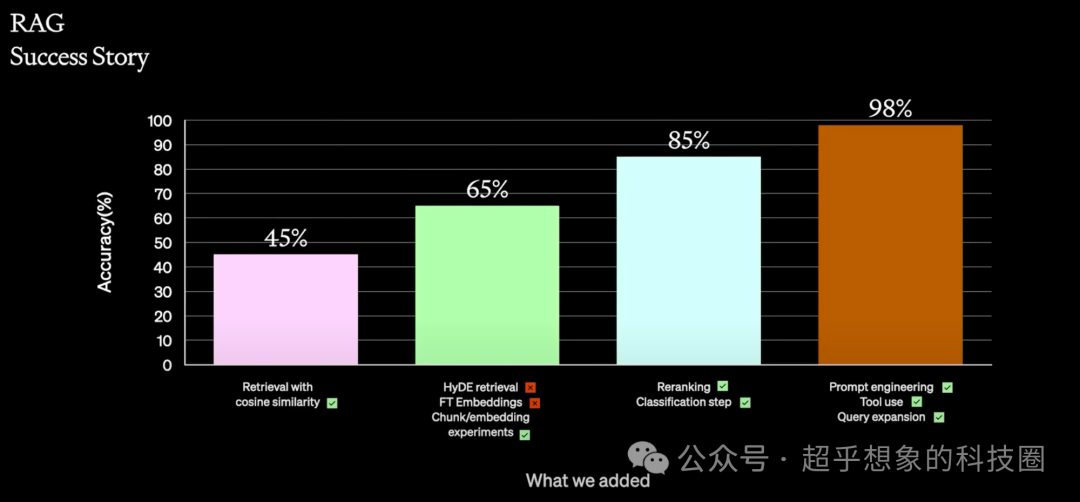
问答系统构建完成后,总的流程是先对文档进行解析、切分,然后使用问题检索相关知识片段,最后将问题和知识片段输入LLM,生成答案。
在构建的过程中也是一样的,这三个环节是可以分别独立优化的,如下图所示:
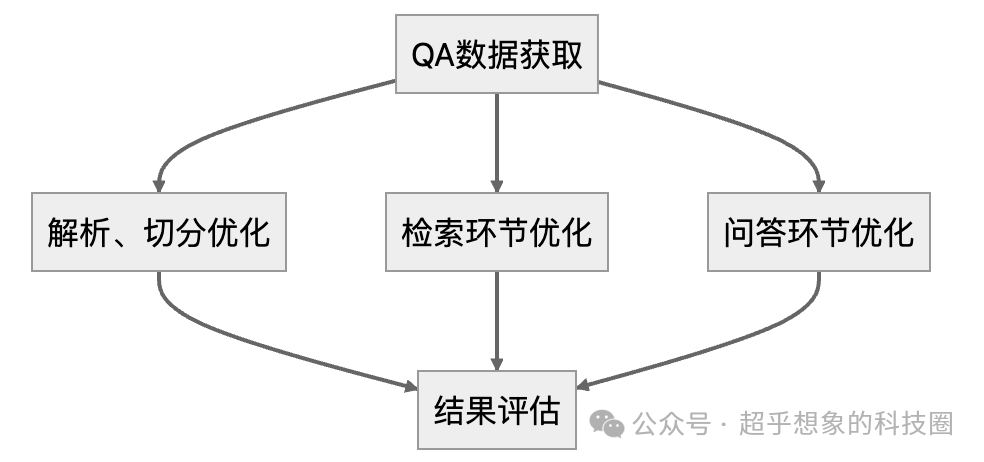
本篇首先专注在如何获取QA数据,所谓的QA数据,就是“问题-回答”数据,理想情况下,如果包含回答所用到的文档片段是更好的。部分系统(如客服系统)是有这方面数据的,但绝大多数情况下是没有的,这时就需要首先构造一批问答数据,这是后续所有环节最重要的一步。
本系列将会使用中国银行所发布的《2024全球经济金融展望报告》作为文档,围绕针对这个文档的问答效果优化展开。
本文所介绍的方法,会使用千问官方的qwen-long模型,对《2024全球经济金融展望报告》这个文档抽取QA,这个模型足够便宜,抽取的结果质量也还不错。QA抽取包含如下3个步骤:
-
短文档片段QA抽取:这部分模拟日常情况下,经常会询问细节性问题的使用场景
-
长文档片段QA抽取:这部分模拟需要综合较多上下文才能回答的使用场景
-
QA质量打分:使用LLM再次对抽取的QA进行质量评估,这一步算是借鉴了微软phi-1.5模型Textbooks Are All You Need论文中的方法,就是借助模型对数据质量进行评估
整个过程花费不到1元,结果已经抽取好了,大家可以直接使用。
本文所对应代码已开源,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/00_PDF%E8%A7%A3%E6%9E%90%E4%B8%8EQA%E6%8A%BD%E5%8F%96_v1.ipynb
2 准备环境
代码在Google Colab环境下进行了测试,正常情况下,安装Anaconda基本上会包含大部分所用到的包,再安装如下包即可:
为了便于大家复现,打印所安装的版本:
设置API key
3 文档解析与切分
4 QA抽取
既然是构造QA,那最好是保留回答问题时所使用的上下文,方便后续环节的优化。
4.1 QA抽取Prompt
这一步核心的2个Prompt如下:
4.2 QA抽取代码
抽取核心代码,此处使用多线程加速抽取,考虑到网络请求异常情况会比较多,因此增加失败重试机制,同时考虑到这是一个耗时操作,并保存中间结果,以确保失败或者再次运行时,已经执行过的部分不会被重复执行:
4.3 抽取样例
4.4 后置处理
从上面的样例可以看出,结果是被json...包裹的,没有办法直接解析为JSON,使用正则表达式进行后置处理,提取JSON
5 QA质量检查
这部分就是对qa_df中的问题-回答对,再打一次分,然后过滤低分结果,Prompt如下:
总体又是一个循环,与QA抽取部分非常相似,此处不再粘贴代码,需要的朋友们请访问代码仓库。
5.1 打分结果样例
5.2 3分样例
-
问:报告中提到的主要经济体GDP增速变化趋势的图的名称是什么?
-
答:主要经济体GDP增速变化趋势
-
上下文:图2:主要经济体GDP增速变化趋势(%)
5.3 2分样例
-
问:消费者借贷能力和意愿受到什么因素的影响?
-
答:美国家庭债务余额拖欠率回升至3%
-
上下文:美国家庭债务余额拖欠率回升至3%,消费者借贷能力和意愿将有所下降。
可以看出,低分问答对,质量确实相对较低
5.4 最终数据集构建
这部分首先保留4分及以上的问答对,然后随机挑选100条数据作为后续的测试集。至此,准备工作完成。
