通过前面的文章,我们基本可以了解到知识库的建立和大模型使用的一些基本流程。今天分享下工作流视觉模型的一个demo,如果前面的内容了解了这里其实也很简单了
-
dify工作流的使用(二)" data-itemshowtype="0" target="_blank" linktype="text" data-linktype="2">DeepSeek+Dify工作流的使用(二) -
DeepSeek+Dify工作流的使用(一)插入代码 -
DeepSeek+Dify打造数据库查询专家修正(一) -
DeepSeek+Dify打造数据库查询专家 -
Dify个人助理本地搭建快速入门
分享个点吧(不专业
-
如果之前写过简单的123或者猫狗识别的(可以自己再网上找demo跑跑),就会有个疑惑的写的这个demo和大模型之间的区别是什么?或者一些开源的某个方面专业的模型例如那个u2net抠图的当然这个不是文本的,它应该不影响有这个疑惑吧。 -
昨天偶然看的一个关于大模型介绍的一个视频收获(纯个人理解):因为之前接触和了解的都是一些转专门的模型(也没几个),所以对大模型是有个很模糊的概念不知所云就知道参数量很大和专业的模型中间的关系是不知道的,听了之后发现其实大模型后面会有些专门的小模型再里面的会有个中间层(transformer专业名词)做一些转发进行处理的(提示词很大程度是干这个的)。
本期分享借助工作流做一个表格OCR的demo
-
之前的文章有分享过一些对特定表格处理的demo。方式这里简单说下 -
最基础的是用OPENCV定制化识别表格,但是没有直接文字识别的方法 -
还有一些专门的模型PaddleOCR、阿里读光有线和无线表格识别算法模型 -
会python/c++的可以本地试下上面说的模型。如果要自己编译通过其他方式调用是有点费劲的 -
之前写的文章:java表格识别PaddleOcr总结 -
今天分享下用大模型进行识别可以自行试下效果和关注下模型费用的问题可以做个对比(上面说的模型可以看官网有费用价格表的)。 -
差别接大模型可能API简单点吧,另外返回的识别数据专业模型可以有坐标的(也可能是我提示词的原因)。这个需要自己注意点。实际用可以根据自己的实际情况定夺,这里分享下只是说多了一种方式吧。
整体的流程概叙
简单的工作流

测试的图片
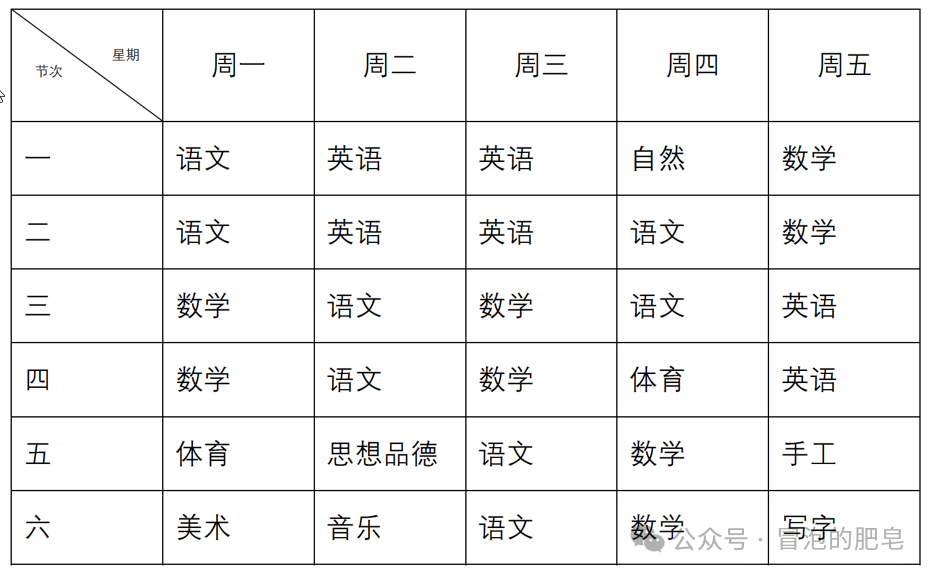
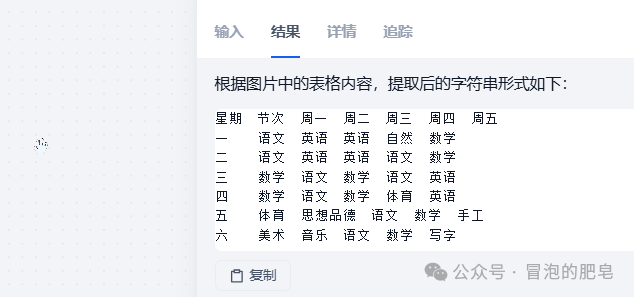
效果
注意事项
-
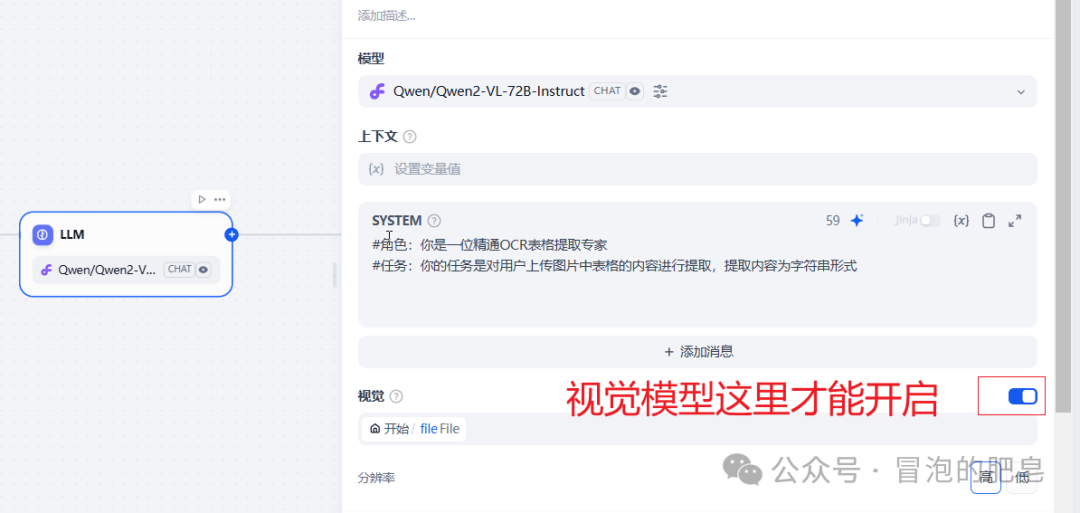
首先模型那里需要选择视觉模型才可以(不然的话其他模型会一直提示没有文件的上传的) -
写入适当的提示词
#角色:你是一位精通OCR表格提取专家
#任务:你的任务是对用户上传图片中表格的内容进行提取,提取内容为字符串形式
-
其他的跟之前介绍的工作流demo基本一样