

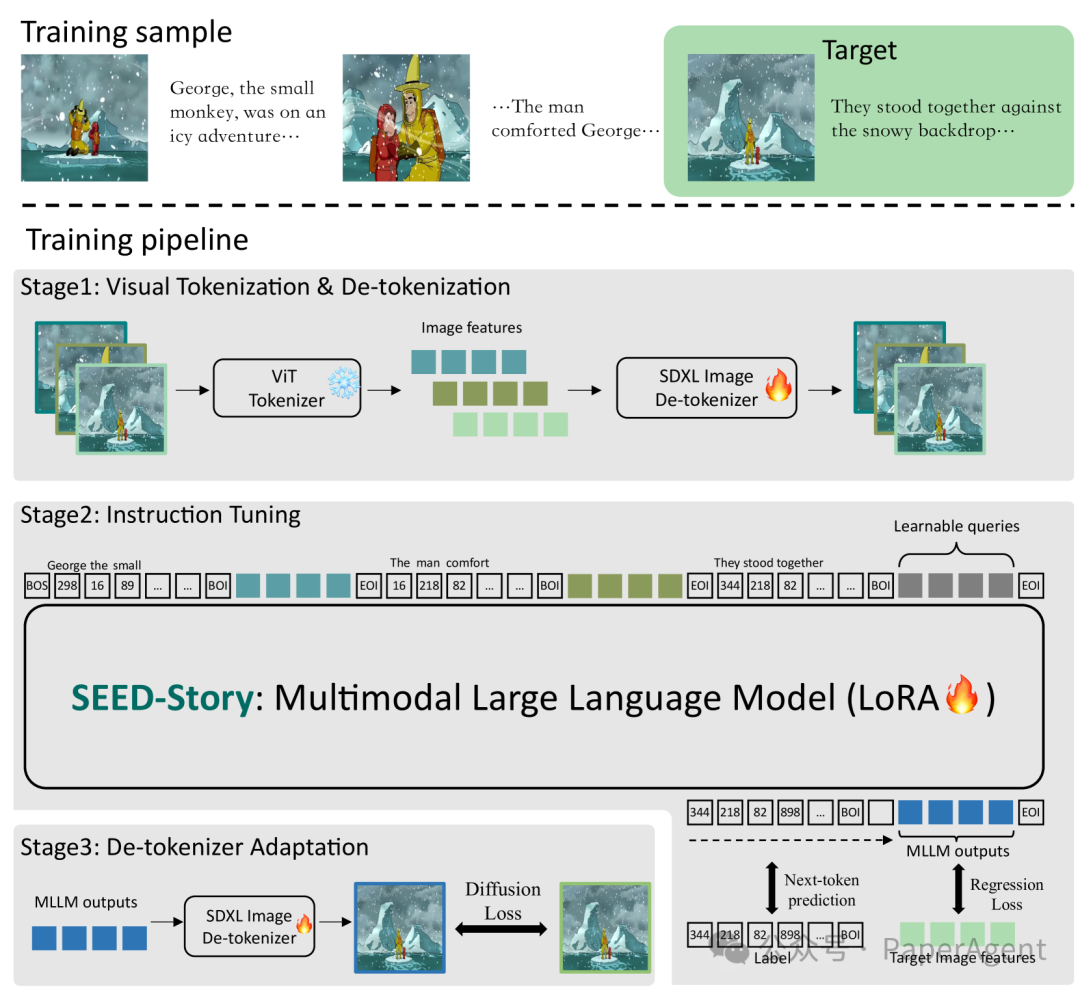
SEED-Story由MLLM驱动,能够从用户提供的图片和文本作为故事的开始,生成多模态长篇故事,模型、代码与数据都已开源。生成的故事包括丰富且连贯的叙事文本,以及在角色和风格上保持一致的图片。故事可以跨越多达25个多模态序列,尽管在训练期间仅使用最多10个序列。

-
在第一阶段,我们预训练一个基于SD-XL的去标记化器,通过接受预训练的ViT的特征作为输入来重建图片。 -
在第二阶段,我们采样一个随机长度的交错图像-文本序列,并通过对目标图像的ViT特征和可学习查询的输出隐藏状态之间的下一个词预测和图像特征回归来训练MLLM。 -
在第三阶段,从MLLM回归得到的图像特征被输入到去标记化器中,以调整SD-XL,增强生成图片中角色和风格的一致性。
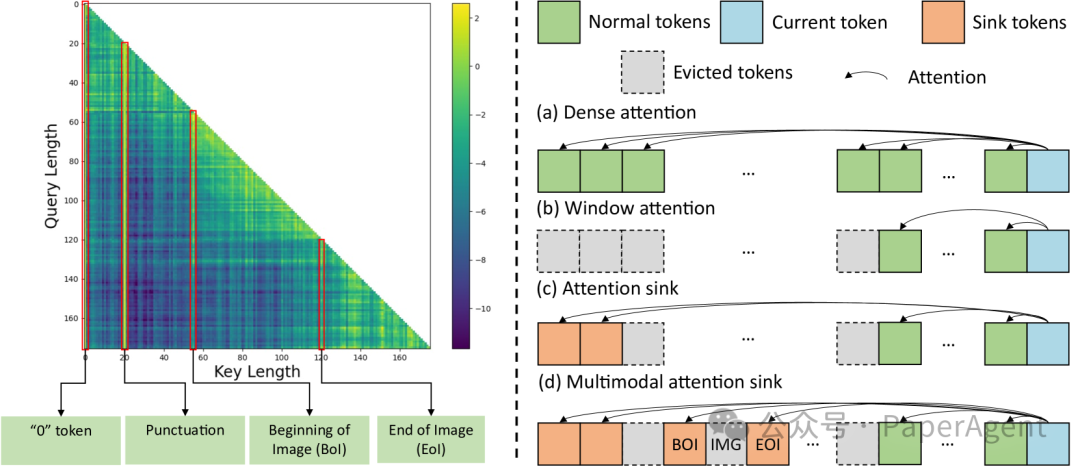
左侧:在多模态故事生成中预测下一个词时的注意力图可视化。我们观察到重要的注意力集中在整个序列的第一个词("0"词),标点符号词,与BoI(图像开头)相邻的词和与EoI(图像结尾)相邻的词上。右侧:(a) 密集型注意力图,它保留了KV缓存中的所有词。(b) 窗口型注意力,通过滑动窗口逐出前面的词。(c) 注意力汇聚,它基于窗口型注意力保留了开头的词。(d) 多模态注意力汇聚,它基于窗口型注意力保留了文本词的开头、图像词以及图像词的结尾。这可以有效地使我们的模型泛化到生成比训练序列长度更长的序列。

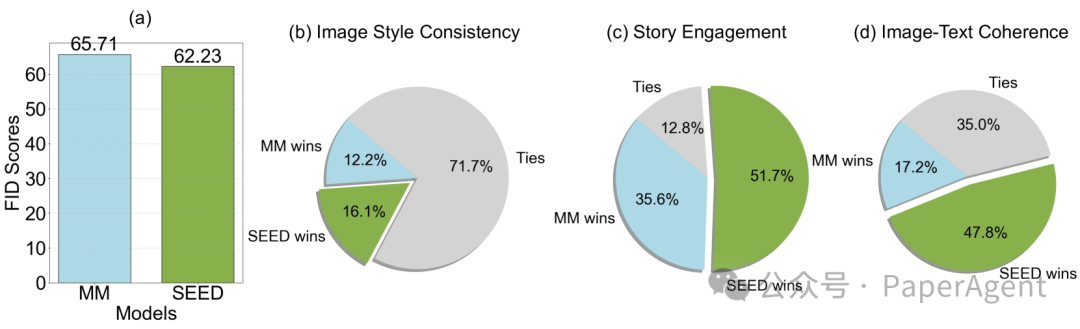
来自SEED-Story的多模态故事生成示例。它展示了从同一初始图像生成的两个叙事分支。顶部分支以引用“戴黄帽子的男人”的文本开始,导致包含该角色的图像生成。底部分支开始时没有提及男人,结果导致故事在排除他的情况下与第一个分支发生分歧。




https://github.com/TencentARC/SEED-StorySEED-Story: Multimodal Long Story Generation with Large Language Modelhttps://arxiv.org/pdf/2407.08683
