

点击蓝字 关注我们

引言
在上一篇文章中,我们成功实现了MinerU官方版API与Dify工作流的对接,但遗留了一个关键问题:原生API仅支持PDF格式解析。本文将深入讲解如何通过API代码改造,扩展支持以下办公文档格式:
✅ Office文档:Word(.docx)/PowerPoint(.pptx)
✅ 图像文件:JPEG/PNG
通过重写MinerU-API的文档解析模块,我们将实现这些文件到Markdown的自动转换。核心改造包括:
1. 文件类型检测逻辑增强
2. 新增Office文档解析器
3. 新增图片文档解析器
基本环境配置
1. liunx系统安装libreoffice
sudo apt updatesudo apt install libreoffice
2. windows安装pywin32
pip install pywin323. 安装 img2pdf
pip install img2pdfAPI源码修改
官方版本提供的api接口是使用FastAPI写的。原来的api仅支持pdf格式的文档,为了api支持office和图片格式,需要对源码进行修改。
1. 支持office格式
## mineru 官方已经写了linux版本读取office的api,直接使用就好了def convert_file_to_pdf(input_path, output_dir):if not os.path.isfile(input_path):raise FileNotFoundError(f"The input file {input_path} does not exist.")os.makedirs(output_dir, exist_ok=True)cmd = ['soffice','--headless','--convert-to', 'pdf','--outdir', str(output_dir),str(input_path)]process = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)if process.returncode != 0:raise ConvertToPdfError(process.stderr.decode())from magic_pdf.utils.office_to_pdf import convert_file_to_pdf as convert_office_file_to_pdf_linux
2. 支持图片格式
def convert_image_to_pdf(input_path, output_folder):''' 将图片转换成pdf '''import img2pdfpic_name, _ = os.path.splitext(input_path)output_path = os.path.join(output_folder, f"{pic_name}.pdf")os.makedirs(output_folder, exist_ok=True)with open(output_path, "wb") as f:f.write(img2pdf.convert(input_path))
3. 其他修改
3.1 简化初始化读取函数
def init_writers(file_path: str = None,output_path: str = None,output_image_path: str = None,) -> Tuple[Union[S3DataWriter, FileBasedDataWriter],Union[S3DataWriter, FileBasedDataWriter],bytes,]:""""""writer = FileBasedDataWriter(output_path)image_writer = FileBasedDataWriter(output_image_path)os.makedirs(output_image_path, exist_ok=True)reader = FileBasedDataReader()file_bytes = reader.read(file_path)return writer, image_writer, file_bytes
3.2 主process函数中增加处理不同类型文件的逻辑
## 解析上传的文档名称和文档类型file_name, ext = os.path.splitext(upload_file.filename)ext = ext.lower()## 判断文件类型是否符合要求if ext not in ['.pdf', '.docx', '.doc', '.ppt', '.pptx', '.png', '.jpg', '.jpeg']:return JSONResponse(content={"error": f"unsupport file type:{ext}"},status_code=400,)## 创建临时文件夹,保存上传文档temp_dir = tempfile.mkdtemp()temp_file_path = await save_file_to_local(upload_file, temp_dir)## 如果是office格式的文档,则转换成pdfprocess_file_name = temp_file_pathplat = platform.system()if ext in [ '.docx', '.doc', '.ppt', '.pptx']:if plat == "Windows":convert_office_file_to_pdf_windows(temp_file_path, temp_dir)else:convert_office_file_to_pdf_linux(temp_file_path, temp_dir)process_file_name = os.path.join(temp_dir, f"{file_name}.pdf")elif ext in ['.png', '.jpg', '.jpeg']:convert_image_to_pdf(temp_file_path, temp_dir)process_file_name = os.path.join(temp_dir, f"{file_name}.pdf")
构建Docker服务
1. 修改Dockerfile
基于官方的Dockerfile文件进行修改,新增我们需要用到的环境。在在mineru-api:v0.1镜像的基础上进行修改,mineru-api:v0.1构建可以参考上篇文章
FROM mineru-api:v0.1WORKDIR /app## 安装python环境RUN python -m venv /app/venv &&. /app/venv/bin/activate &&pip install img2pdf -i https://mirrors.aliyun.com/pypi/simple/## 安装sofficeRUN sed -i 's@deb.debian.org@mirrors.aliyun.com@g' /etc/apt/sources.list.d/debian.sourcesRUN apt-get update &&apt-get install -y --no-install-recommends libreoffice &&apt-get clean &&rm -rf /var/lib/apt/lists/*
2. 制作docker镜像
docker build -t mineru-api:v0.3 .3. 启动docker服务
docker run -d --gpus all -p 10086:8000 --ipc=host --name mineru-api-v3 -v minerupaddleocr:/root/.paddleocr mineru-api:v0.3效果测试
Swagger UI界面测试
1. 在FastAPI框架的自动生成的文档界面,通过浏览器地址栏输入localhost:10086/docs
2. 点击try it out
3. 找到upload_file,上传一个本地测试的文件
用上篇文章的截图作为测试文件:

4. 点击execute等待执行完成
5. 接口返回一个md_content参数。
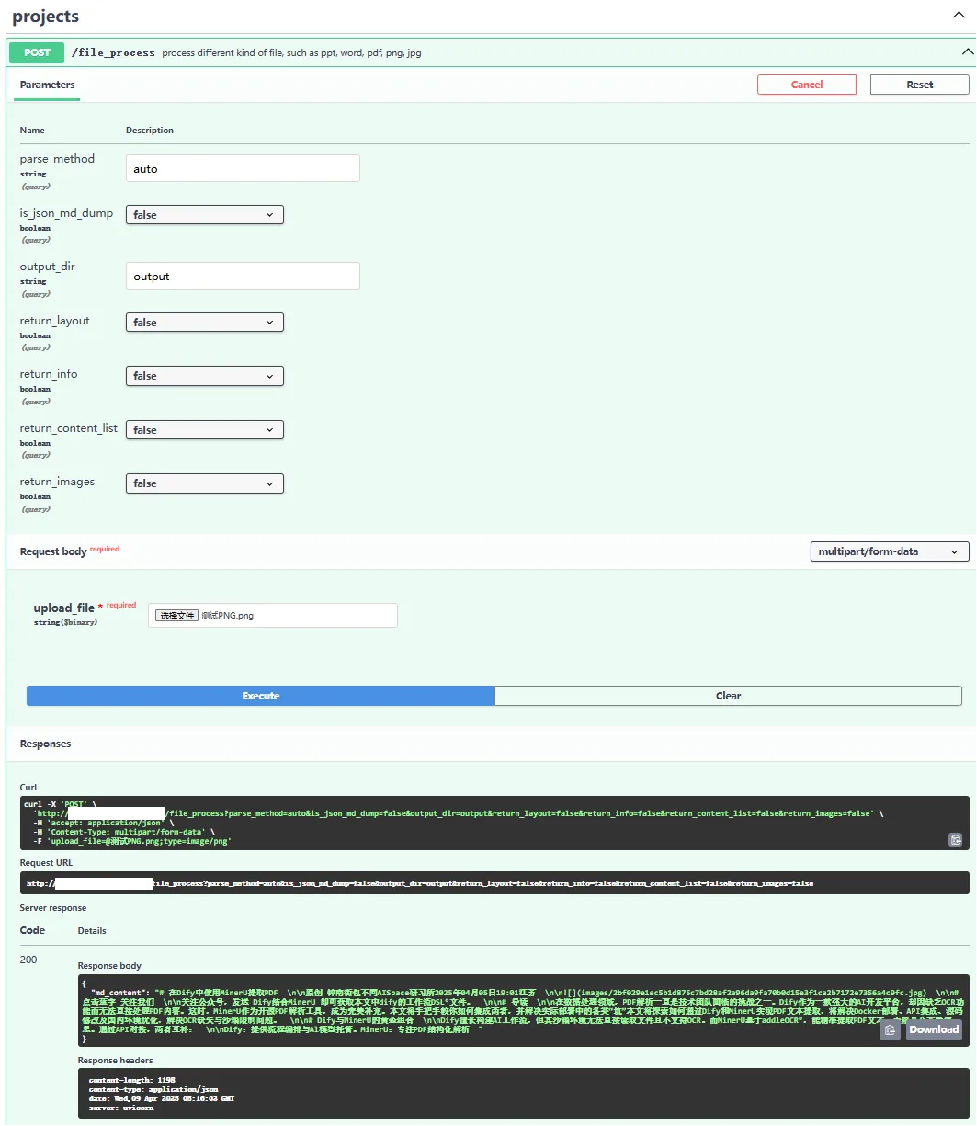
可以看到,接口成功从图片中识别出了文字,并转换成了markdown格式
Dify工作流测试
1. 先构建一个dify的对话流
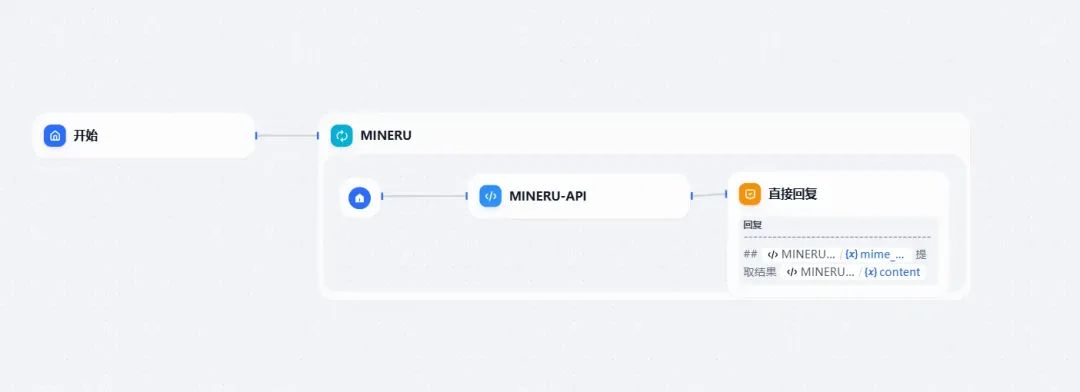
2. 分别上传带截图的PPT、WORD以及图片,测试下API的解析效果

总结
至此我们改写的MinurU-API实现了office以及图片格式文档转markdown,在结合他原生的pdf转markdown功能,基本上实现了所有常见文档格式转markdown的功能。
完
关注公众号后台发送“MINERU-API”可获取本文中所有代码及Dify的工作流DSL文件。
往/期/回/顾
