
dify→ LLM
-
定义
调用大语言模型的能力,处理用户在 “开始” 节点中输入的信息(自然语言、上传的文件或图片),给出有效的回应信息。

一、应用场景
LLM节点是Chatflow/Workflow的核心处理单元,支持以下功能:
-
意图识别:客服场景的用户问题分类 -
文本生成:文章/内容自动生成 -
内容分类:邮件自动分类(咨询/投诉/垃圾) -
文本转换:多语言翻译 -
代码生成:业务代码/测试用例编写 -
RAG:知识库问答信息重组 -
图像理解:Vision模型图像解析 -
文件分析:文档内容识别处理
二、配置示例
-
在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 + 号,添加节点并选择 LLM。
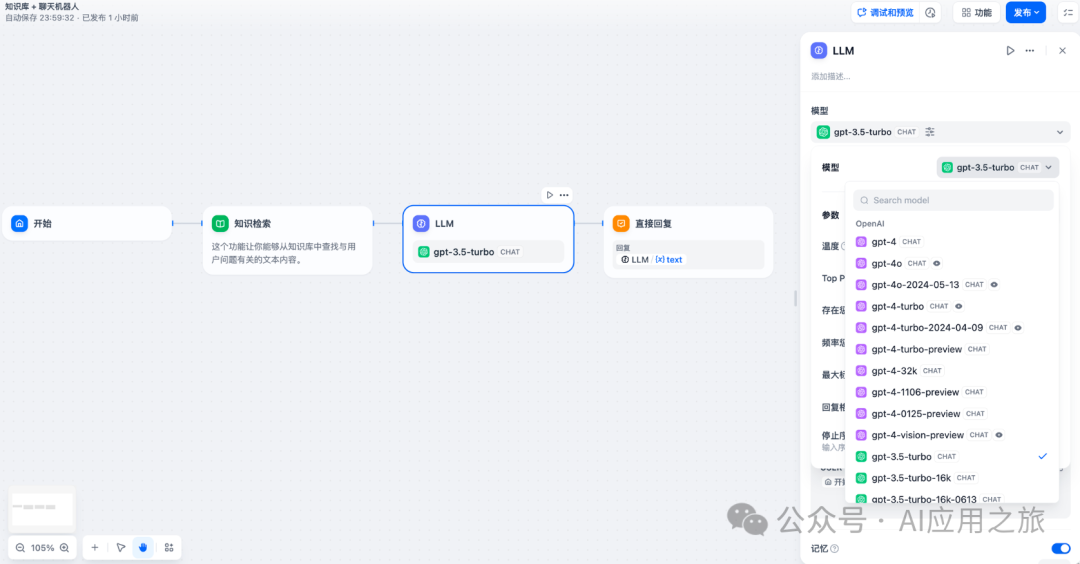
配置步骤 ?
1. 模型选择
-
支持主流模型:OpenAI GPT系列、Anthropic Claude系列、Google Gemini等 -
选择依据:推理能力/成本/响应速度/上下文窗口 -
前置条件:初次使用Dify,需在[系统设置-模型供应商]完成配置
2. 配置模型参数设置
-
预设参数模板: -
创意模式:高随机性 -
平衡模式:中等控制 -
精确模式:低随机性 -
核心参数说明: 参数 范围 作用 温度 0-1 控制输出随机性 Top P 0-1 控制候选词多样性 存在惩罚 ≥0 抑制重复内容 频率惩罚 ≥0 降低高频词出现
3. 上下文配置(可选)
-
支持知识库检索结果变量输入 -
变量类型:上下文变量/图片变量/文件变量
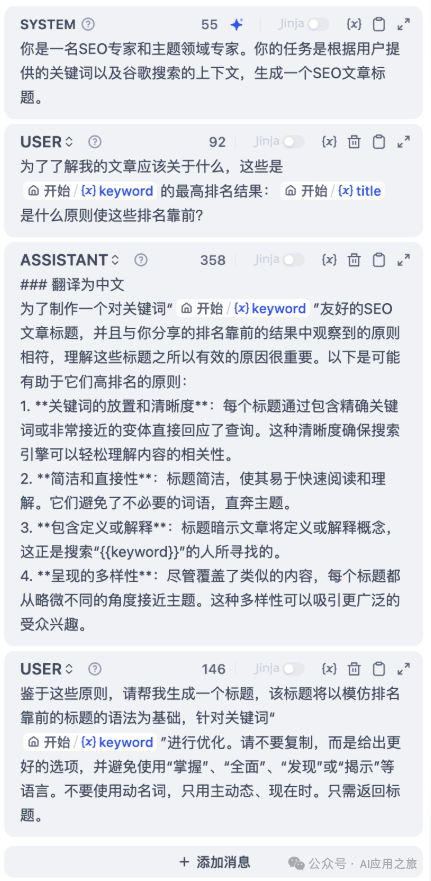
4. 提示词编排
-
聊天模型结构: -
SYSTEM:系统级指令 -
USER:用户输入模拟 -
ASSISTANT:期望响应格式 
-
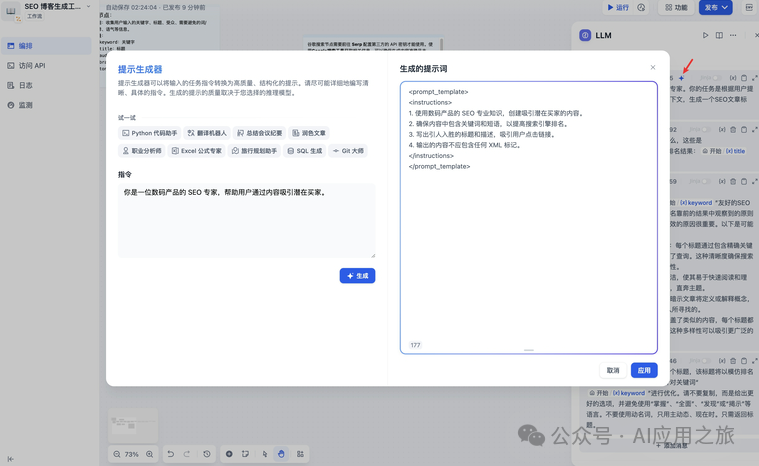
辅助工具: -
提示生成器:AI辅助生成
-
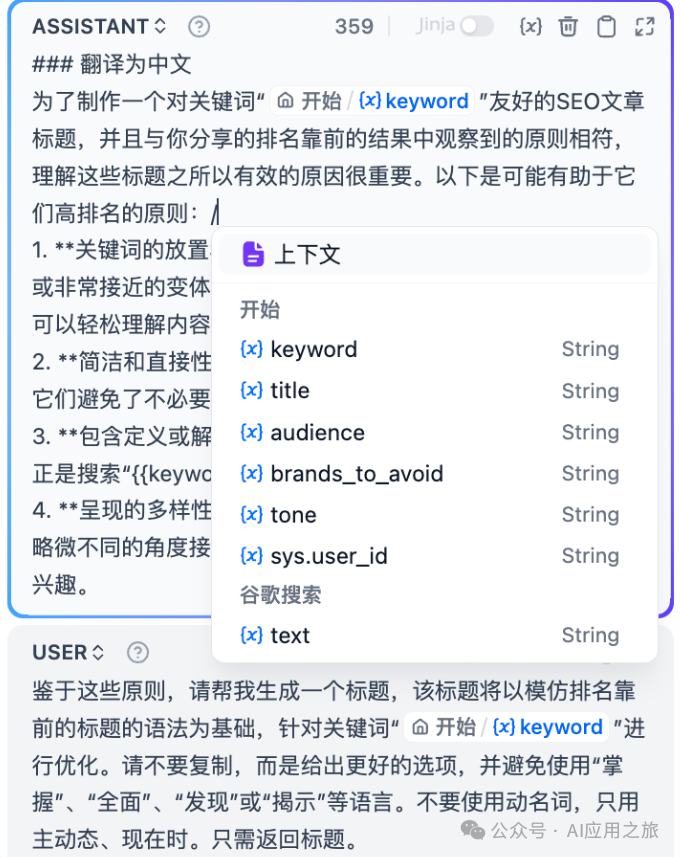
变量插入:支持 /或{呼出菜单 -
高级模板:Jinja-2语法支持
5. 高级功能
-
记忆机制: -
记忆窗口:动态/固定历史记录量 -
角色命名:自定义对话角色前缀 -
错误处理: -
自动重试:最大10次/间隔5秒 -
异常分支:错误隔离与备用流程 -
文件处理: -
Vision模型:需单独启用 -
文档解析:需连接文档提取器节点
三、特殊变量说明
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
图片变量:具备视觉能力的 LLM 可以通过变量读取应用使用者所上传的图片。开启 VISION 后,选择图片文件的输出变量完成设置。 -
文件变量:部分 LLMs(例如 Claude 3.5 Sonnet)已支持直接处理并分析文件内容,因此系统提示词已允许输入文件变量。为了避免潜在异常,应用开发者在使用该文件变量前需前往 LLM 官网确认 LLM 支持何种文件类型。
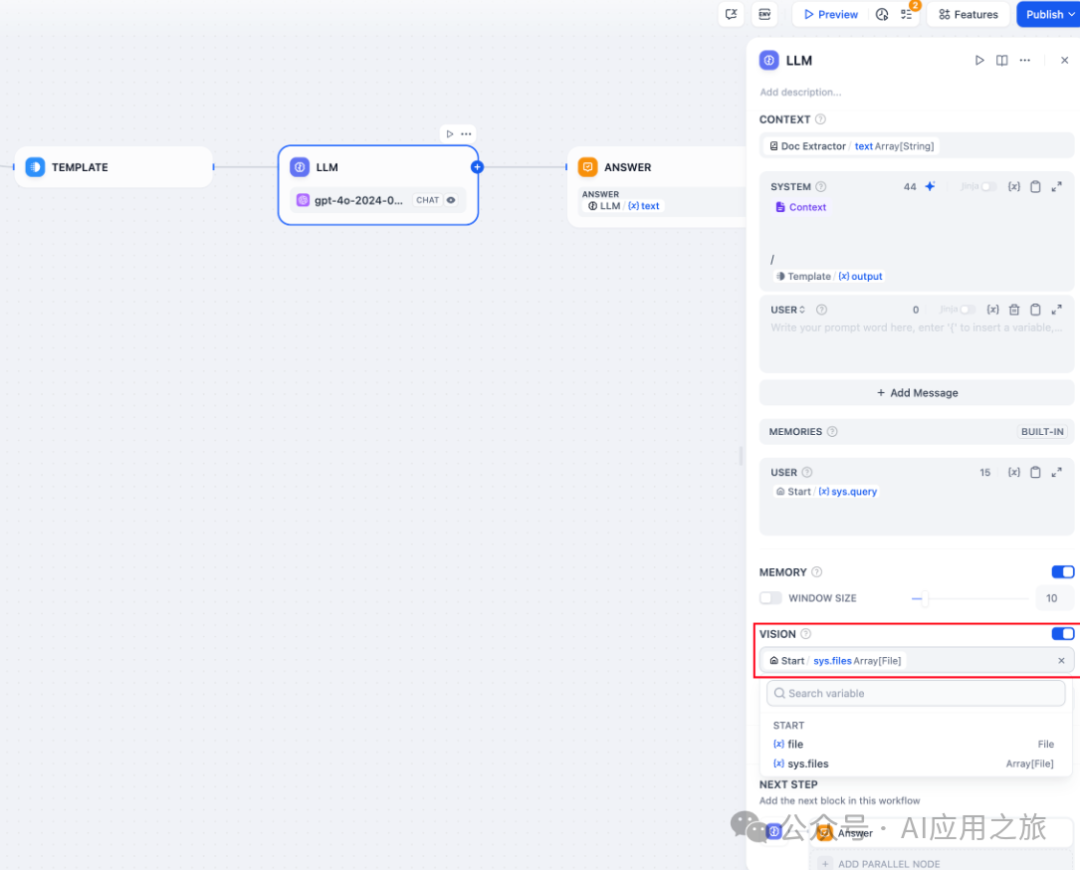
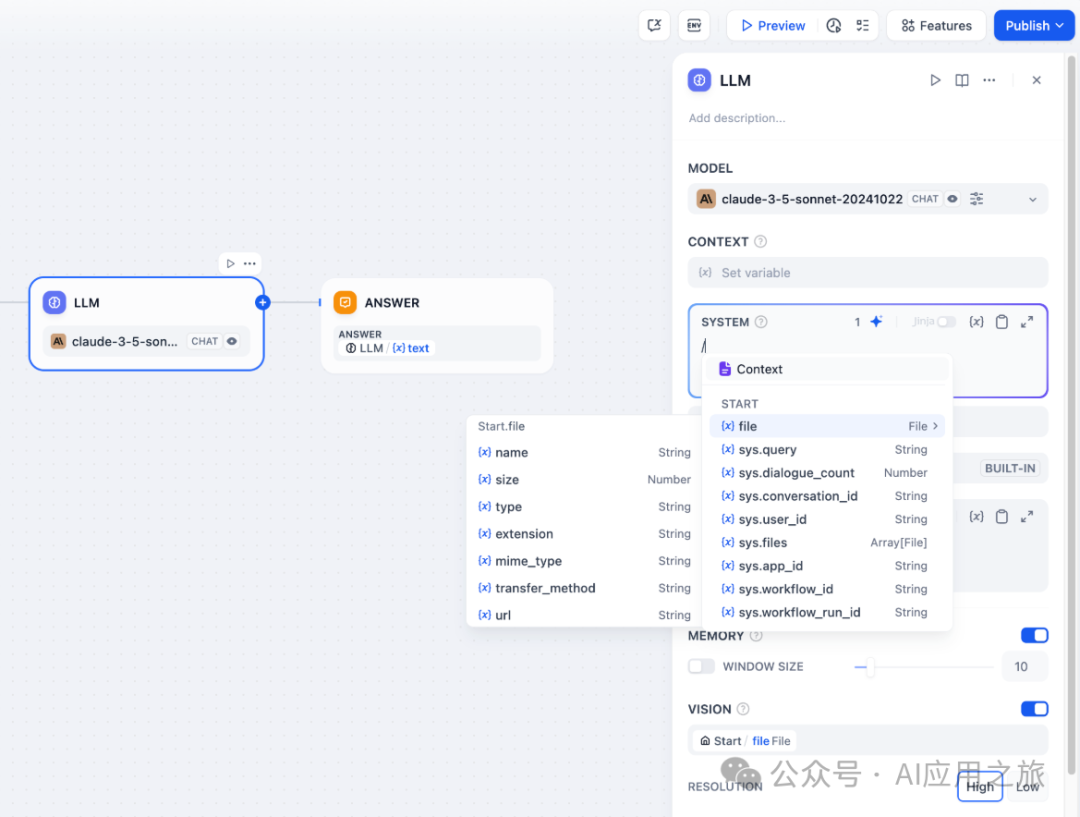
-
会话历史:为了在文本补全类模型(例如 gpt-3.5-turbo-Instruct)内实现聊天型应用的对话记忆,Dify 在原提示词专家模式(已下线)内设计了会话历史变量,该变量沿用至 Chatflow 的 LLM 节点内,用于在提示词中插入 AI 与用户之间的聊天历史,帮助 LLM 理解对话上文。
会话历史变量应用并不广泛,仅在 Chatflow 中选择文本补全类模型时可以插入使用。
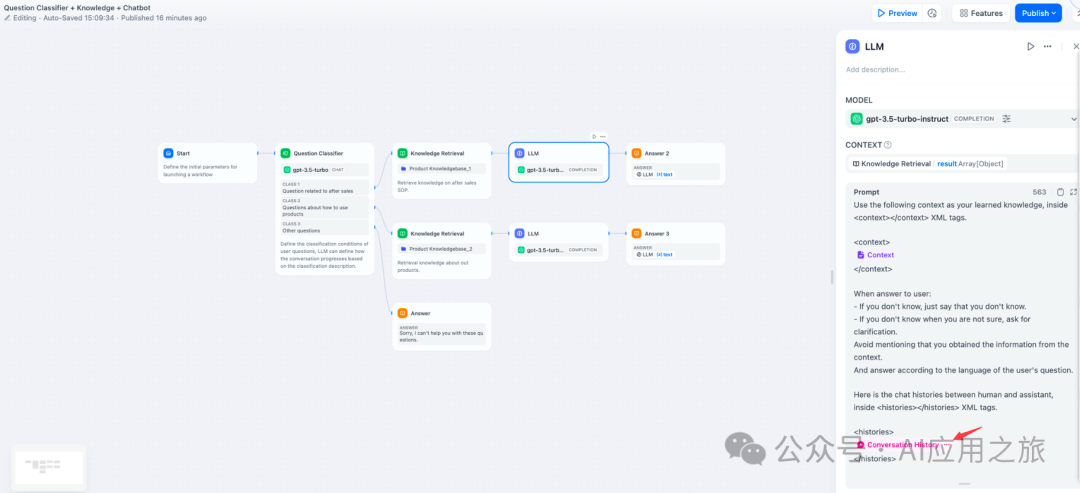
-
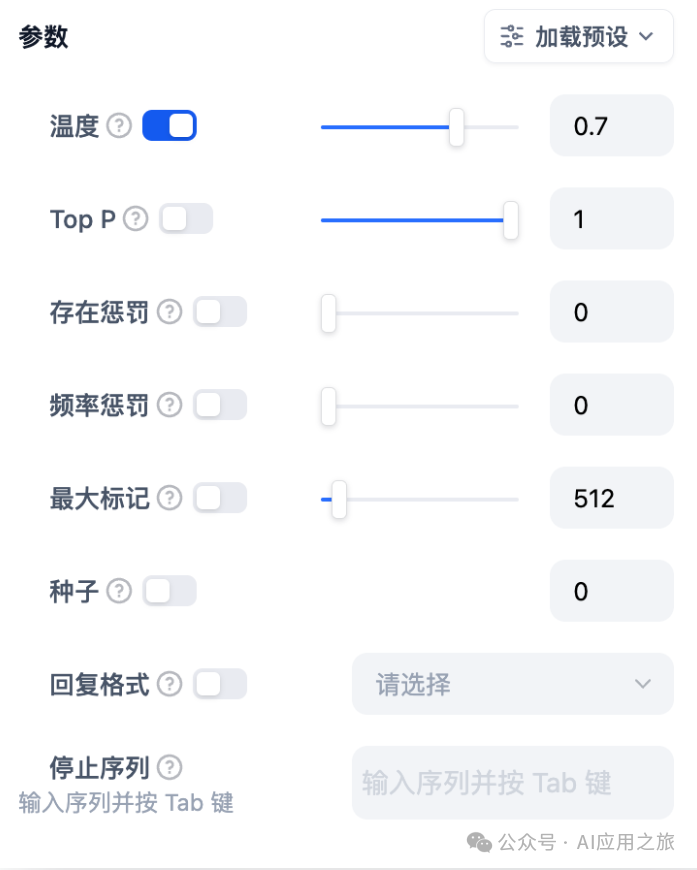
模型参数:模型的参数会影响模型的输出效果。不同模型的参数会有所区别。下图为gpt-4的参数列表
-
主要的参数名词解释如下:
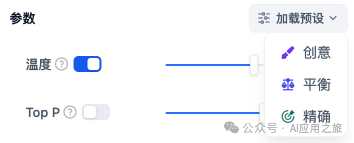
如果你不理解这些参数是什么,可以选择加载预设,从创意、平衡、精确三种预设中选择
-
温度: 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
-
Top P: 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
-
存在惩罚: 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
-
频率惩罚: 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
四、高级功能
记忆: 开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
记忆窗口: 记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。
对话角色名设置: 由于模型在训练阶段的差异,不同模型对于角色名的指令遵循程度不同,如 Human/Assistant,Human/AI,人类/助手等等。为适配多模型的提示响应效果,系统提供了对话角色名的设置,修改对话角色名将会修改会话历史的角色前缀。
Jinja-2 模板: LLM 的提示词编辑器内支持 Jinja-2 模板语言,允许你借助 Jinja2 这一强大的 Python 模板语言,实现轻量级数据转换和逻辑处理,参考官方文档。
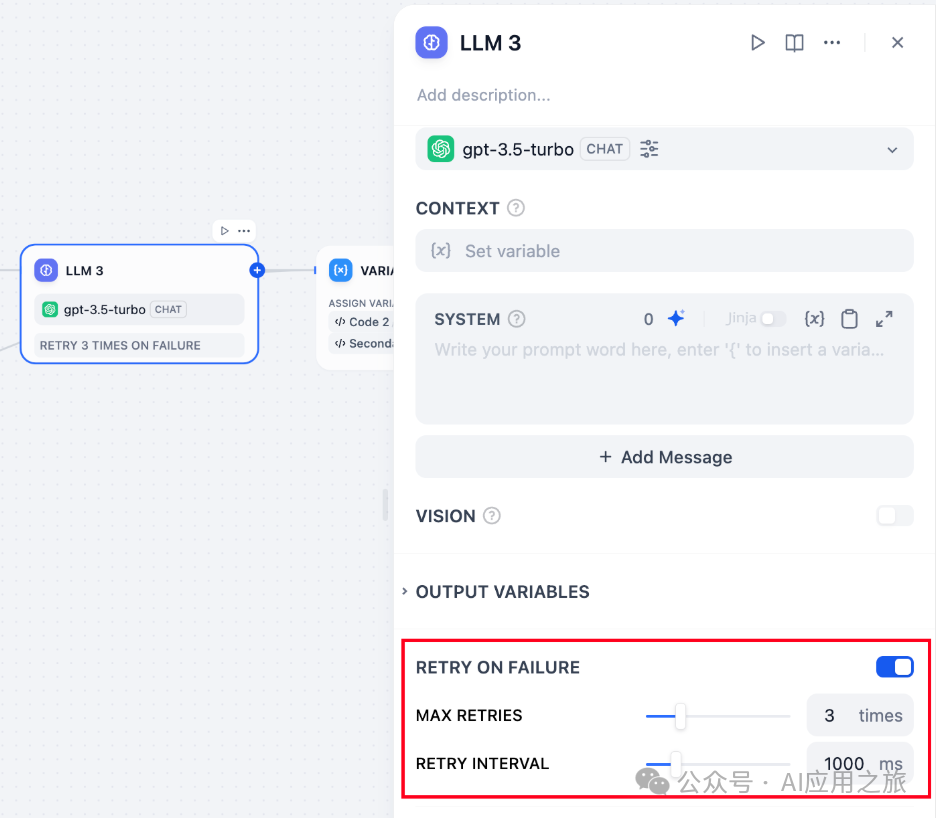
错误重试:针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
-
最大重试次数为 10 次
-
最大重试间隔时间为 5000 ms
 异常处理:提供多样化的节点错误处理策略,能够在当前节点发生错误时抛出故障信息而不中断主流程;或通过备用路径继续完成任务。详细说明请参考异常处理。
异常处理:提供多样化的节点错误处理策略,能够在当前节点发生错误时抛出故障信息而不中断主流程;或通过备用路径继续完成任务。详细说明请参考异常处理。
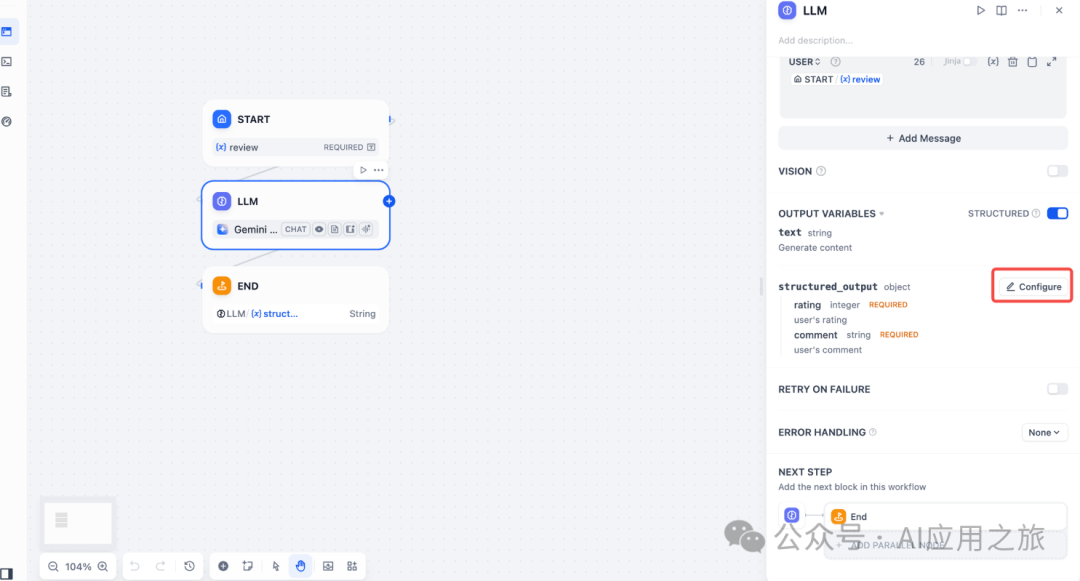
结构化输出:确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
LLM → JSON Schema 编辑器
JSON Schema 编辑器让你能够定义 LLM 返回的数据结构,确保输出可解析、可复用、可控。支持可视化编辑模式和代码编辑模式,适配不同复杂度的需求。
特性
-
节点级能力:适用于所有模型的结构化输出定义和约束 -
原生支持:结构化输出模型可直接使用 JSON Schema -
兼容模式:非结构化模型通过提示词引导输出(不保证解析成功率)
编辑器入口
路径:LLM 节点 > 输出变量 > 开启结构化开关 > 配置
支持可视化编辑窗口与代码编辑窗口无缝切换
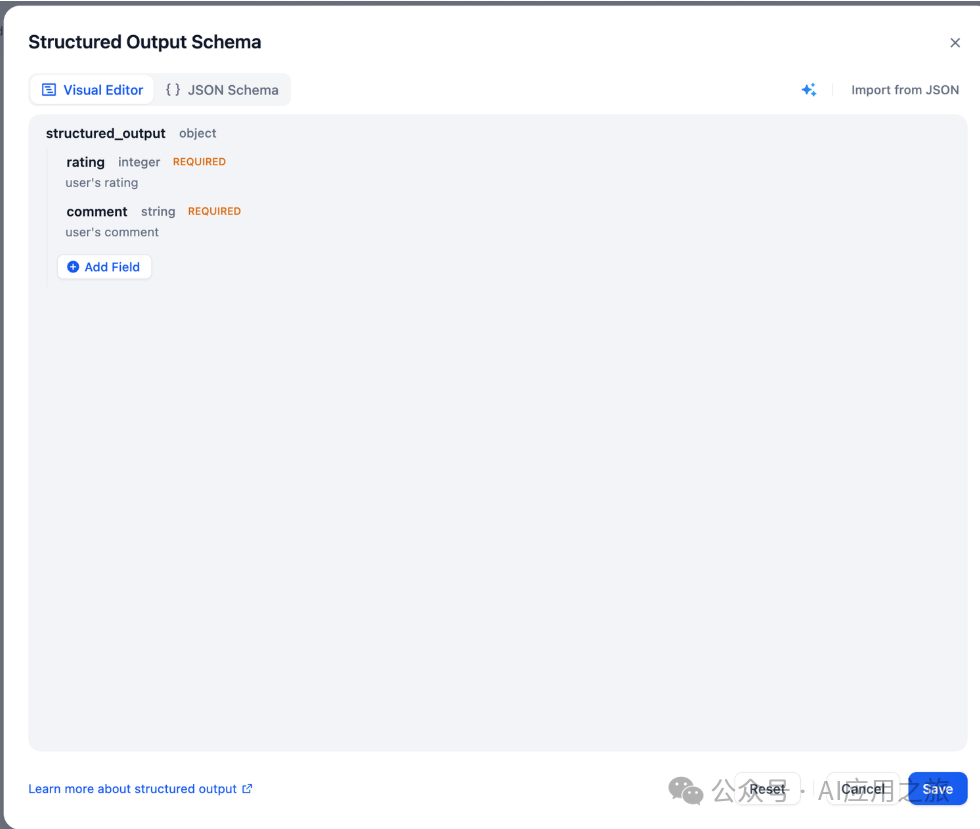
可视化编辑模式
适用场景
-
简单字段定义(如 name/email/age) -
不熟悉 JSON Schema 语法 -
需要快速迭代字段结构
操作指南
添加字段?
-
点击「添加子字段」按钮 -
配置参数: {
"type": "string",
"enum": ["red", "green", "blue"]
}
-
字段名(必填) -
字段类型:string/number/object/array 等 -
描述:帮助 LLM 理解字段含义 -
必填:强制返回该字段 -
枚举值:限制可选范围
(注:此文档基于提供的技术说明整理,实际配置请以平台最新文档为准)
