

前言
传统的单模态RAG只能实现基于文本的检索召回,但是在企业级应用场景中,存在大量文本、图片、表格混排的复杂文档。对于这类文档的检索召回,单模态RAG难以给出精确有效的答案。
比如在工业制造,工程师需要检索某个设备的安装方法,详细的文字描述不如一张安装流程图。或者工程师要检索某个传感器的性能参数,再详尽的文字介绍都不如一张清晰的表格。
不仅是工业制造,包括生物医药、零售快消、汽车、教育等等行业,甚至是面向C端的应用场景,图文并茂的输出内容,都会大大提升用户的体验。比如,当你询问AI大模型“RAG系统的原理是什么”的时候,你是期待一个纯文字的回答,还是一个RAG系统架构图 + 文字介绍的回答呢?
因此,在这样的场景下,多模态RAG将大有可为。
多模态RAG的挑战
相比单模态RAG,多模态RAG的挑战更大,主要体现在以下几个方面:
图片和表格解析困难:图片内容可能比较复杂,影响后续的特征提取和内容理解;而表格的格式可能会各式各样,如何准确地对表格进行结构化提取,也是一个巨大的挑战。
信息关联复杂:提取出的文本、图片和表格等信息之间的关联关系难以准确界定,比如图片对应的文字可能在文档的不同位置,传统的chunk方式势必会出现内容丢失,如何将这些信息正确关联起来,也是一大难点。
多模态数据融合索引:需要找到合适的方法,将文字、图片、图表、甚至音频和视频的索引进行关联和整合,确保在检索时能够高效地查询到相关的多模态数据。
多模态查询理解与转换:如何准确地将用户的文本查询,转换为能够与多模态索引进行匹配的查询向量?例如, “查找包含某产品图片,且描述中提到其功能的文档”,需要将 “产品图片” 和 “功能描述” 等信息准确地转换为图像特征向量和文本查询条件。
跨模态相关性计算:在检索过程中,需要计算文本查询与图片、表格等数据之间的相关性。但是,不同模态数据之间的语义鸿沟,使得相关性计算较为困难,如何定义和计算跨模态的相似度是另一大挑战。
下面,围绕多模态RAG的问题和挑战,风叔介绍三种主流的方法,基于语义抽取、基于视觉模型和基于多模态数据融合。
方案一,基于语义抽取
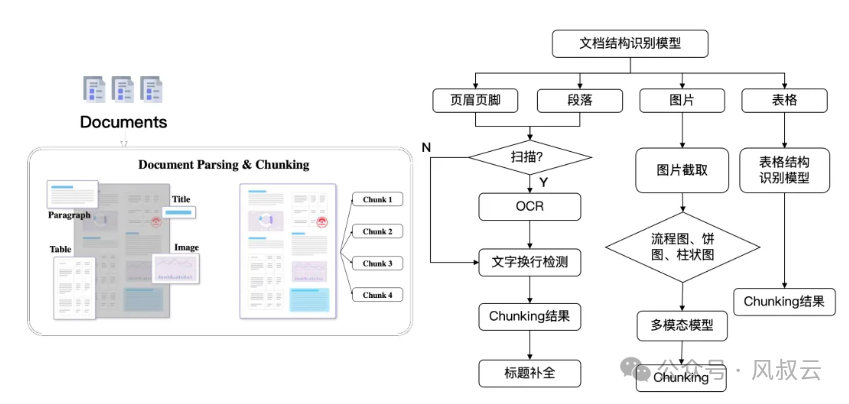
第一步,文档结构识别
第二步,对象解析与特征提取
-
信息全面:能够深入处理文档中的各种模态信息,尽可能全面地抽取和利用文本、图像、表格等多方面的内容,减少信息丢失 -
语义准确:通过对不同模态信息的语义解析和特征提取,可以更准确地把握文档的含义,提高检索和生成结果的准确性和相关性 -
可解释性:在每个处理步骤中都有明确的语义分析和转换过程,使得系统的运行和结果具有不错的可解释性
但是这种方案,也有较为明显的缺陷,包括:
-
处理效率低:涉及多个复杂的处理步骤,计算量较大,处理速度相对较慢,尤其在面对大规模文档数据集时,会导致较长的响应时间。
-
模型复杂度高:需要多种不同模型来处理不同模态的信息,如 OCR 模型、表格识别模型、图像理解模型等,增加了系统的建设和维护成本。
-
复杂文档处理挑战大:对于结构复杂、格式不规范或包含多种特殊元素的文档,准确识别和解析各种模态信息会存在困难,例如不规则表格、嵌套图表。
方案二,基于视觉语言模型VLM
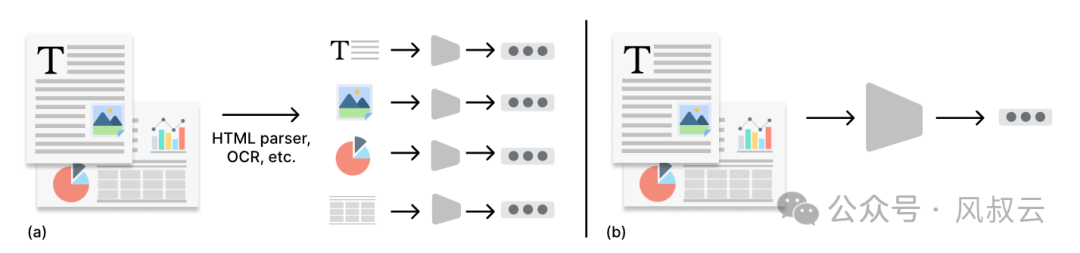
视觉语言模型VLM的优点是:
-
强大的多模态理解能力:能够深入理解图像和文本等多种模态信息的语义及其相互关系,从而更全面、准确地处理多模态数据,为用户提供更精准的回答和更丰富的信息。 -
端到端的处理方式:无需针对不同模态分别进行复杂的特征工程和处理流程,而是通过统一的模型架构实现多模态信息的联合处理,简化系统设计和开发流程。 -
可迁移性和泛化能力强:预训练的 VLM 可以在多种不同的多模态任务和领域中进行微调应用,具有较好的可迁移性和泛化能力,能够快速适应新的任务和数据场景。
-
模型训练和部署成本高:VLM 通常包含大规模的参数,训练和部署需要大量的计算资源。 -
实时性挑战:由于模型结构复杂、计算量大,在处理实时性要求较高的任务时,可能会出现响应延迟较长的问题 -
可解释性不足:VLM 的决策过程和结果相对难以解释,用户可能难以理解模型为什么会生成这样的结果,在一些对可解释性要求较高的领域(如医疗、金融),会受到一定限制。
方案三,基于多模态数据融合
多模态数据融合,顾名思义,是指将不同类型的数据和信息进行整合,以提供更全面的分析能力。多模态数据融合有多种实现方式,其中比较常见的是分离检索方法。
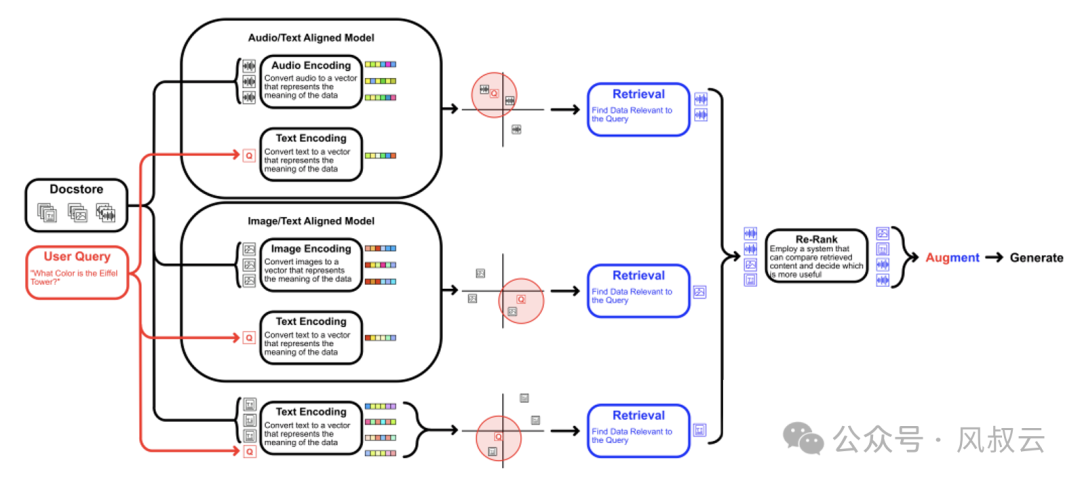
-
充分利用模态特性:能够针对每种模态数据的特点和优势进行专门的处理和检索,充分发挥不同模态数据的价值。这样可以在各自模态内实现更准确的检索,相比于将所有模态统一处理,可能会获得更符合该模态特性的结果。 -
灵活性和可扩展性:易于对单个模态的检索模型进行更新、替换或优化,而不会影响其他模态的处理。同时,也便于添加新的模态数据类型,只需要为新的模态开发相应的检索模块,并设计合适的融合策略即可,系统的扩展性较强。 -
降低模型复杂度:分离检索方法将多模态问题分解为多个单模态的问题进行处理,每个单模态的检索模型相对简单,计算量和模型复杂度较低。这使得模型的训练和部署更加容易。
-
模态间信息融合有限:虽然在结果融合阶段会考虑不同模态之间的关系,但由于在检索过程中各个模态是独立进行的,可能无法充分挖掘和利用模态间深层次的语义关联和互补信息。例如,图像中的某个物体可能与文本中的特定概念有紧密联系,但独立检索时可能无法直接捕捉到这种跨模态的细粒度关联,导致融合后的结果在综合理解和利用多模态信息方面存在一定的局限性。 -
多模态理解的局限性:分离检索方法在一定程度上缺乏对多模态数据的整体统一理解,可能无法很好地处理一些需要综合多模态信息进行深度理解和推理的复杂任务。
