
 2024年6月7日 阿里发布了最新的Qwen2系列模型:
2024年6月7日 阿里发布了最新的Qwen2系列模型:
-
https://qwenlm.github.io/zh/blog/qwen2/ -
https://github.com/QwenLM/Qwen2
已在Hugging Face和ModelScope上同步开源
-
https://huggingface.co/Qwen -
https://modelscope.cn/organization/qwen
Introduction
-
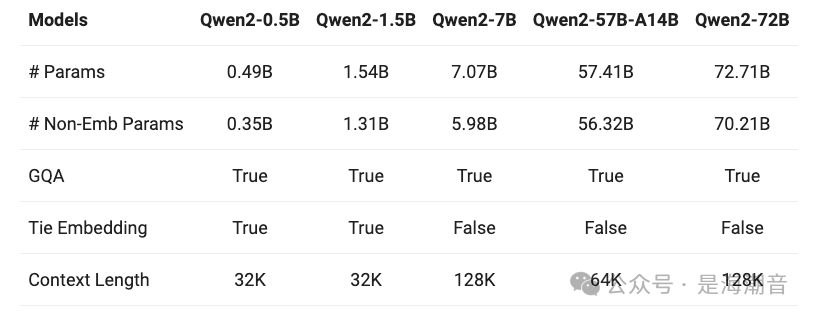
发布了5种尺寸的预训练及微调模型,Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, and Qwen2-72B;
-
在中英文的基础上,训练数据中增加了27种语言的数据
-
在多个评测基准上表现优异
-
在代码和数学能力上显著提升
-
上下文长度扩展到128K tokens(Qwen2-72B-Instruct),其他版本的上下文 Stable support of 32K
-
Supporting tool use, RAG, role play, and playing as AI agent;
Model Information
❝
It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, etc.Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
-
在Qwen1.5系列中,只有32B和110B的模型使用了GQA。而Qwen2 所有尺寸的模型都使用了GQA
-
提高预测速度、减小显存占用(分组查询注意力 (Grouped Query Attention) 是一种在大型语言模型中的多查询注意力 (MQA) 和多头注意力 (MHA) 之间进行插值的方法,它的目标是在保持 MQA 速度的同时实现 MHA 的质量 -
针对小模型,由于embedding参数量较大,我们使用了tie embedding的方法让输入和输出层共享参数,增加非embedding参数的占比。
-
Embedding 层在NLP模型中占用了大量参数,尤其是当词汇量很大时,稀疏Embedding向量会占用大量的内存和计算资源。通过一些技术,可以优化Embedding层的参数量和计算效率。以下是一些方法来处理大型稀疏嵌入: -
more:https://kexue.fm/archives/9698 -
Using the Output Embedding to Improve Language Models https://arxiv.org/pdf/1608.05859
-
矩阵分解(Factorized)技术将嵌入矩阵分解成两个更小的矩阵,从而减少参数量和计算开销。
-
产品量化(Product Quantization, PQ)是一种用于减少嵌入维度的技术,将嵌入向量分割成若干子空间,每个子空间进行独立量化。
-
稀疏嵌入(Sparse Embeddings),利用稀疏性技术,可以只更新和存储模型中使用到的嵌入,从而节省内存
-
共享嵌入(Tied Embeddings),通过在不同层之间共享相同的嵌入矩阵来减少参数量。在 Transformer 模型中,通常将输入嵌入层和输出嵌入层共享参数。
-
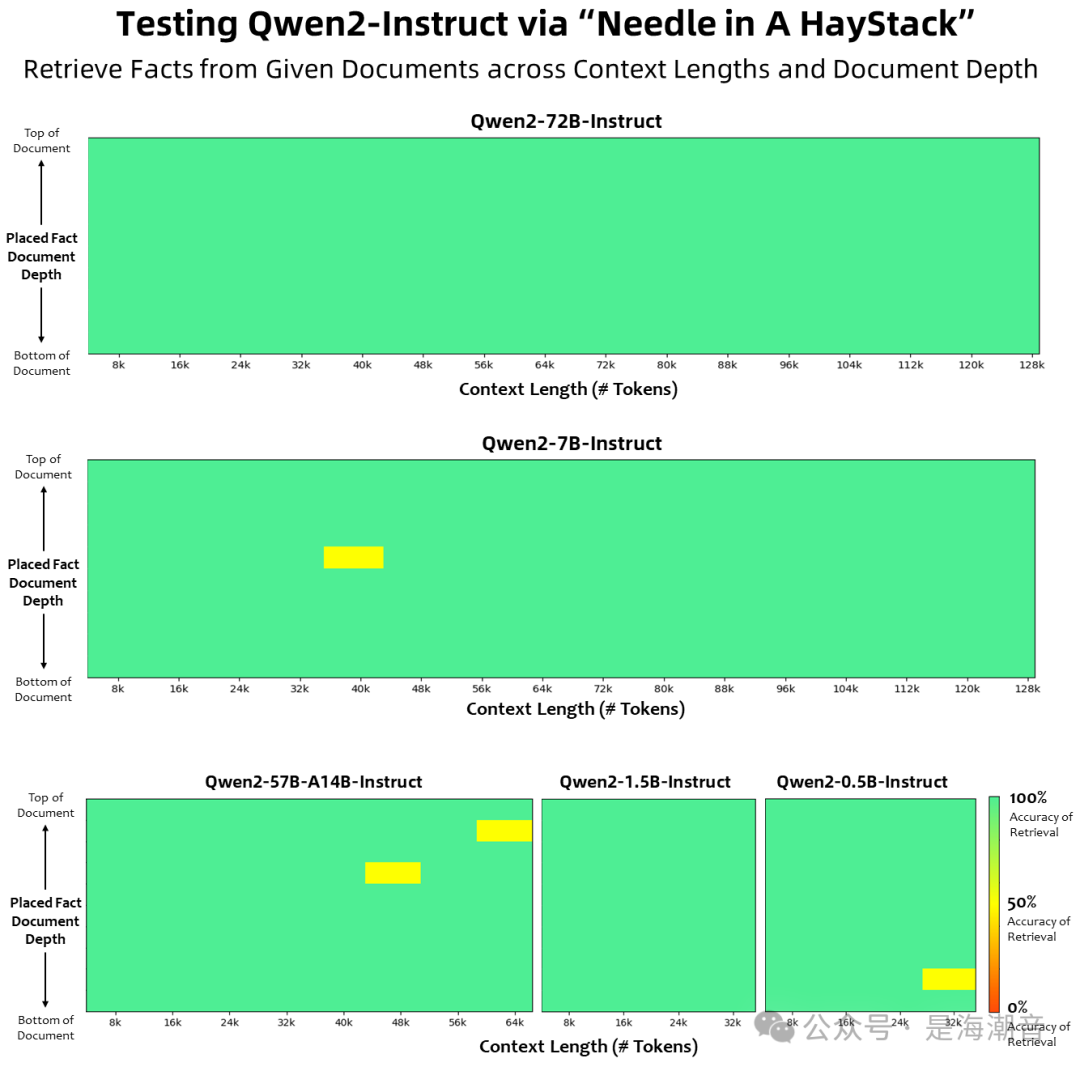
所有的预训练模型均在32k上下文预料上做预训练,且我们发现其在128K tokens时依然能在PPL评测中取得不错的表现。
-
Qwen2-7B-Instruct模型通过YARN外推(或者Dual Chunk Attention)展示了处理上下文长度长达128K令牌的令人印象深刻的能力。 -
旋转位置编码(RoPE)已被证明可以有效地在基于Transformer的语言模型中编码位置信息。然而,这些模型在超过它们训练的序列长度后无法推广。我们提出了YaRN(另一种RoPE扩展方法),这是一种计算高效的方法,可以扩展此类模型的上下文窗口,所需token减少10倍,训练步骤减少2.5倍。使用YaRN,我们展示了LLaMA模型可以有效地利用和推断出比其原始预训练允许的上下文长度长得多的上下文长度,并且在上下文窗口扩展中达到了SOTA。此外,我们证明YaRN表现出了超越微调数据集有限上下文的能力。 -
论文:YaRN: Efficient Context Window Extension of Large Language Models -
地址:https://arxiv.org/abs/2309.00071 -
代码:https://github.com/jquesnelle/yarn -
对除中英文以外的27种语言进行了增强
-
模型使用了一种改进的分词器,它不仅适用于多种自然语言,还能处理代码。在自然语言处理和编程语言处理中,分词器用于将文本分解成更小的单位(如词、字符或其他符号),这是理解和处理文本的基础步骤。

-
针对性地优化了多语言场景中常见的语言转换(code switch)问题,模型当前发生语言转换的概率大幅度降低。我们使用容易触发语言转换现象的提示词进行测试,观察到Qwen2系列模型在此方面能力的显著提升。 -
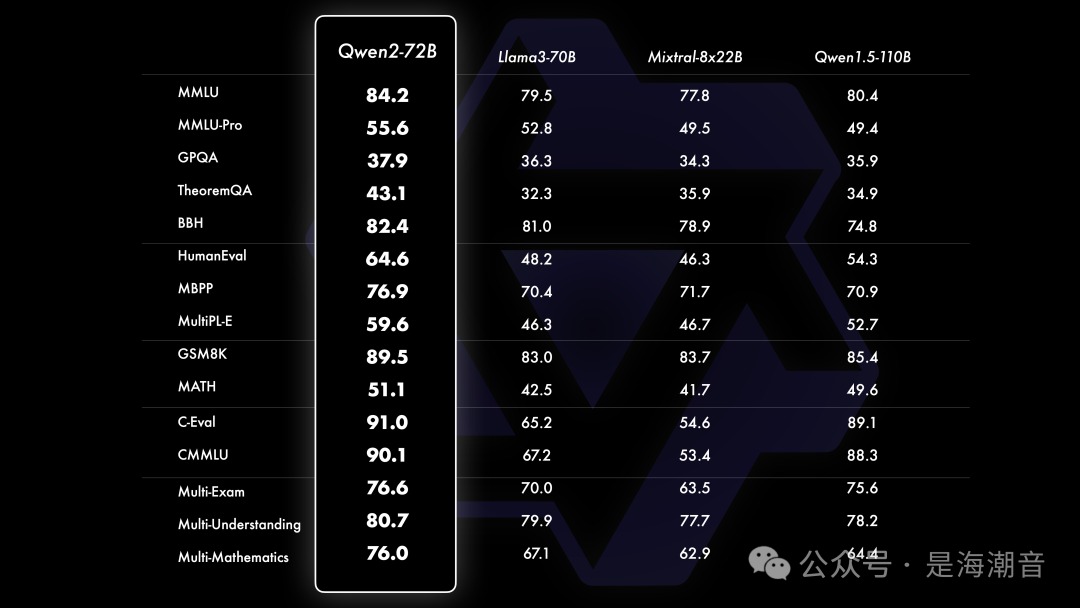
相比Qwen1.5,Qwen2在大规模模型实现了非常大幅度的效果提升
-
对比当前最优的开源模型,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的模型,如Llama-3-70B以及Qwen1.5最大的模型Qwen1.5-110B。这得益于其预训练数据及训练方法的优化。
-
大规模预训练后,我们对模型进行精细的微调,以提升其智能水平,让其表现更接近人类。这个过程进一步提升了代码、数学、推理、指令遵循、多语言理解等能力。此外,模型学会对齐人类价值观,它也随之变得更加对人类有帮助、诚实以及安全。我们的微调过程遵循的原则是使训练尽可能规模化的同时并且尽可能减少人工标注。
-
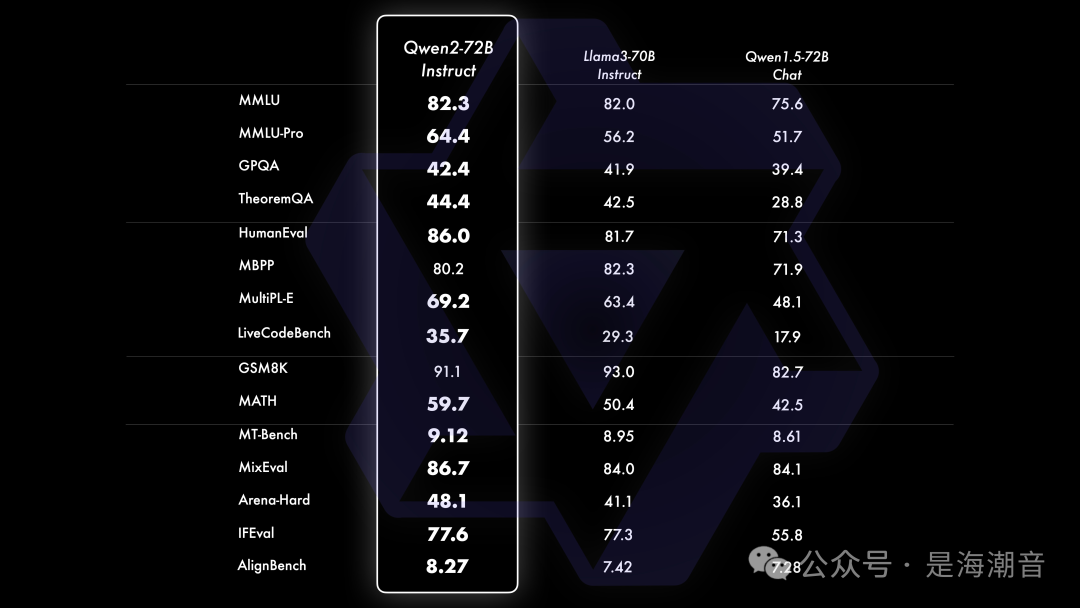
小模型方面,Qwen2系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型。相比近期推出的最好的模型,Qwen2-7B-Instruct依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。 -
Qwen2系列中的所有Instruct模型,均在32k上下文长度上进行训练,并通过YARN或Dual Chunk Attention等技术扩展至更长的上下文长度。
-
Qwen2-72B-Instruct能够完美处理128k上下文长度内的信息抽取任务。结合其本身强大的性能,只要有充足的算力,它一定能成为你处理长文本任务的首选!
-
除了长上下文模型,我们还开源了一个智能体解决方案,用于高效处理100万tokens级别的上下文。https://qwenlm.github.io/blog/qwen-agent-2405/
-
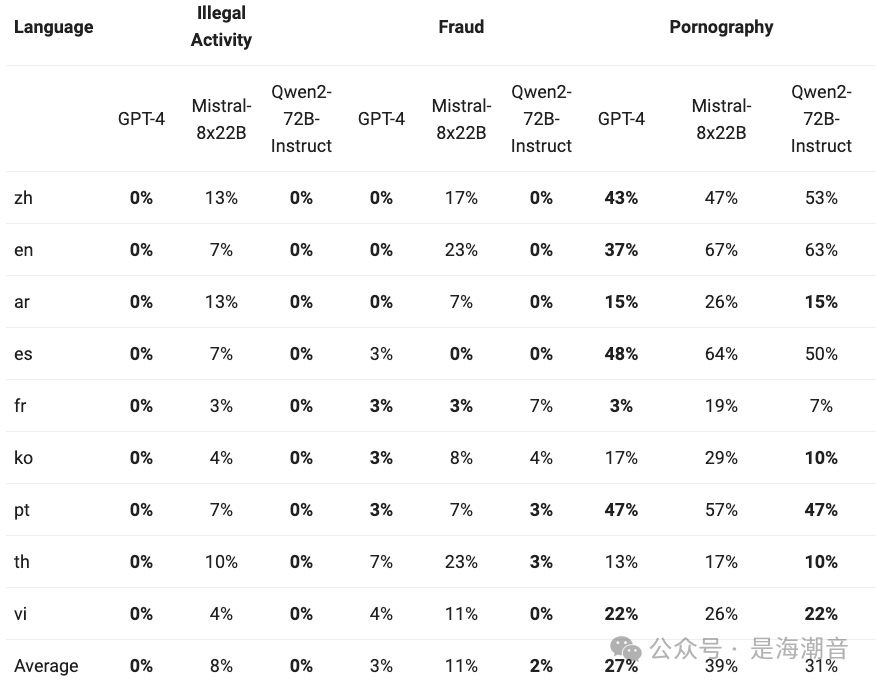
在四种多语言不安全查询类别(非法活动、欺诈、色情、隐私暴力)中生成有害响应的比例。测试数据来源于Jailbreak,并被翻译成多种语言进行评估。 -
包括微调(Axolotl、Llama-Factory、Firefly、Swift、XTuner) -
量化(AutoGPTQ、AutoAWQ、Neural Compressor) -
部署(vLLM、SGL、SkyPilot、TensorRT-LLM、OpenVino、TGI) -
本地运行(MLX、Llama.cpp、Ollama、LM Studio) -
Agent及RAG(检索增强生成)框架(LlamaIndex, CrewAI, OpenDevin) -
评测(LMSys, OpenCompass, Open LLM Leaderboard)、 -
模型二次开发(Dolphin, Openbuddy)
Performance
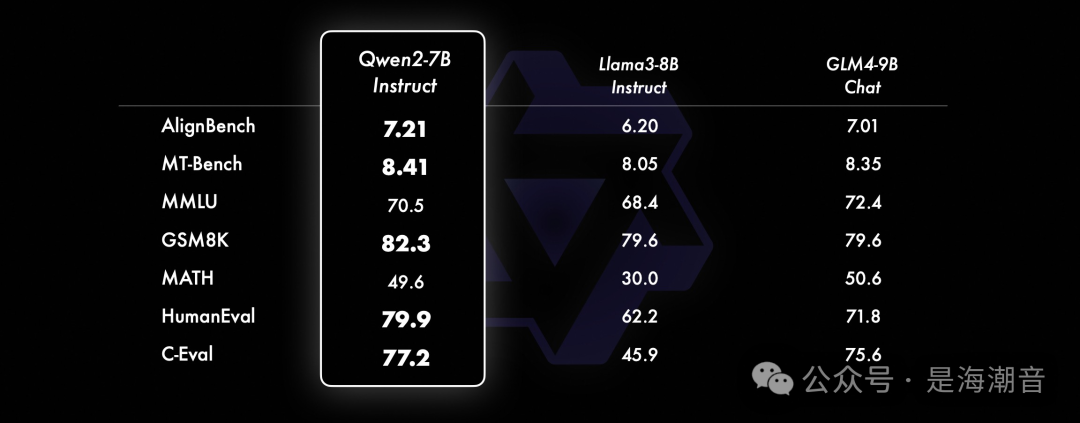
Highlights
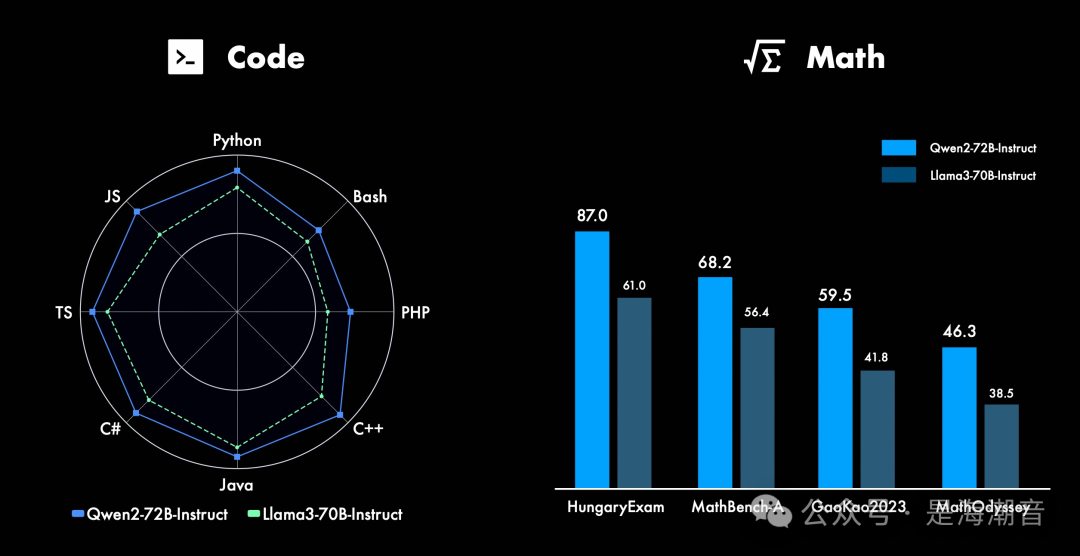
Coding & Mathematics
在代码方面,我们成功将CodeQwen1.5的成功经验融入Qwen2的研发中,实现了在多种编程语言上的显著效果提升。而在数学方面,大规模且高质量的数据帮助Qwen2-72B-Instruct实现了数学解题能力的飞升。
Long Context Understanding
Safety and Responsibility
Developing with Qwen2

What’s Next for Qwen2?
还在训练更大的模型,继续探索模型及数据的Scaling Law。此外,我们还将把Qwen2扩展成多模态模型,融入视觉及语音的理解。在不久的将来,我们还会继续开源新模型。 不久后我们将推出Qwen2的技术报告
