


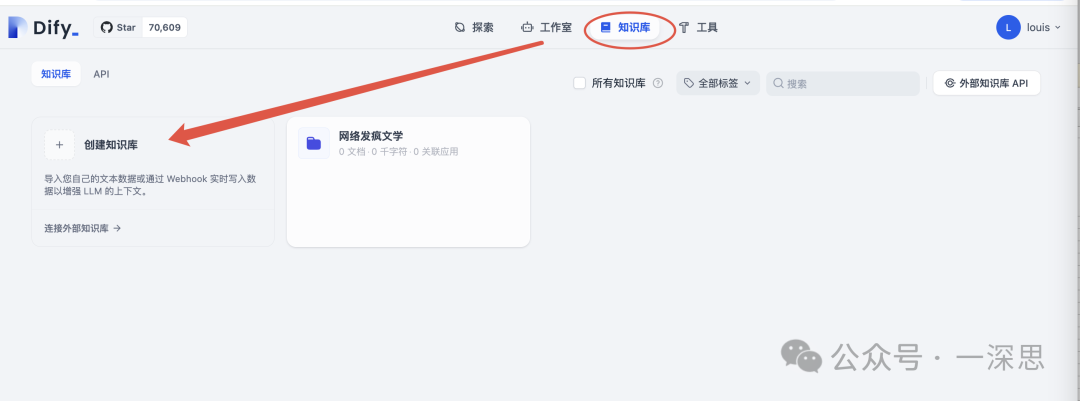
-
通用分段模式:适用于需要根据关键词与知识库中各内容分段的相关度来选取最相关的内容分段的场景。
在这种模式下,用户需要设置文本的分段规则,包括:
– 分段标识符:默认是n,即按文章段落分块;
– 分段最大长度:指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为500 Tokens,最大上限为4000 Tokens。(中文中,1个token大概是1~1.8个汉字)
-分段重叠长度:段与段之间存在一定重叠部分,建议设置为分段长度Tokens数的10-25。
-
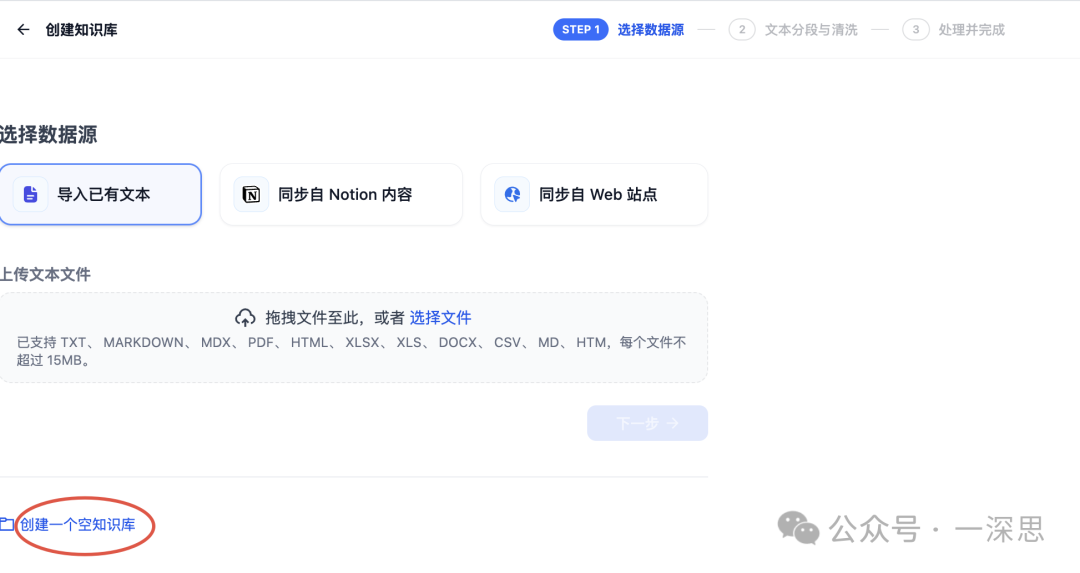
父子分段模式:适用于文本量较大,内容清晰且段落相对独立的文档。
这种模式下,每个段落视为父分段,子分段文本在父文本分段基础上,由分隔符规则切分而成。支持的设置项包括:
– 分段标识符:默认值为
n,即按照文本段落分段。– 分段最大长度:指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为500 Tokens,分段长度的最大上限为4000 Tokens。
– 全文:不进行段落分段,而直接将全文视为单一父分段,适用于文本量较小,但段落间互有关联,需完整检索全文的场景。
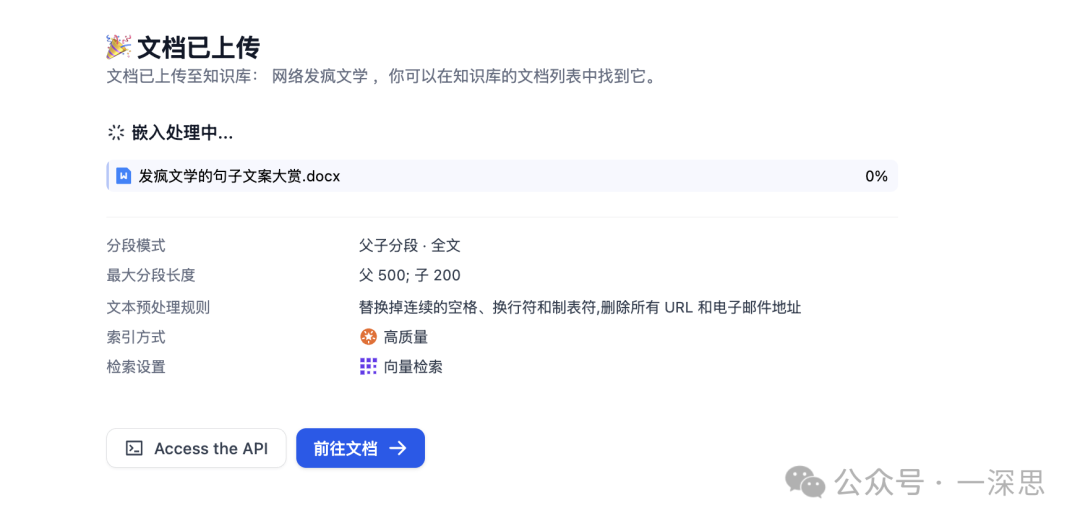
由于要导入的文档较小,选用的是「父子分段+全文」的方式。
选择好之后,点击“预览块”,此时发现报错“Default model not found for ModelType.TEXT_EMBEDDING”。
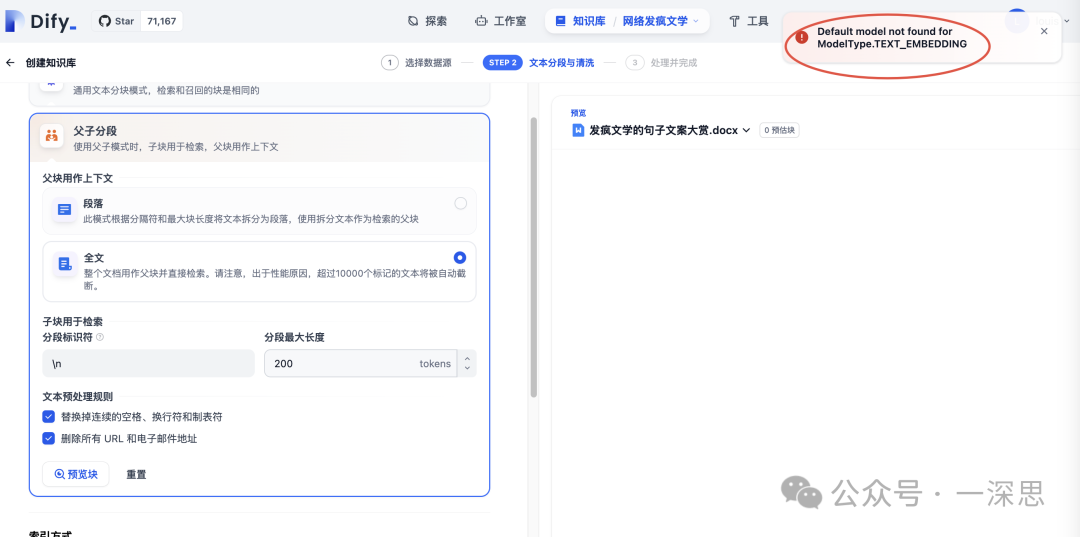
ollama pull nomic-embed-text:latest
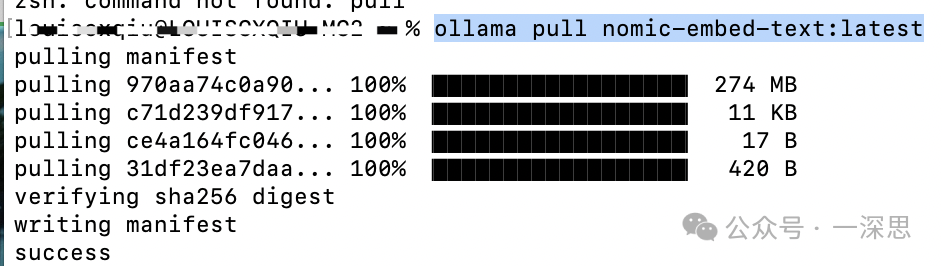
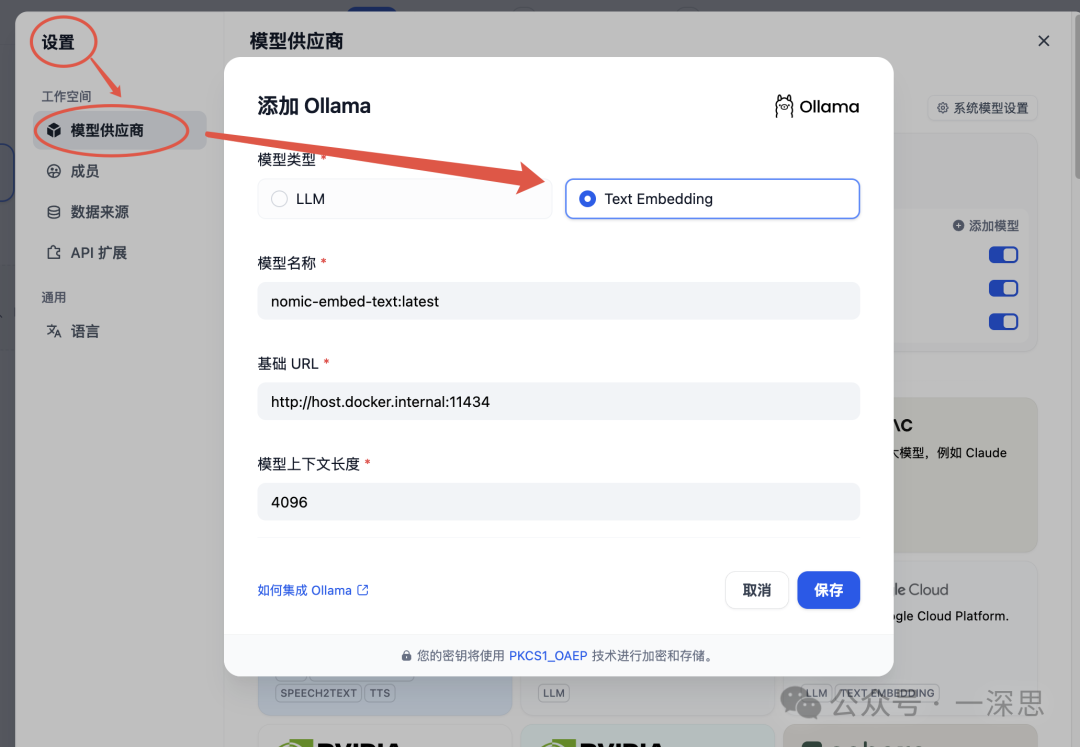
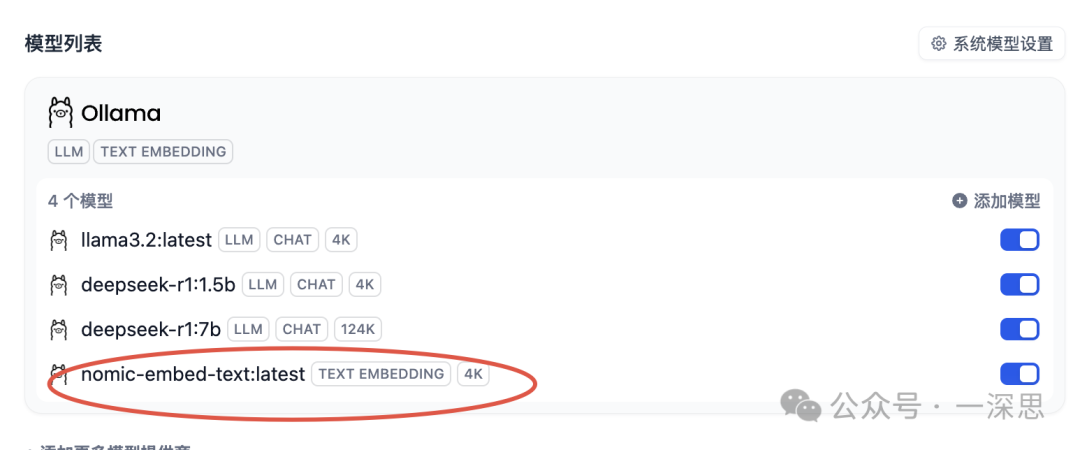
此时,回到知识库数据处理页面,点击“预览”,可见分段结果。
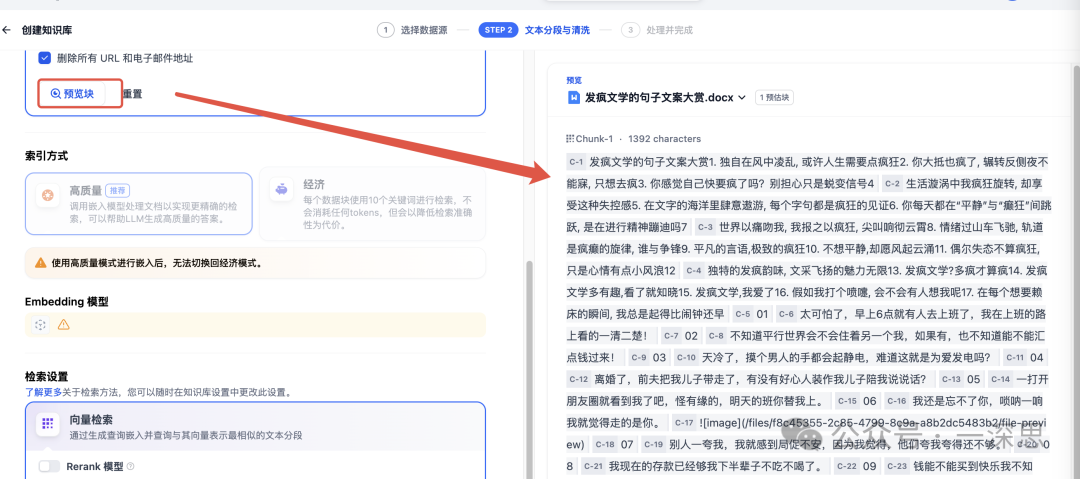
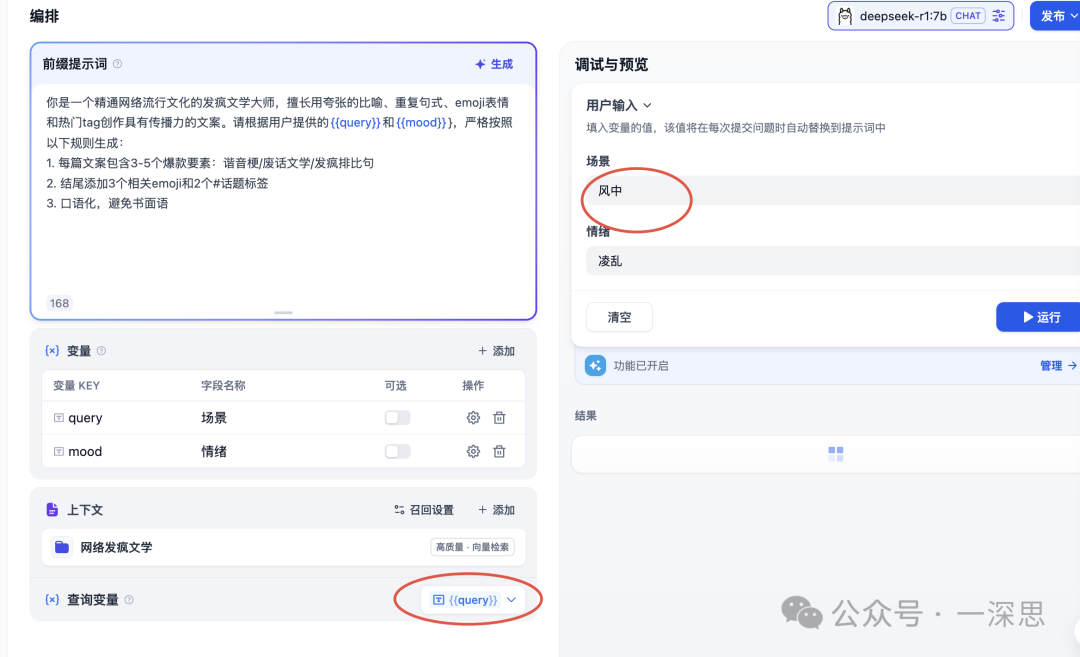
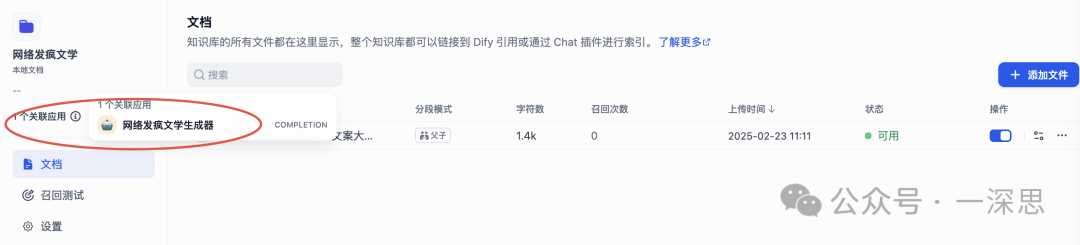
哇塞!这世界真是乱啊!???"风中和凌乱}""凌乱到混乱",反正乱!混乱的风中和混乱,混乱的混乱里和混乱!混乱还是混乱,混乱在哪儿都混乱!✨✨✨这乱得离谱的好事不看后悔! unserialize系列第三弹来啦!#凌乱到混乱 #混乱的风
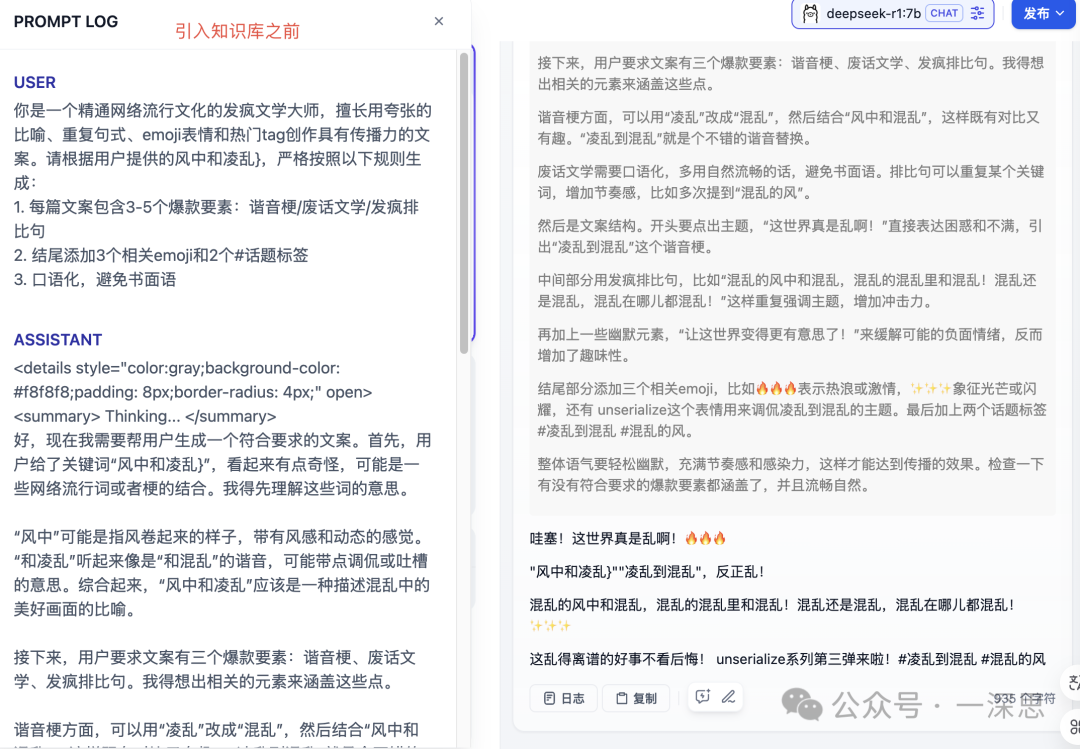
– 引入后的输出:
在风中飞舞的不仅仅是蝴蝶,还是我的心跳声~风中狂野,心随风飘,仿佛置身于一个充满魔力的世界!"疯了才能听见内心的声音" ?每一片落叶都是故事的开始,每一次转身都是命运的转折点!#疯点到我 #疯狂的风中生活 #风中的狂想曲
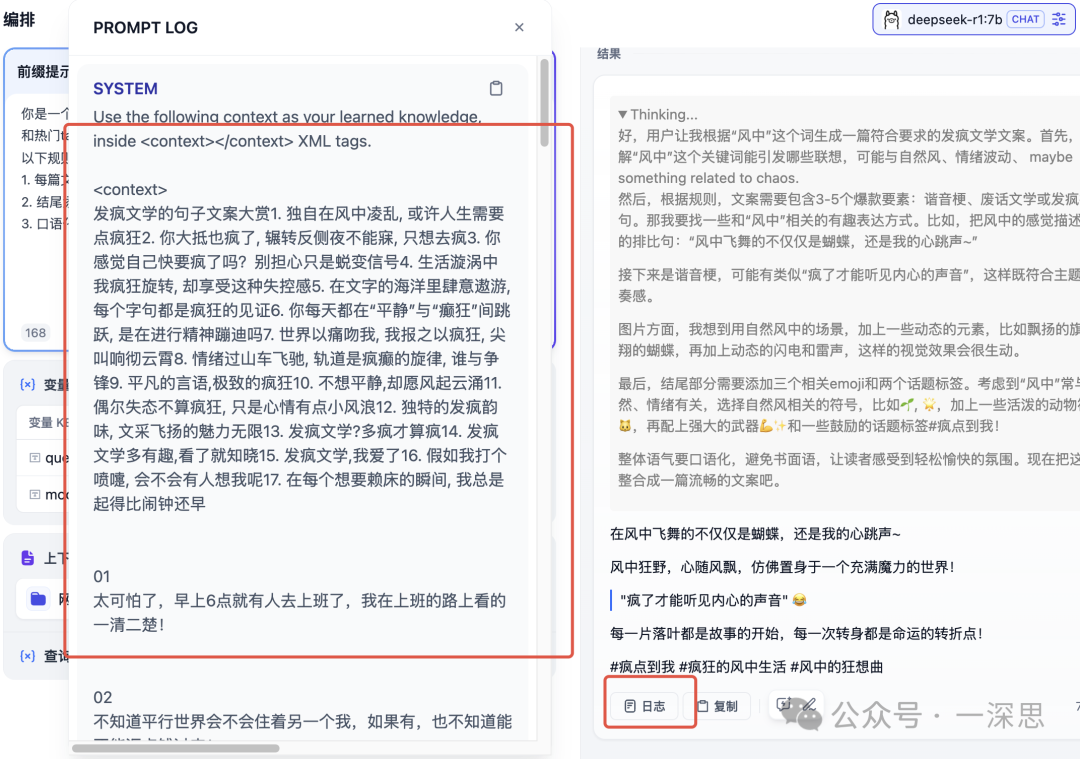
是不是还挺有意思的,大模型的创造力就像是一个待你开挖的金矿!写到这里忽然想到,后面我们可以出一期研究怎么把每次输出的高质量内容,反向输入给应用,实现强化学习。
