


导读
-
UI屏幕理解与交互的自动化:手机UI屏幕包含多种元素,如图标和文本,需要模型能够理解并与之交互以实现用户目标。
-
现有方法的局限性:现有的MLLM主要针对自然图像,直接应用于UI屏幕可能会受到限制,因为UI屏幕具有不同的纵横比和更小的兴趣对象。
-
模型架构改进:基于Ferret模型,集成了“任何分辨率”(anyres)功能,以适应不同纵横比的UI屏幕,并通过预定义的网格配置来划分全图像为子图像,增强细节识别。
-
UI任务构建:涵盖了从基本到高级的14种不同的移动UI任务,并为模型训练收集了详细的训练样本。
-
论文名称:Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs -
论文地址:https://arxiv.org/abs/2404.05719
-
代码:无

Introduction
-
调整模型架构以更好地处理屏幕数据
-
构建 UI 指代和定位任务数据集
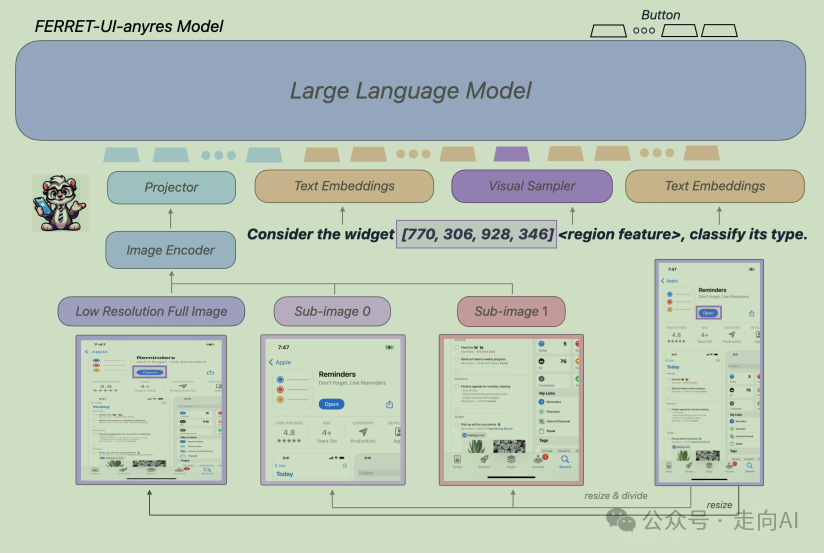
-
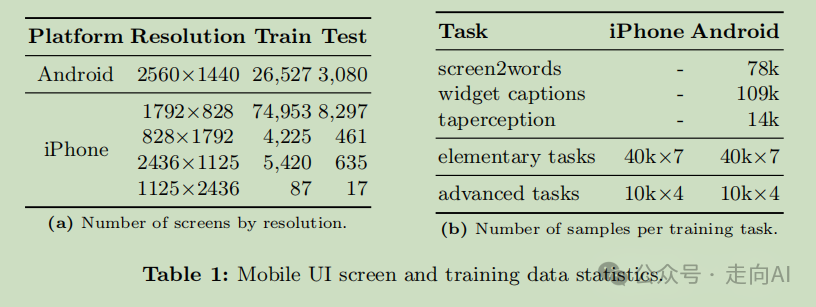
UI 屏幕图像与自然图像相比有更延伸的纵横比,如表 1a 所示;
-
本任务涉及许多感兴趣的对象(即 UI 部件,如图标和文本)比自然图像中通常观察到的对象要小得多。例如,许多问题集中在占据整个屏幕不到 0.1% 的图标上。
直接使用Ferret模型的输入会导致视觉细节的显著丢失。为了解决这个问题,参考SPHINX、LLaVA-NeXT 和 Monkey 中的 "任何分辨率"(anyres)概念,选择了两种网格配置,1×2 和 2×1,这些配置基于原始屏幕的纵横比选择,如表 1a 所示。
-
Screen2words:为这个屏幕截图提供一个摘要;
-
Widget Captions:对于交互元素 [bbox],提供一个最能描述其功能的短语;
-
Taperception:预测 UI 元素 [bbox] 是否可点击。
-
指代任务(Referring Tasks):这类任务涉及识别输入中的特定元素,并通常使用边界框(bounding boxes)来标识这些元素。具体来说,包括:
-
OCR:识别图像中的文字并将其转换为文本。
-
图标识别(Icon Recognition):识别界面中的图标并确定其功能或含义。
-
控件分类(Widget Classification):将界面中的控件(如按钮、文本框等)分类到预定义的类别。
-
定位任务(Grounding Tasks):与指代任务相对,关注的是确定输出中特定元素的位置,同样使用边界框来标识。这些任务要求模型不仅要理解元素的语义,还要能够在图像上精确地定位它们。具体任务包括:
-
控件列表(Widget Listing):列出界面上所有可识别的控件。
-
查找文本(Find Text):根据文本内容在界面上找到对应的文本区域。
-
查找图标(Find Icon):根据描述或功能找到对应的图标。
-
查找控件(Find Widget):根据控件的类型或功能找到特定的控件。

-
详细描述(Detailed Description):这个任务要求模型生成对用户界面元素的详细描述。
-
功能推理(Function Inference):这个任务涉及对用户界面元素功能的推断。
-
对话感知(Conversation Perception) 和 对话交互(Conversation Interaction):这两个任务与对话相关,要求模型能够理解和生成与用户界面相关的多轮对话。

Experiments
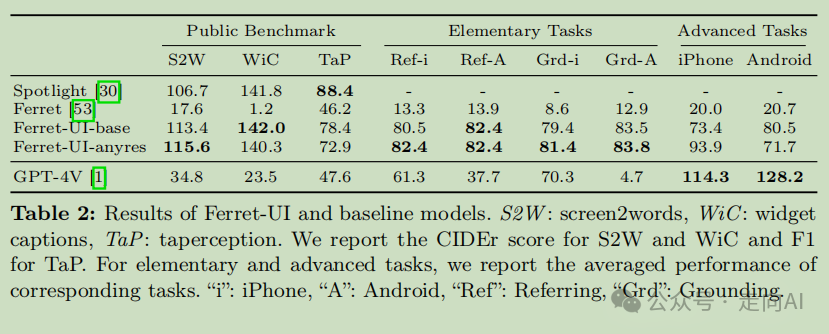
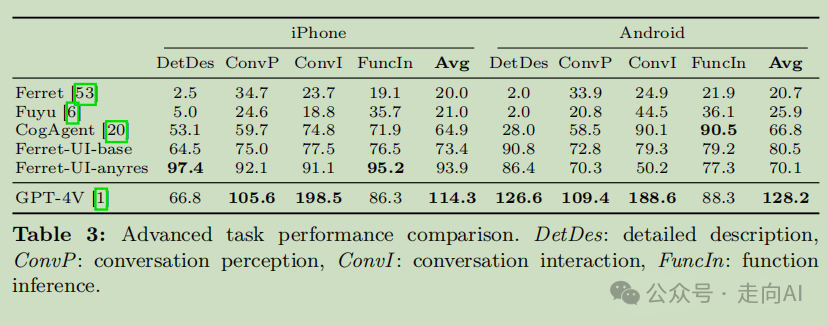
Analysis
-
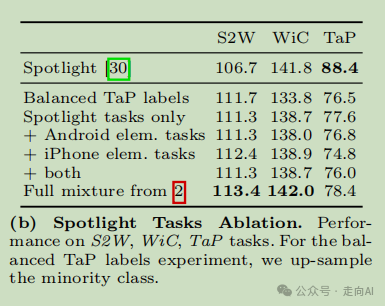
公共基准测试(Spotlight)和基础 UI 任务上:Ferret-UI 优于 GPT-4V
-
高级任务:高级任务上虽然超过同期的Fuyu和CogAgent,但还是比不过GPT-4V
-
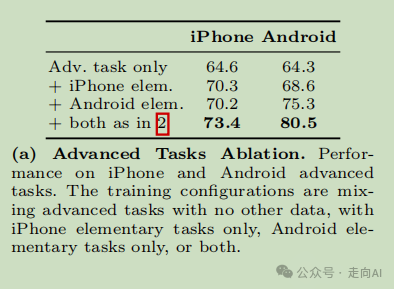
分辨率调整的影响:将 anyres 添加到 Ferret-UI-base 后,iPhone 的指代和定位任务性能提高了 2 个百分点。对于高级任务,使用 Ferret-UI-anyres,iPhone 的性能大幅提升了 20 个百分点,而 Android 的性能有所下降。由于 Android 高级任务数据未包含在训练混合中,随着模型对 iPhone 屏幕理解的知识丰富,它可能失去了一些泛化能力。
Ferret-UI的二作是Ferret-V2的一作,两篇文章几乎同时上传到arxiv上,从上面的模型整体框架图上可以看到,Ferret-UI和Ferret-V2类似,都是在Ferret的基础上引入任意分辨率,但Ferret-UI利用了手机截屏的先验知识:竖屏或者横屏,可以通过垂直方向或者水平方向切图将原图切成2个方块(不过如果遇到长截屏,仅靠1:2或者2:1应该还是不够的),也就不需要引入DINOv2这种细粒度的Visual encoder了。
